流式数据开发
业务场景
使用流式数据加工作业,实时统计用户对网站各模块的点击次数,便于后续实时精准营销。
前提条件
- 平台部署完成,产品规格包含流式数据加工模块,且服务正常
- 用户拥有流式数据加工模块权限
使用限制
- 当前兼容flink 1.20版本语法
- 目标限制:目标表当前不支持外部数据源,如若需要可通过jar包模式实现
操作流程
- 第一步:创建topic
进入数据开发 > 实时数据 > 数据信道管理页面,完成“新建Topic”,请根据实际情况选择使用单消息类型或多消息类型。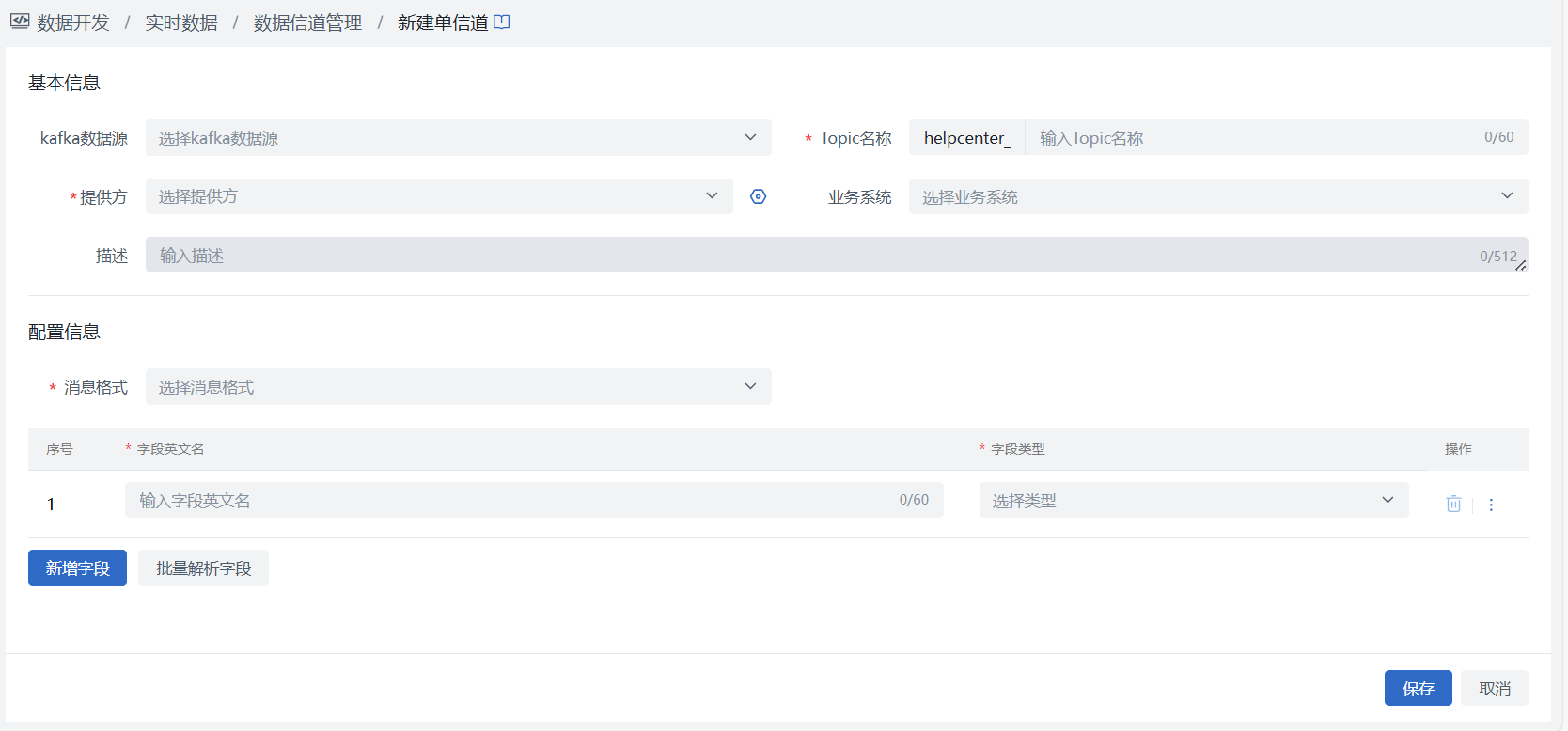
说明:Topic中数据可以来源于平台已注册Kafka数据源,或外部SDK,具体配置参照:信道作业最佳实践。
第二步:创建流式数据加工作业
选择数据开发 > 实时数据 > 流式数据加工,可根据需要在页面左侧分组树中新建分组,以便对作业进行分类管理。在页面列表左上角点击“新建流式数据加工”按钮,进入作业新建页面,按照页面信息项进行填写配置,保存后生效,详细配置可在流式数据加工中查看。
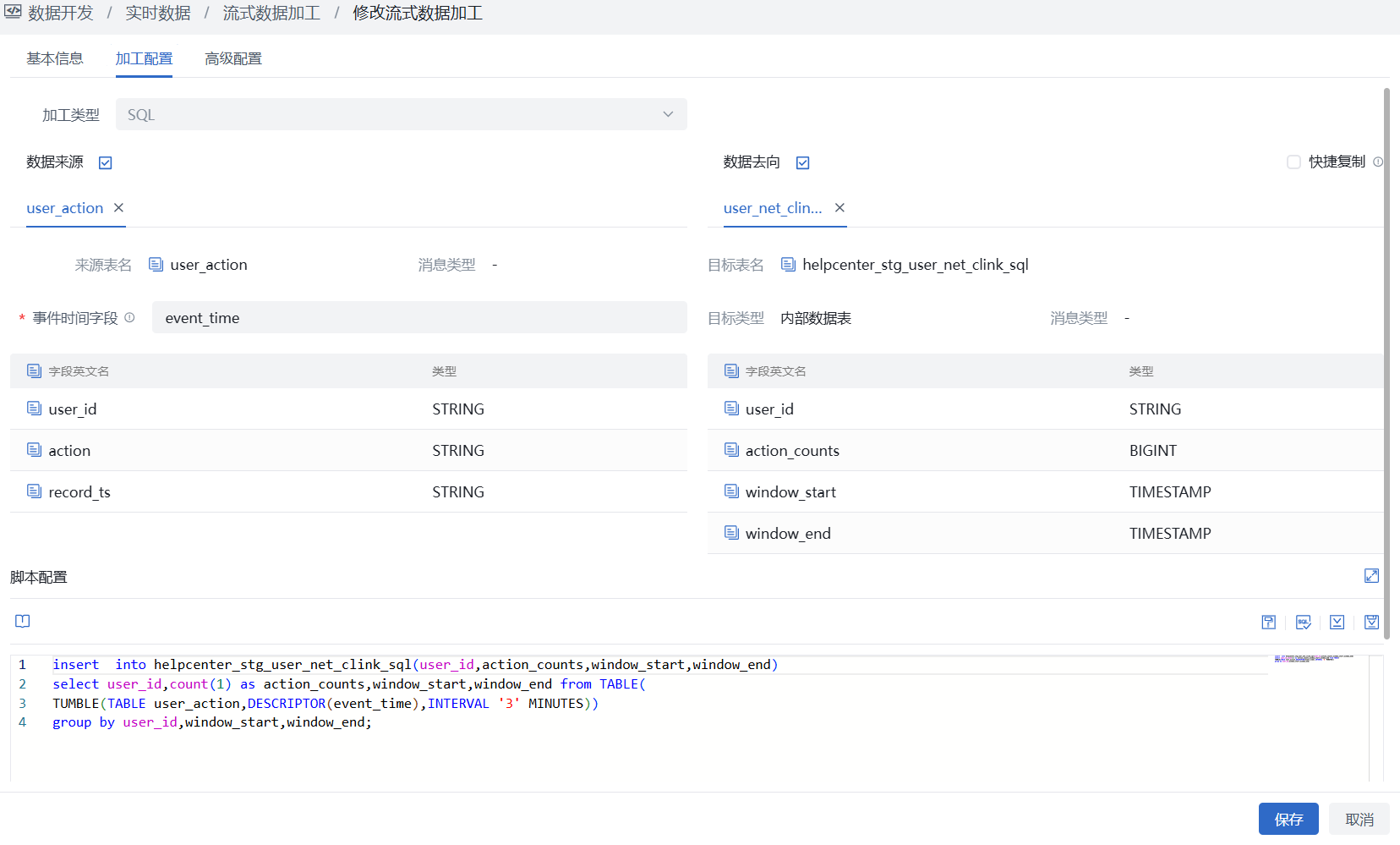
SQL模式
SQL模式中SQL语句中须使用来源、目标声明表中的表名、字段名编写加工语句,无需再声明来源与目标表连接信息,本实践中示例如下:
- SQL语句仅仅支持insert 增量数据,SQL语句基于flink 1.20 进行语法校验
- 涉及窗口聚合请指定事件时间,如果topic有多个分区,水位线需要等待所有的分区都到达才会触发窗口关闭,务必确认分区,如果多分区,有分区没有数据,那么请使用JAR模式自定义实现
- SQL语法目前支持比较函数,字符串函数,逻辑函数,算术函数,时间函数,条件函数,类型转换函数,窗口函数,如需了解更多,请自行查看官网 https://nightlies.apache.org/flink/flink-docs-lts/
- 当前topic数据格式仅支持json
- 若来源、目标表中表名、字段名存在特殊字符,在编写SQL时需使用单引号引用,如`@name`
- 来源为多消息类型时,在编写SQL时需使用“消息类型key”进行数据过滤,格式为: where “消息类型key” = 消息类型名称,如下方示例中 where bear_key = 'A1';
- 若SQL语句中包含“count”函数,目标表为内部数据表时,对应存储count值字段类型须为int8
多消息类型数据过滤示例
insert into
a_bear_stg_bear_a (id, name, age, `time`)
select
id,
name,
age,
`time`
from
bear_mutilt_A
where
bear_key = 'A1';
单消息类型窗口函数示例
helpcenter_stg_user_net_clink_sql(user_id,action_counts,window_start,window_end)
select user_id,count(1) as action_counts,window_start,window_end from TABLE(
TUMBLE(TABLE user_action,DESCRIPTOR(event_time),INTERVAL '3' MINUTES))
group by user_id,window_start,window_end;
JAR模式
JAR模式可自定义jar包内容,灵活性更高,可包括前置依赖、来源目标定义、加工逻辑、窗口函数等内容,示例如下:
- 依赖配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>demo-arguments</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.20.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.20.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.3.0-1.20</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.2.0-1.19</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.15.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>2.15.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- Replace this with the main class of your job -->
<mainClass>com.xzq.demo.KafkaToPgAggregator</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 需在配置文件中指定mainclass地址,修改依赖配置

- 编写Jar内容
package com.xzq.demo;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.ExternalizedCheckpointRetention;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.execution.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.io.Serializable;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.Map;
import java.util.Properties;
public class KafkaToPgAggregator {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. Checkpoint 配置(At-Least-Once 语义) 3分钟 Checkpoint
env.enableCheckpointing(3 * 60 * 1000, CheckpointingMode.AT_LEAST_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10 * 60 * 1000);
env.getCheckpointConfig().setExternalizedCheckpointRetention(ExternalizedCheckpointRetention.RETAIN_ON_CANCELLATION);
env.setParallelism(1);
// 定义事件时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 3. Kafka 数据源配置
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "172.*.*.119:3**4");
kafkaProps.setProperty("group.id", "user_action");
KafkaSource<String> source = KafkaSource.<String>builder().setTopics("user_action")
.setStartingOffsets(OffsetsInitializer.latest())
.setProperties(kafkaProps).setValueOnlyDeserializer(new SimpleStringSchema()).build();
// 4. 读取 Kafka 数据
DataStreamSource<String> streamSource = env.fromSource(source, WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(5)),
"Kafka Source");
// 5. 数据转换与窗口聚合
DataStream<AggResult> aggregatedStream = streamSource
// 数据处理
.map(json -> {
// 假设 Kafka 消息是 JSON 格式,包含 user_id 和 action 字段
// 示例:{"user_id": "U001", "action": "click"}
Map<String, Object> map = ObjectMapperUtil.jsonToMap(json);
return new EventData( map.containsKey("user_id") ? map.get("user_id").toString() : "UNKNOWN",
parseEventTime(json));
})
.returns(Types.POJO(EventData.class))
// 设置水印策略及事件时间
.assignTimestampsAndWatermarks(
WatermarkStrategy.<EventData>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, ts) -> event.getEventTime()))
// 按 user_id 分组
.keyBy(EventData::getUserId)
// 基于事件窗口 3分钟滚动窗口
.window(TumblingEventTimeWindows.of(Duration.ofMinutes(3)))
// 聚合
.aggregate(new CountAggregateFunction(), new WindowResultFunction());
// 6. 写入 PostgreSQL
aggregatedStream.addSink(JdbcSink.sink(
"INSERT INTO helpcenter_stg.user_net_clink (user_id, window_start, window_end, action_counts) " +
"VALUES (?, ?, ?, ?)",
(ps, value) -> {
// user_id
ps.setString(1, value.f0);
// 窗口起始时间
ps.setTimestamp(2, new Timestamp(value.windowStart));
// 窗口结束时间
ps.setTimestamp(3, new Timestamp(value.windowEnd));
// 聚合结果
ps.setLong(4, value.count);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
// 增加重试次数
.withMaxRetries(3)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:postgresql://172.*.*.132:2**00/default_dw")
.withUsername("he*****in")
.withPassword("hex*****26")
.build()
));
env.execute("Kafka to PostgreSQL Aggregation");
}
private static long parseEventTime(String json) {
try {
Map<String, Object> map = ObjectMapperUtil.jsonToMap(json);
return Long.parseLong(map.containsKey("record_ts")
? map.get("record_ts").toString()
: "0");
} catch (Exception e) {
// 异常处理:记录日志并返回当前时间
return System.currentTimeMillis();
}
}
public static class CountAggregateFunction implements AggregateFunction<EventData, Long, Long> {
@Override
public Long createAccumulator() {
// 初始累加器
return 0L;
}
@Override
public Long add(EventData eventData, Long acc) {
return acc + 1;
}
@Override
public Long getResult(Long accumulator) {
// 返回最终结果
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
// 合并不同分区的累加结果
return a + b;
}
}
// 窗口结果处理函数
public static class WindowResultFunction implements WindowFunction<Long, AggResult, String, TimeWindow> {
@Override
public void apply(String userId, TimeWindow window, Iterable<Long> counts, Collector<AggResult> out) {
// 获取聚合结果
Long total = counts.iterator().next();
AggResult result = new AggResult();
result.f0 = userId;
result.count = total;
result.windowStart = window.getStart();
result.windowEnd = window.getEnd();
out.collect(result);
}
}
// 聚合结果 POJO
public static class AggResult {
// user_id
public String f0;
// 聚合值
public long count;
// 窗口起始时间戳
public long windowStart;
// 窗口结束时间戳
public long windowEnd;
public AggResult() {}
}
public static class EventData implements Serializable {
// user_id
private String userId;
// 事件时间戳(毫秒)
private long eventTime;
public EventData() {}
public EventData(String userId, long eventTime) {
this.userId = userId;
this.eventTime = eventTime;
}
public String getUserId() { return userId; }
public void setUserId(String userId) { this.userId = userId; }
public long getEventTime() { return eventTime; }
public void setEventTime(long eventTime) { this.eventTime = eventTime; }
}
}
- 打成jar 包上传到平台“资源文件”模块
- 在流式数据加工作业选择jar 模式并绑定对应jar包后保存作业
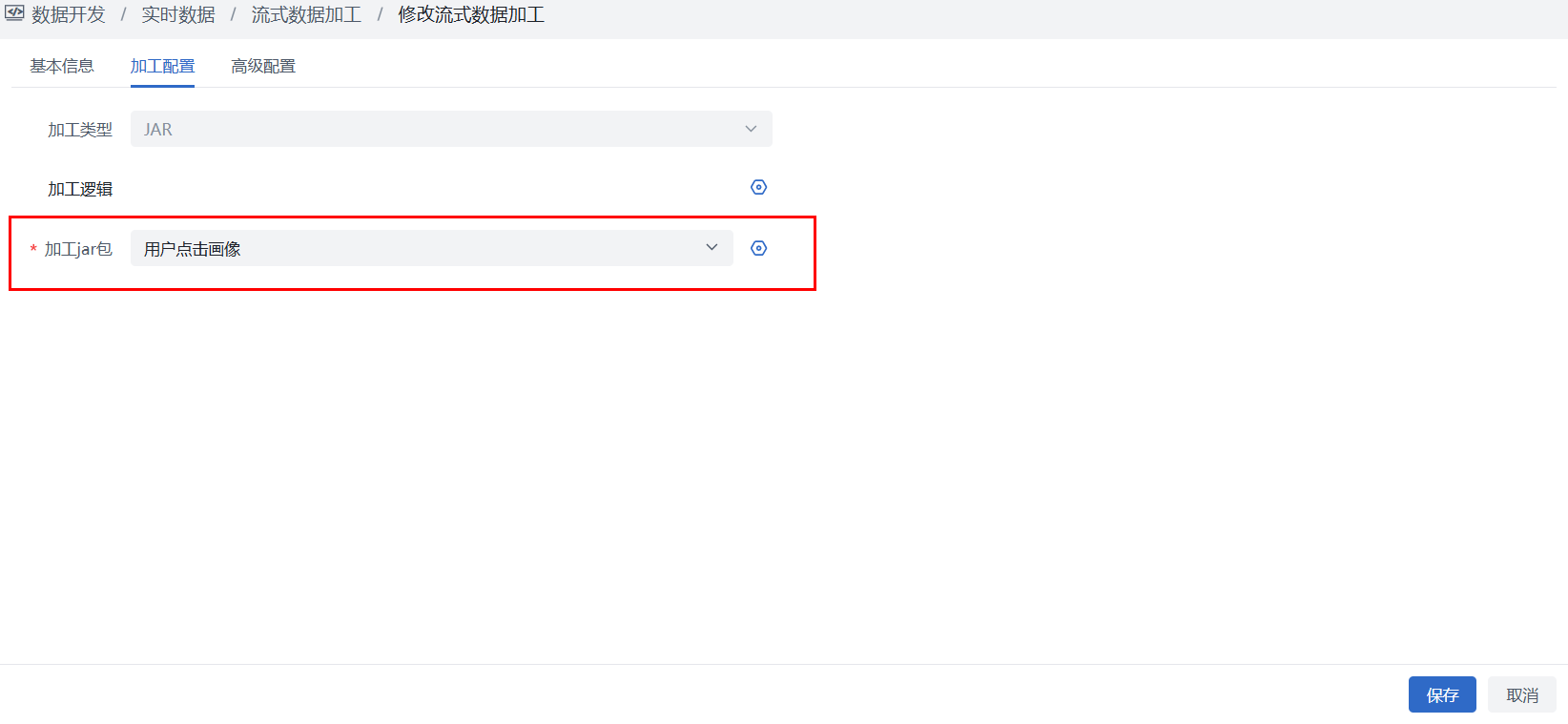
第三步:作业启动运行
选择数据开发 > 实时数据 > 流式数据加工 ,在作业列表中选择刚刚创建好的流式数据加工作业,此时作业为“未开始”状态,在操作列点击“运行”按钮即可启动作业运行。
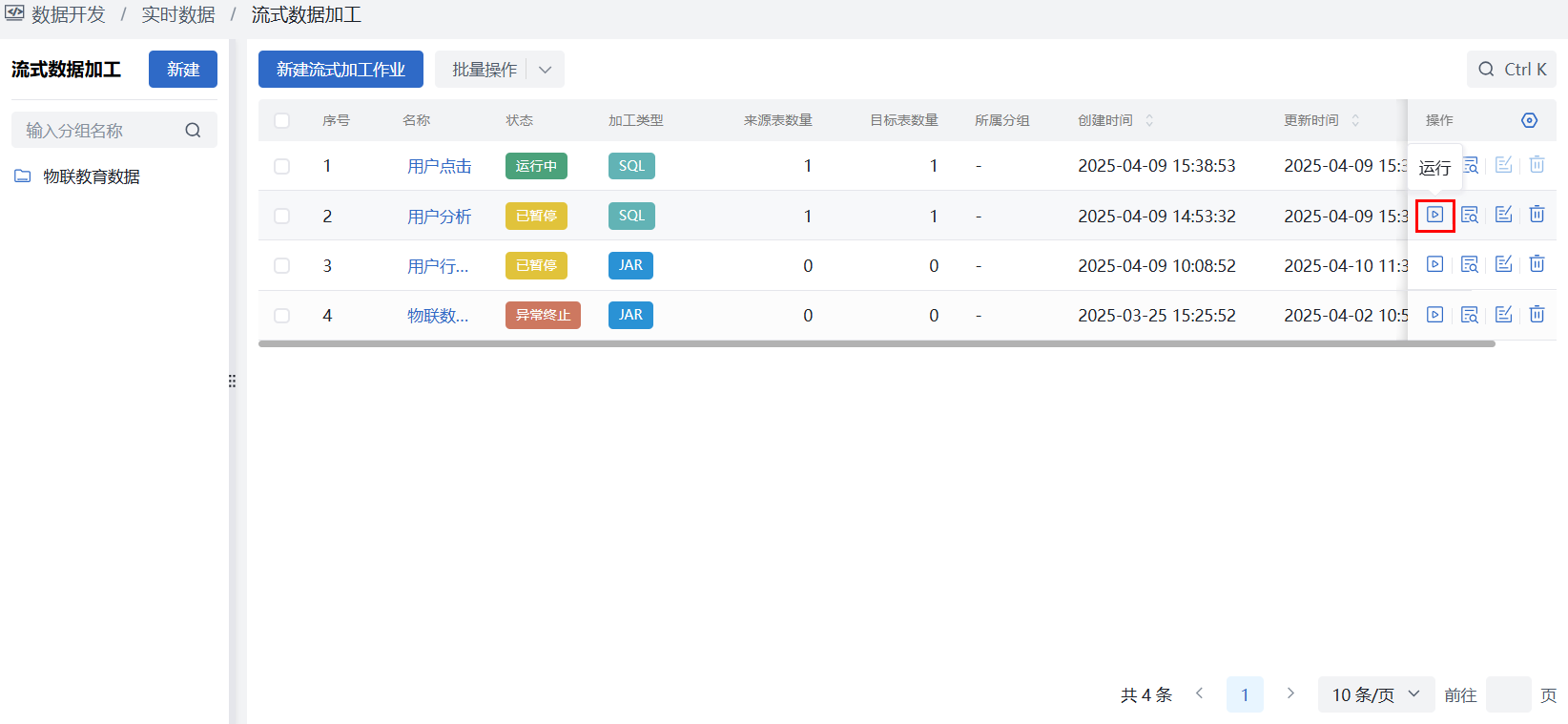
作业运行说明: ①全量阶段:新创建的作业,初始将会自动对来源表中的存量数据进行全量的加工 ②增量阶段:存量数据同步完成后即进入增量阶段,将会持续接收topic消息完成增量数据加工
第四步:作业监控与运维
1)选择数据开发 > 实时数据 > 流式数据加工,在作业列表中选择所关注的作业,在操作列点击“运行详情”可查看作业运行信息,包括通过运行信息和历史以大致了解数据同步情况,并提供运行日志下载。
仅异常终止状态提供失败日志的查看与下载
作业状态监控与维护操作说明:
异常终止:系统会持续监控各流式数据加工作业的运行状态,当来源或目标发生数据源、数据表、数据记录等异常变更,或网络等异常状况,均会触发作业变更为“异常终止”,此时无变更可通过“运行”进行重试恢复,或“暂停”操作对作业进行变更维护。
暂停:处于“运行中”状态的作业可点击暂停,作业状态变更为已暂停,暂停后可维护作业配置;暂停后再运行,SQL模式作业将从暂停点位继续运行。
- 仅SQL模式作业支持从暂停点位继续运行
- 若作业中来源目标等信息发生变更,将无法从暂定点位继续运行
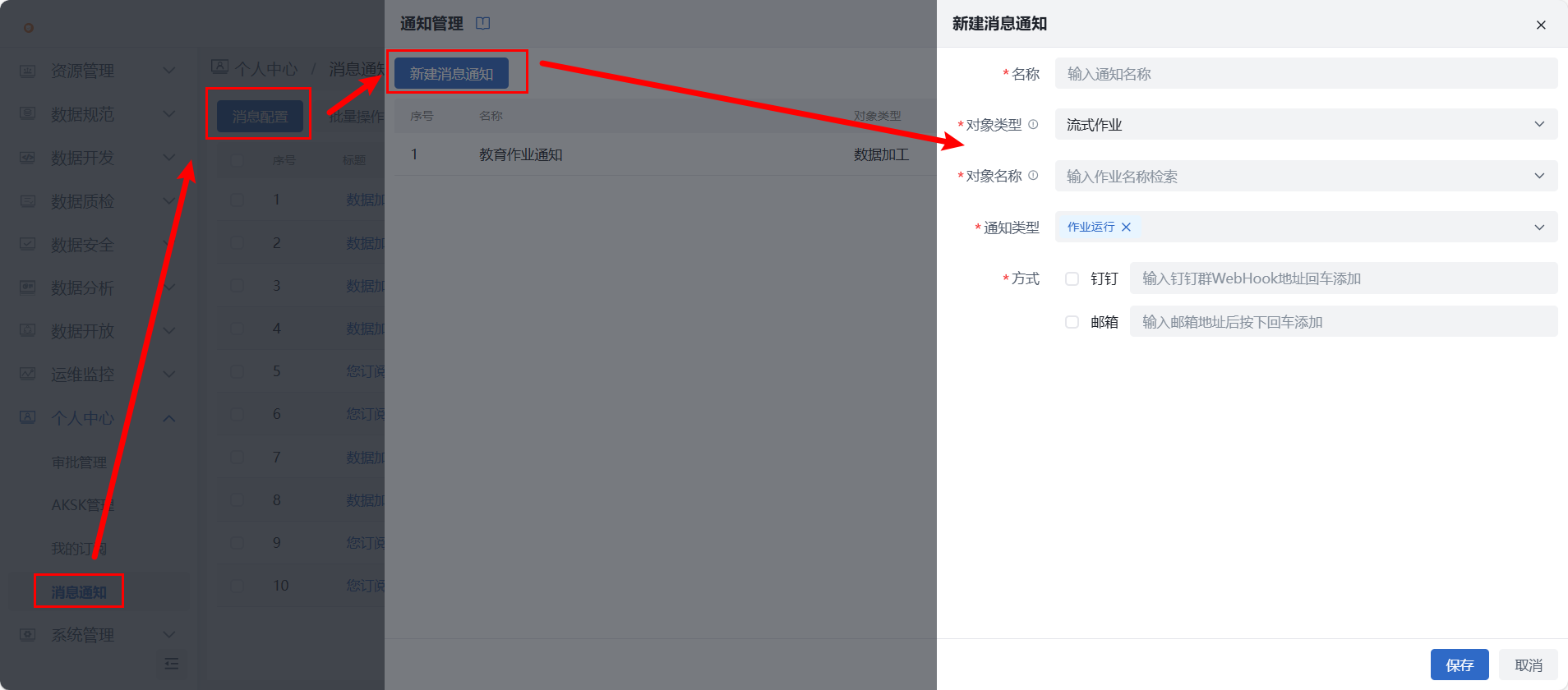
2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“流式作业”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。