批量数据加工
业务场景
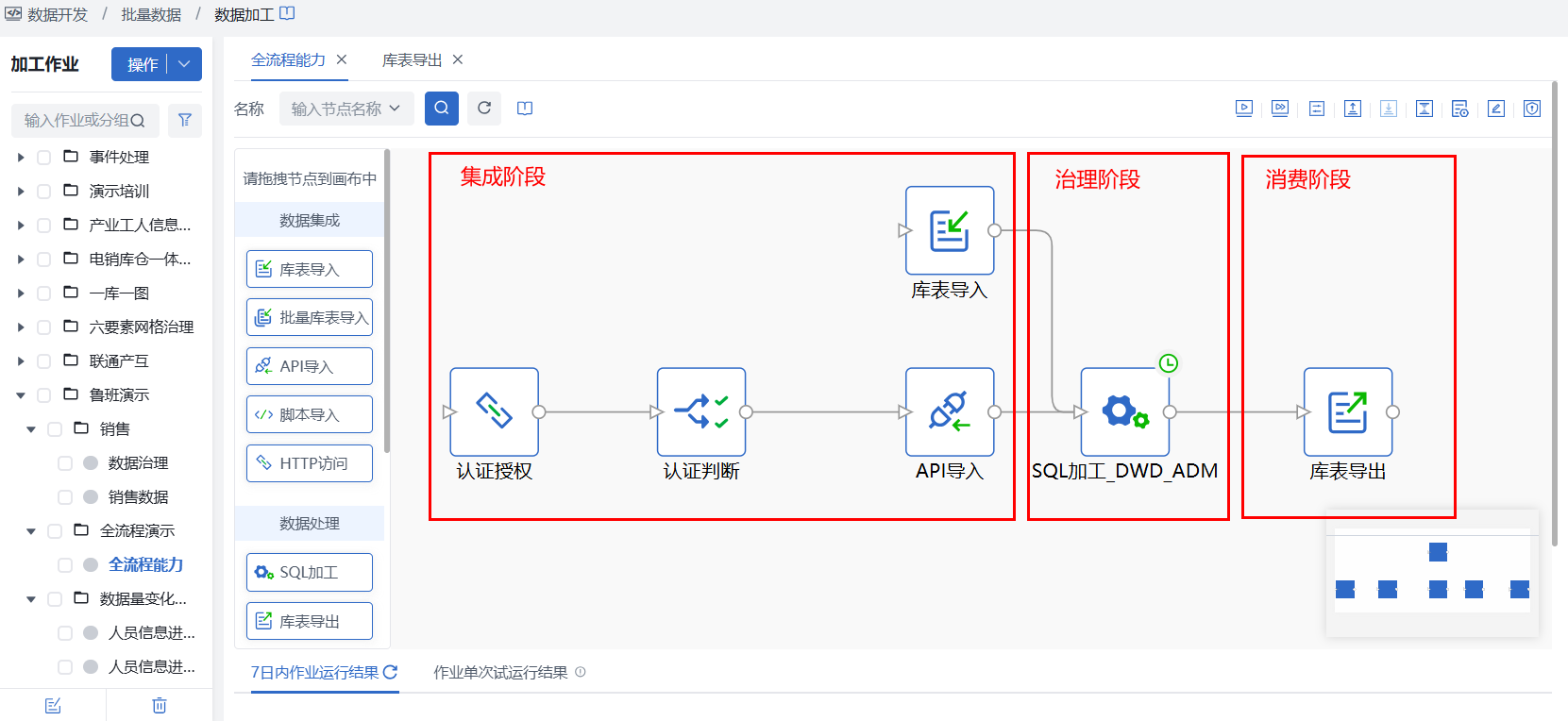
批量数据全流程开发,包括从PG数据库及API完成数据集成,通过SQL加工进行数据融合治理,最终通过数据导出完成数据消费,共三个阶段以实现数据开发闭环。
前提条件
- 平台部署完毕,批量数据加工服务正常;
- 用户拥有数据源管理、批量数据模块权限;
- 源头数据源连通正常。
使用限制
操作流程
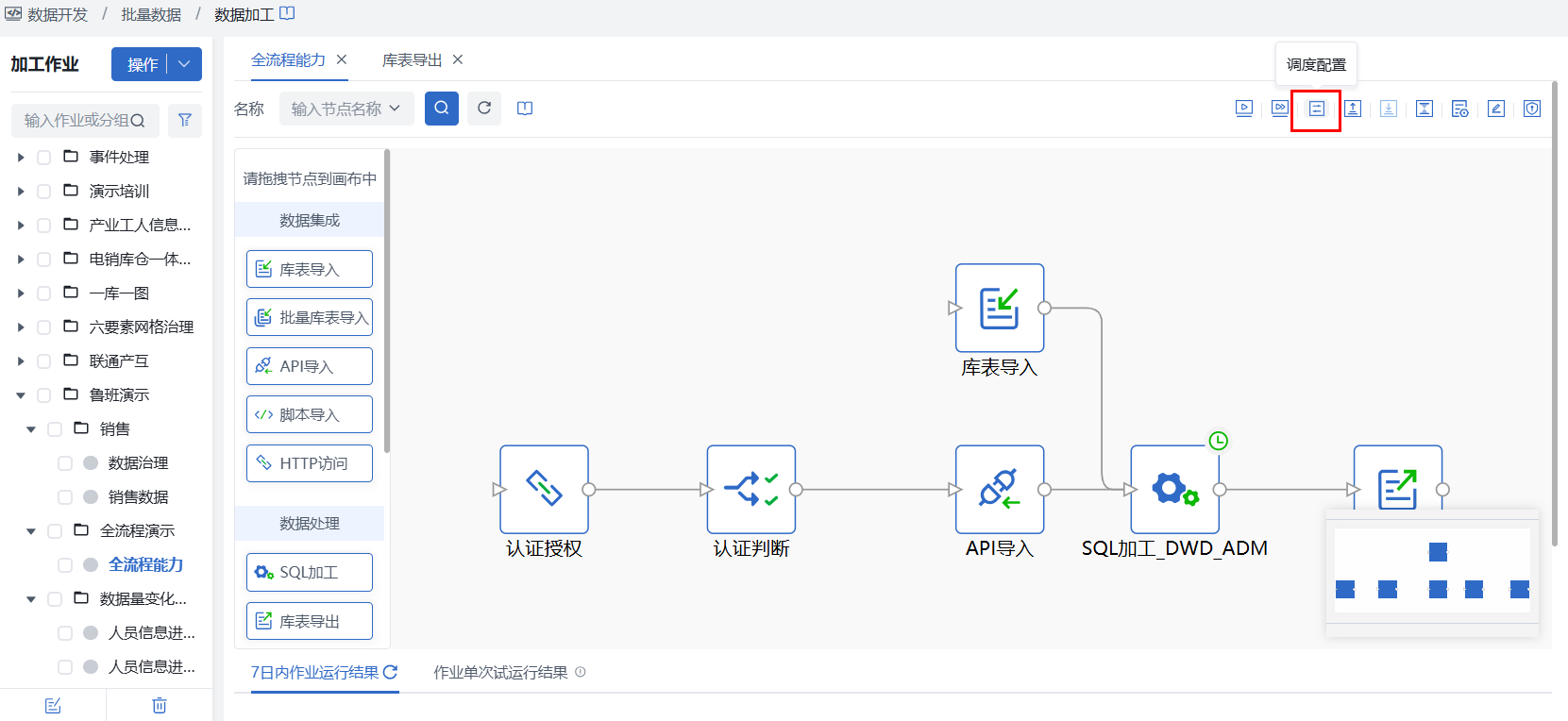
第一步:创建数据加工作业
阶段1:数据集成
在数据开发 > 批量数据 > 数据加工页面新建数据加工作业,并在画布中拖入所需数据集成节点。
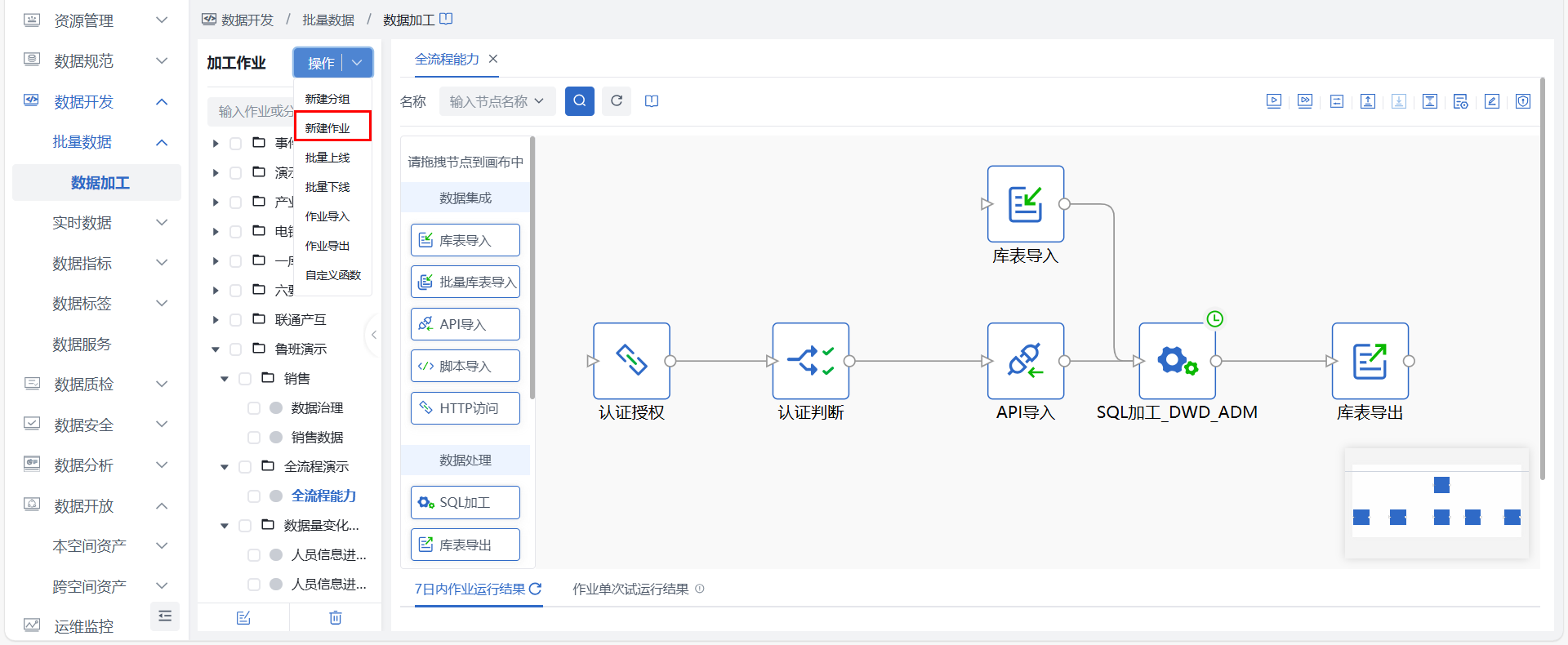
- 库表导入:本实践示例中,需将源PG库的数据集成至仓内,因此需选择【库表导入】节点,并完成节点内来源与目标的配置,更多详细配置可查看批量库表导入介绍。
- API导入:本实践示例中,同时需将API数据集成至仓内,但该API需先进行认证授权和判断,此时需通过【HTTP访问】获取认证参数值,并传递给【分支判断】节点以判断是否执行下游路线【API导入】节点。更多详细配置可查看参数传递、API数据导入介绍。
阶段2:数据治理
1)在当前作业画布中,拖入【SQL加工】节点,并双击节点,进入节点配置页面,根据开发需要完成SQL编写,并保存。详细配置说明参见:加工节点-SQL加工。
2)节点连线:将上游数据集成节点与当前SQL加工节点,按所需逻辑进行连线,完成数据集成到治理开发的串联。
注意
- 本实践示例仅进行简单数据融合加工为DWD表,若实际中需要更多加工过程,可拖入多个【SQL加工】节点;
- 若SQL加工无法满足需要,更复杂的开发治理可通过Shell、Python、Java三类脚本开发节点完成,详细可查看相关最佳实践。
阶段3:数据消费
1)在当前作业画布中,拖入【库表导出】节点,并双击节点,进入节点配置页面,选择已开发治理完成的表作为来源表,并选择已在数据源管理中注册的目标源作为最终消费对象,更多细节配置可查看库表导出。
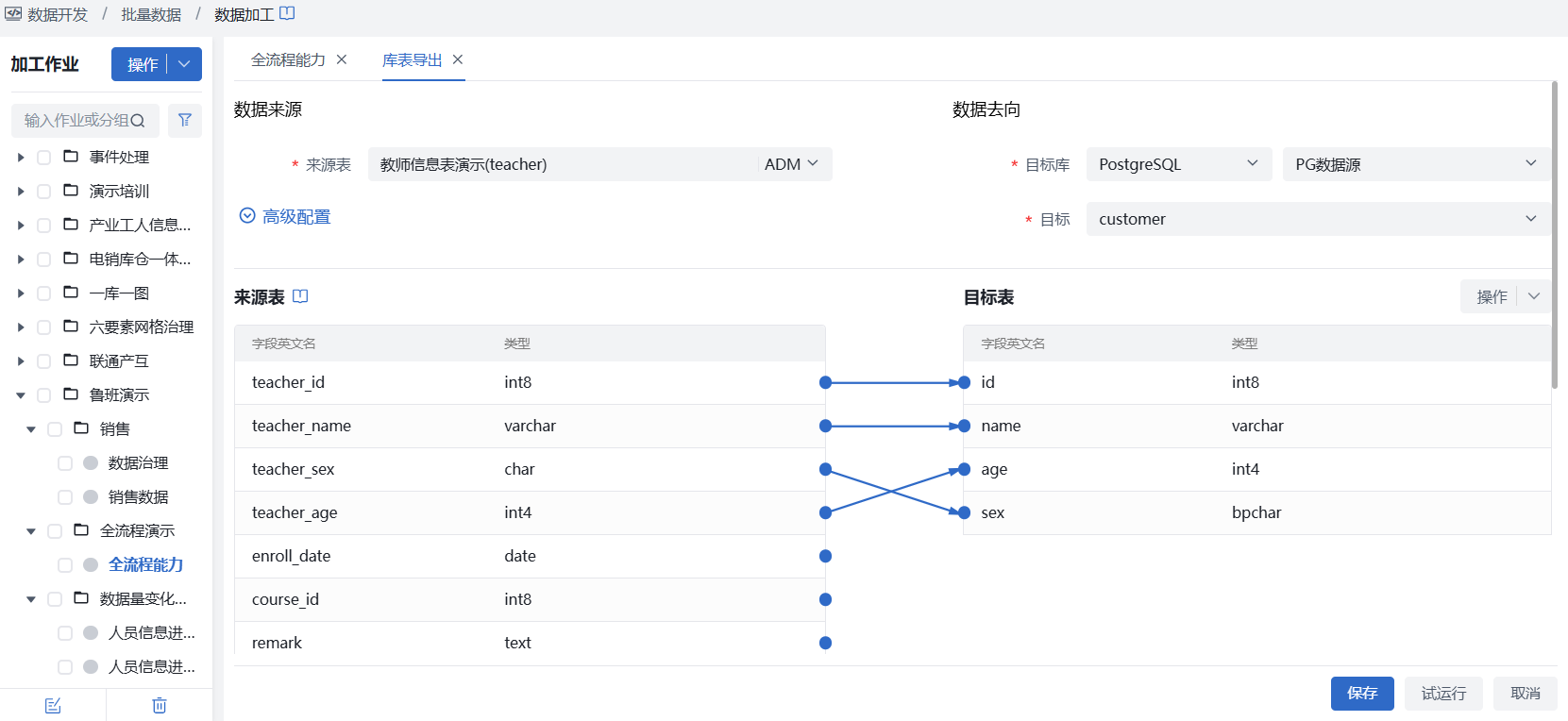
2)节点连线:将上游数据开发节点与当前库表导出节点,按所需逻辑进行连线,完成数据开发到数据消费的串联。
第二步:作业级配置
1)在当前作业画布右上角,点击【试运行】可验证当前作业配置是否正确,能够正常运行。
2)试运行成功后,并对当前作业完成调度配置后,再点击【上线】即可上线作业。
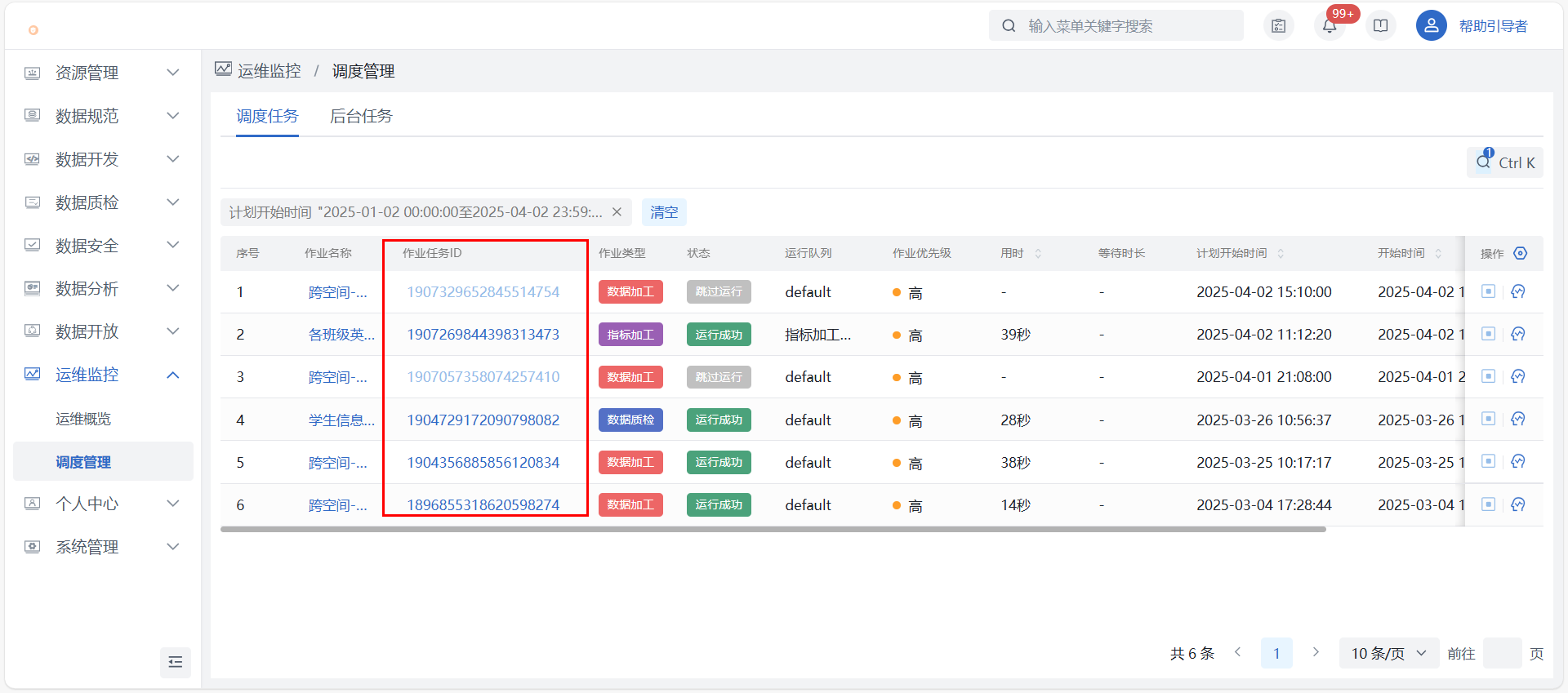
第三步:运维监控
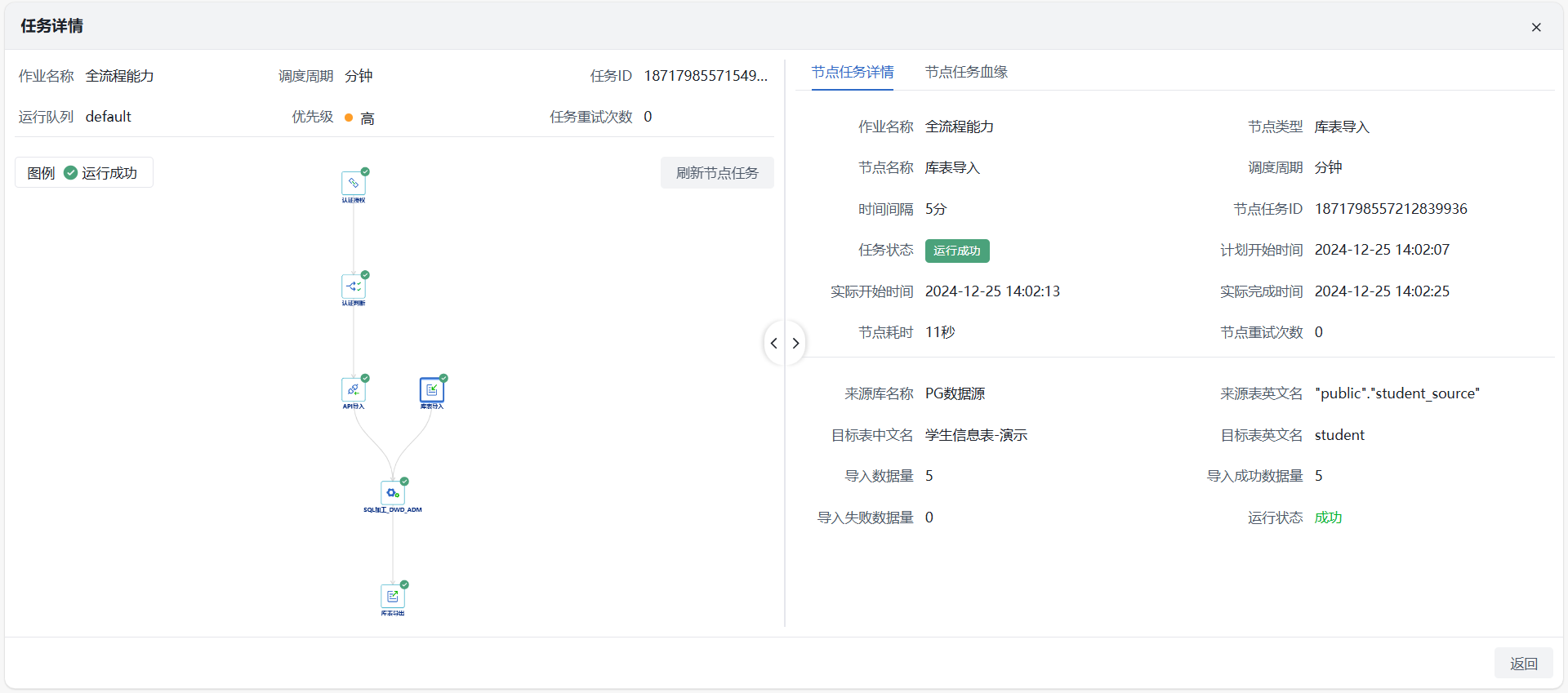
1)调度管理:在运维监控_调度管理找到对应作业,点击【查看作业任务】可查看运行详情,主要信息包含作业任务调度明细、各调度的运行结果、日志下载、节点任务血缘等。
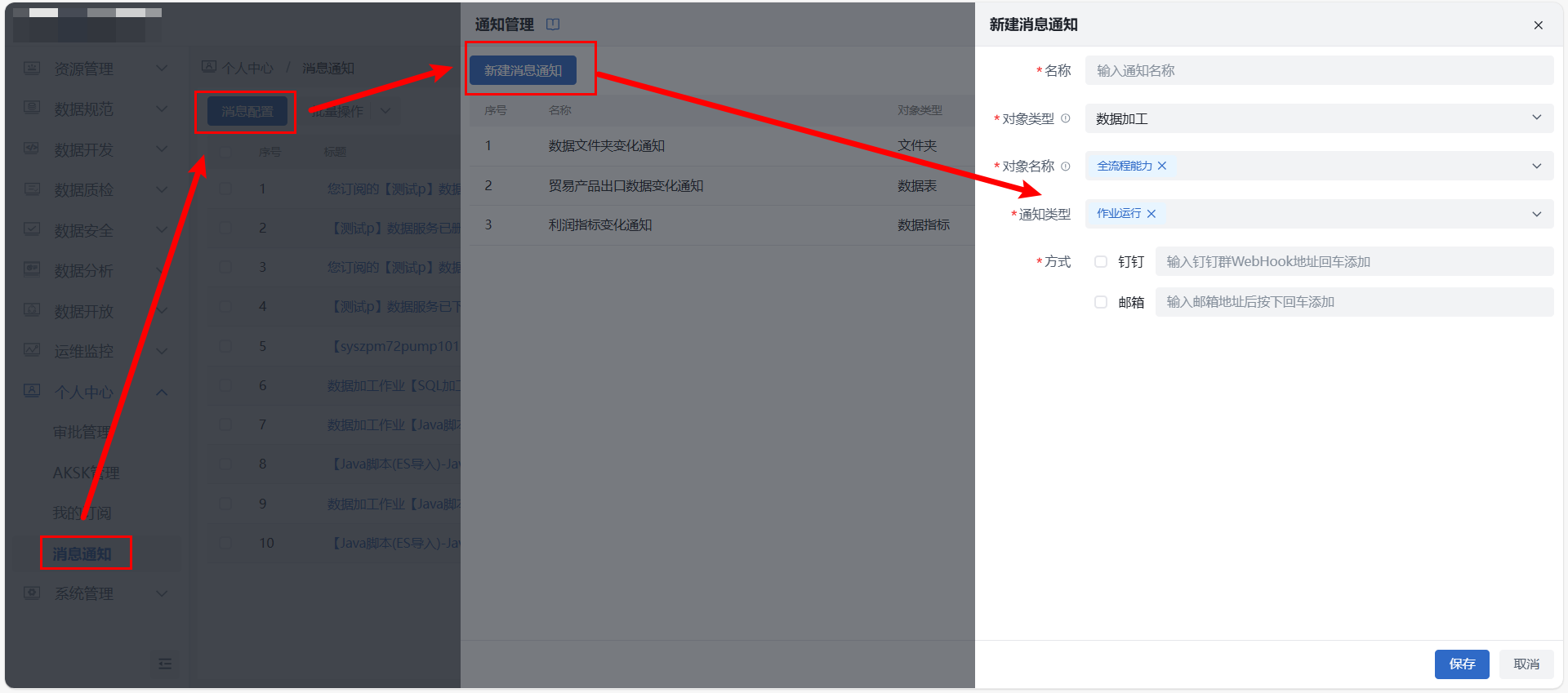
 2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。
2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。