数据源管理
使用场景:用户通过新建数据源管理所需的外部数据源,在数据开发中作为来源或去向库。
使用角色:数据开发人员、数据集成人员。
功能描述:平台支持数据库连接配置,供后续数据开发中的“库表导入”、“库表导出”、“API导入”、实时数据同步、信道数据作业等模块使用。
支持数据源类型及版本
| 数据源类型 | 默认驱动版本 |
|---|---|
| HexaDB(海纳) | v2.1.0 |
| MySQL | v8.0 |
| Oracle | 12c |
| PostgreSQL | v14.7 |
| SQLServer | v15.0.4312.2 |
| DM(达梦) | V8 |
| KingbaseES(人大金仓) | v4.1.2 |
| HighGo(瀚高) | v4.5.8 |
| MongoDB | v3.4.24 |
| ElasticSearch | v8.11.0 |
除以上数据源类型外,平台还支持Kafka、API、FTP类型数据源。
- 以上为平台默认驱动版本,并不代表仅支持该版本;且平台支持自定义驱动扩展版本
- 同一个数据库当地址、数据库、用户名、密码等信息组合重复时(包含API、kafka、FTP),不允许再重复创建
数据源分类
关系型数据库
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个非 API 非 Kafka 数据源。点击 “新建数据源” 按钮开始新建数据源。
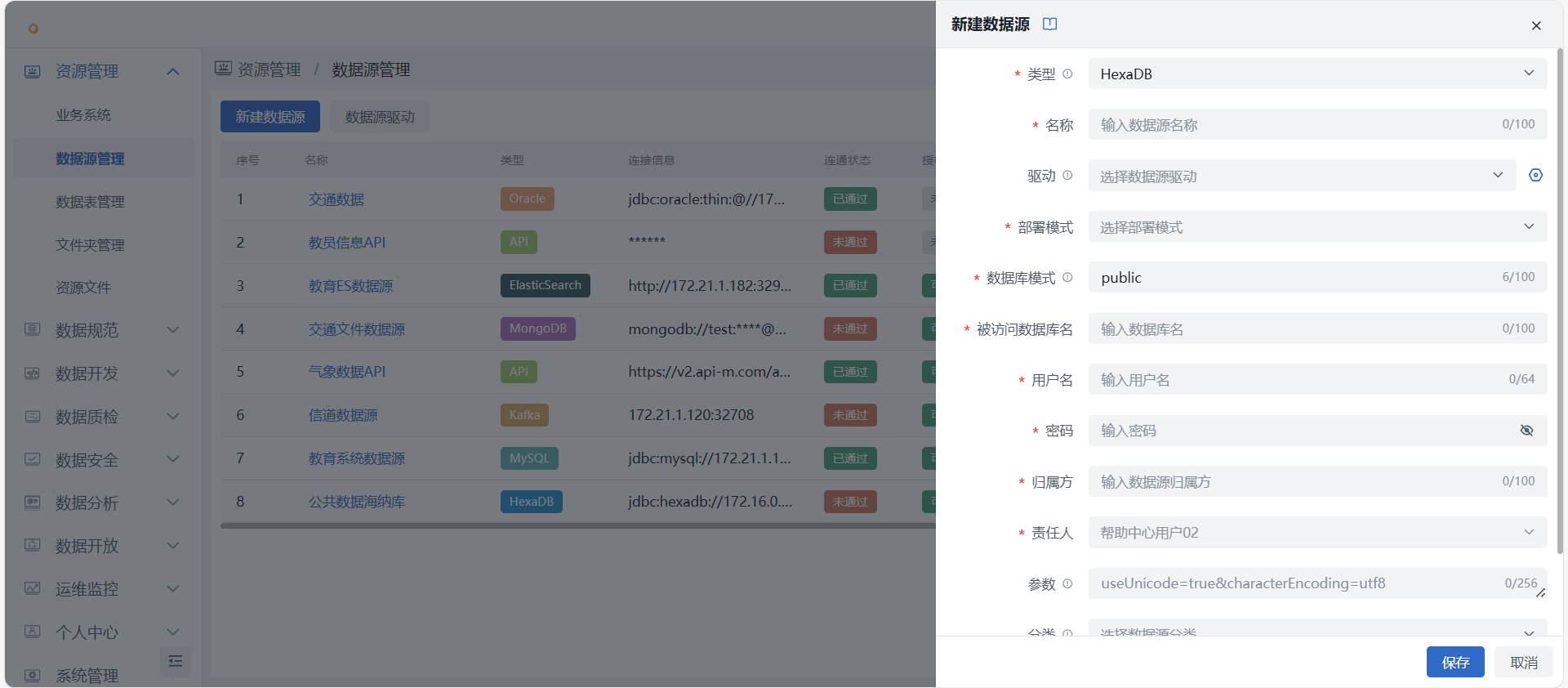
- 进入新建数据源页面,下拉选择数据源类型后填写目标数据源信息,用来作为数据集成的来源库或目标表。
- 填写项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API、ElasticSearch;
- 名称:必填项,根据业务实际场景填写数据源名称,空间内不允许重复;
- 归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- 部署模式:必填项,下拉选择单机模式(Standalone)或集群模式(Shard Clister);
- 成员:若选择单机模式,则继续填写下方数据库地址和端口;若选择集群模式,则可分别填写各成员的地址和端口;
- 数据库地址:必填项,根据根据业务实际场景填写数据库地址;
- 端口:必填项,根据根据业务实际场景填写端口;
- 数据库名:必填项,根据根据业务实际场景填写数据库名;
- 数据库模式:输入数据库模式名称,除 Oracle 和 DM 数据库外必填,MySQL、MongoDB 数据库无该项;
- 服务名;必填项,仅 Oracle 数据库,根据业务实际场景填写 Oracle 数据库服务名称;
- 用户名:必填项,输入目标数据库连接用户名;
- 密码:必填项,输入目标数据库连接密码;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 数据源驱动:非必填,则使用默认驱动,可下拉选择当前数据源类型下的自定义驱动名称;
- 参数:非必填,输入数据库连接参数;
- 描述:非必填,对此数据源作用或其他方面信息进行描述。
非关系型数据库
MongoDB数据源
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个 MongoDB 数据源。点击 “新建数据源” 按钮开始新建数据源。
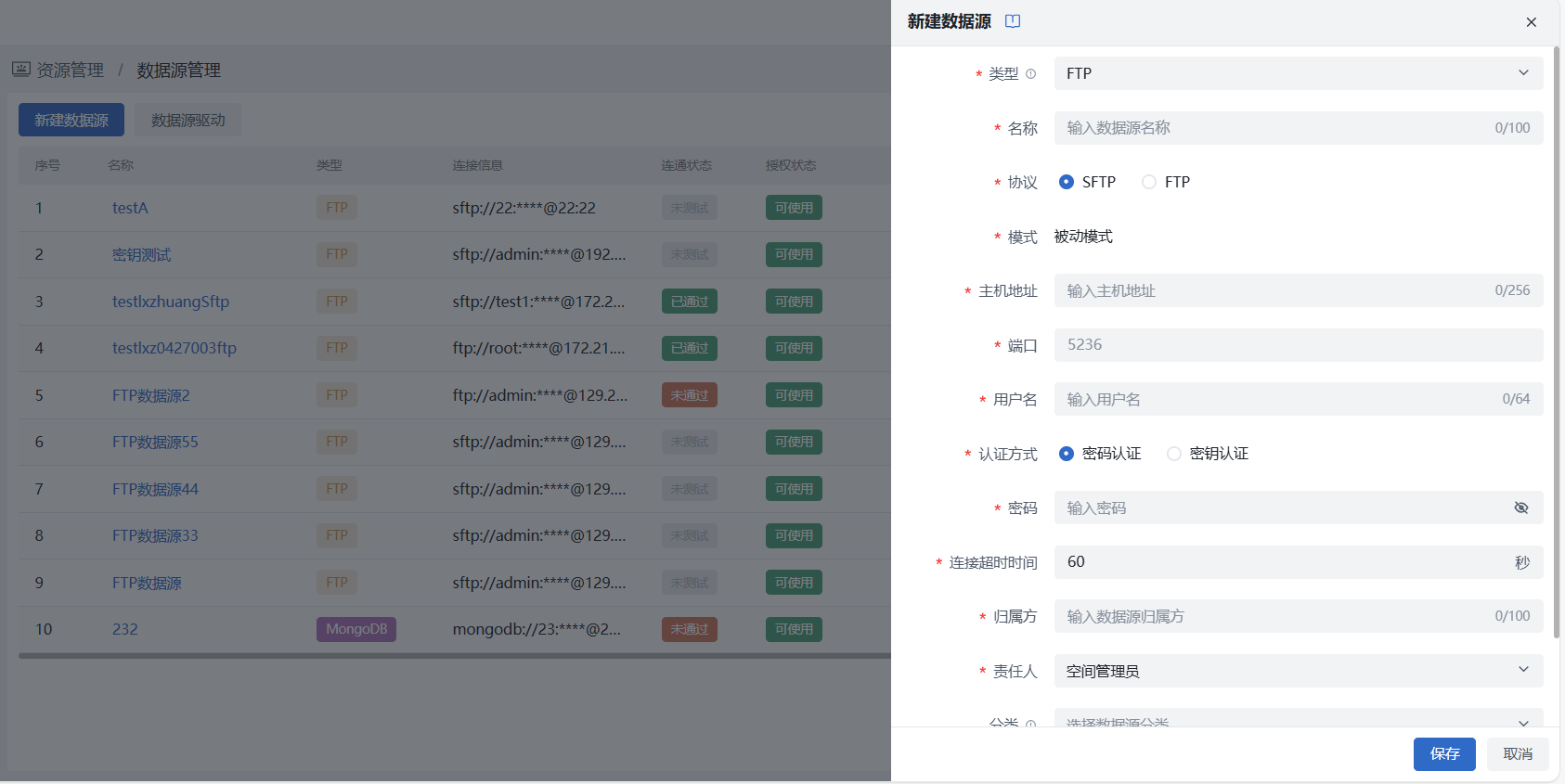
- 进入新建数据源页面,下拉选择MongoDB数据源类型后填写目标数据源信息,用来作为数据集成的来源库。
填写项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API、ElasticSearch,这里我们选择MongoDB;
- 名称:必填项,根据业务实际场景填写数据源名称;
- 归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- 部署模式:必填项,下拉选择单机模式(Standalone)或集群模式(Shard Clister);
- 成员:若选择单机模式,则继续填写下方数据库地址和端口;若选择集群模式,则可分别填写各成员的地址和端口;注意
当部署模式选择集群模式(Shard Clister)时,成员为必填项,包括主机地址和端口号,若有多个成员,可点击新增成员按钮,添加多个成员。
- 数据库地址:必填项,根据根据业务实际场景填写数据库地址;
- 端口:必填项,根据根据业务实际场景填写端口;
- 被访问数据库名:必填项,根据实际业务场景填写数据库名;
- 用户名:必填项,输入目标数据库连接用户名;
- 密码:必填项,输入目标数据库连接密码;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 参数:非必填,输入数据库连接参数;
- 描述:非必填,对此数据源作用或其他方面信息进行描述。
MongoDB常用连接参数示例:
- 认证数据库:authSource=xxx库名;
- 认证方式(当前仅支持示例中的一种):authMechanism=SCRAM-SHA-1;
- 读偏好:readPreference=secondary。
ElasticSearch数据源
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个ElasticSearch数据源。点击 “新建数据源” 按钮开始新建数据源。
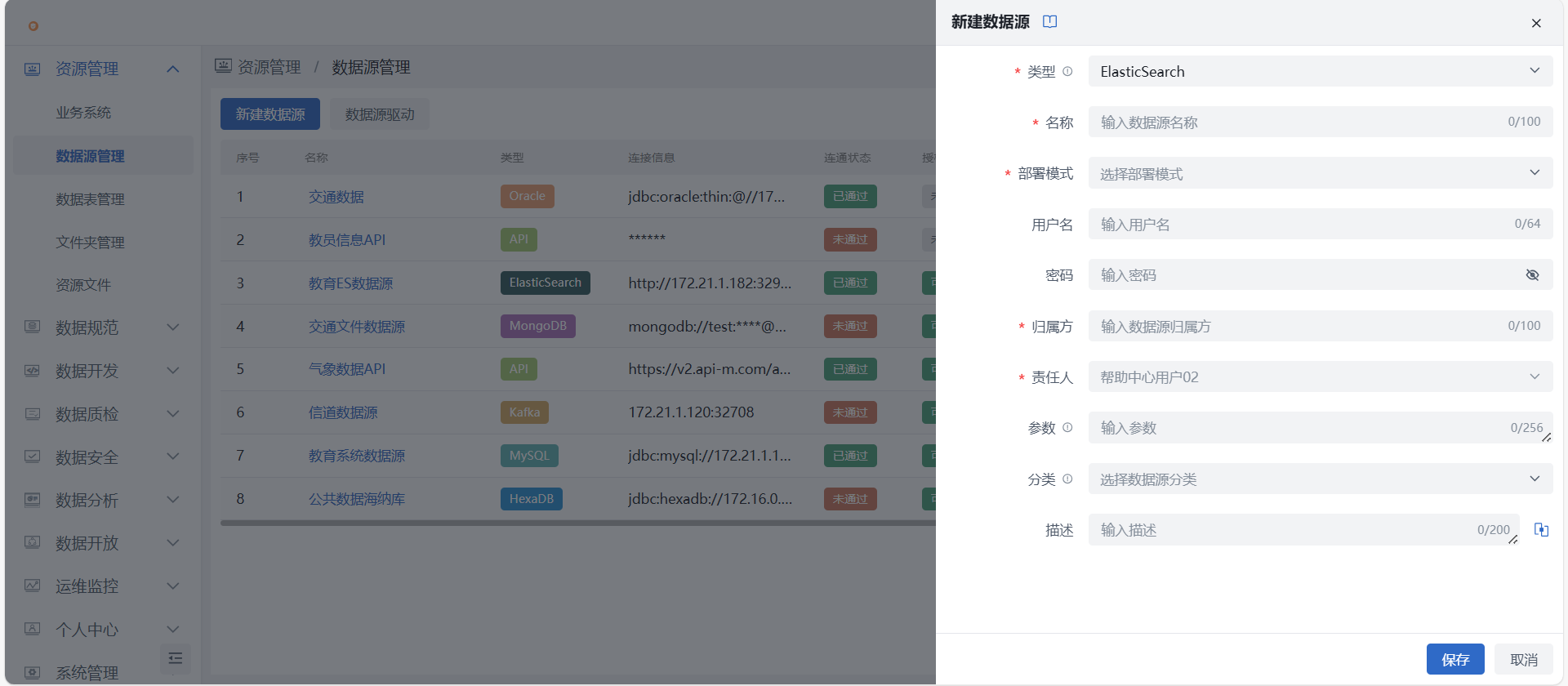
- 进入新建数据源页面,下拉选择ElasticSearch数据源类型后填写目标数据源信息,当前ES数据源仅支持数据加工-库表导出。
- 填写项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API、ElasticSearch,这里我们选择ElasticSearch;
- 名称:必填项,根据业务实际场景填写数据源名称;
- 数据源归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- 部署模式:必填项,下拉选择单机模式(Standalone)或集群模式(Shard Cluster);
- 成员:若选择单机模式,则继续填写下方数据源地址和端口;若选择集群模式,则可分别填写各成员的地址和端口;
- 数据源地址:必填项,根据根据业务实际场景填写数据源地址;
- 端口:必填项,根据根据业务实际场景填写端口;
- 用户名:必填项,输入目标数据库连接用户名;
- 密码:必填项,输入目标数据库连接密码;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 描述:非必填,对此数据源作用或其他方面信息进行描述。
API
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个 API 数据源。点击 “新建数据源” 按钮开始新建数据源。
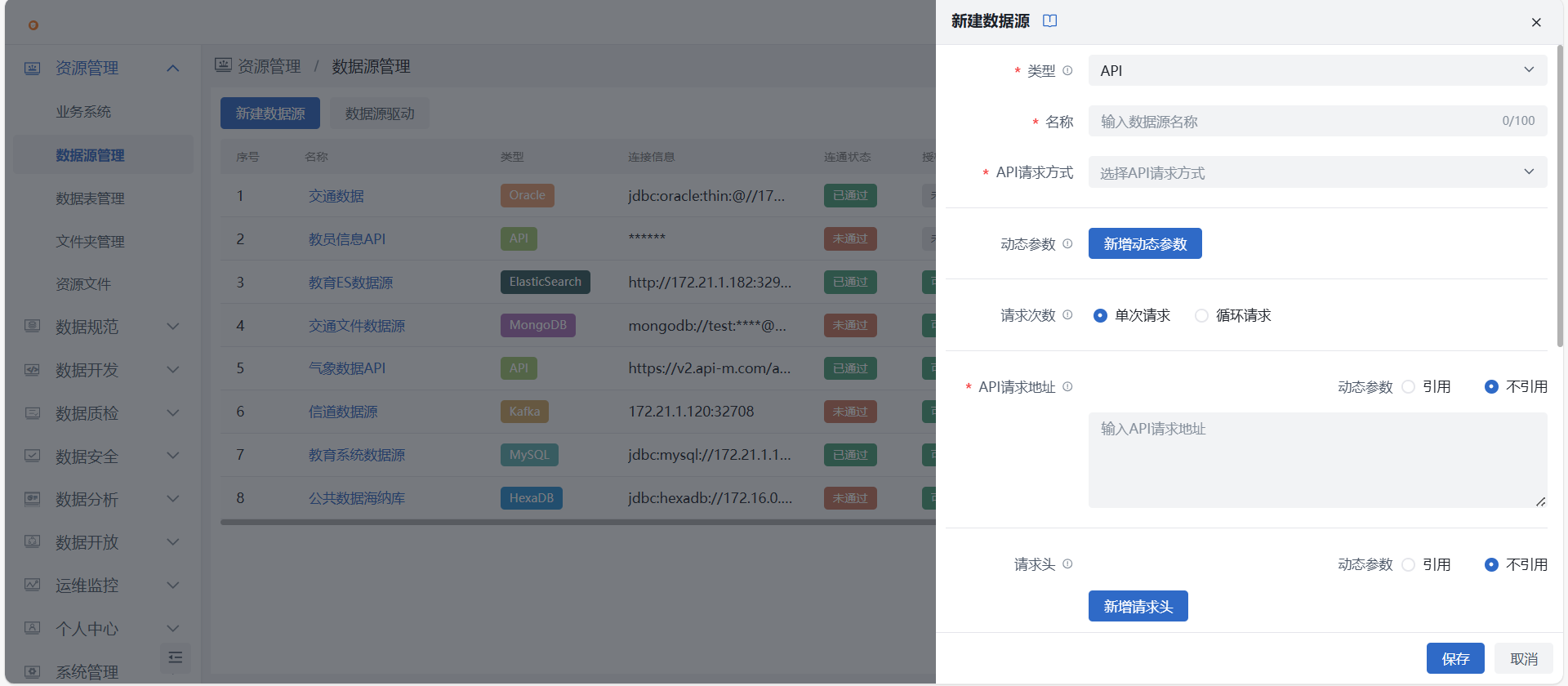
- 进入新建数据源页面,下拉选择 API 数据源类型后填写目标数据源信息,用来作为API导入的来源。
- 信息项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API,这里我们选择 API;
- 名称:必填项,根据业务实际场景填写数据源名称;
- 归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- API请求方式:必填项,下拉选择 POST 或 GET;
- 签名:非必填项,下拉选择已上传的签名文件脚本jar包注意
- 请先点击右侧“模板下载”按钮,将模板下载至本地后按模板要求编写签名脚本,模板中提供了全量参数,可按需选用;
- 签名文件编写完成需在“资源文件”模块上传,当前仅支持jar格式文件
- 签名支持在请求地址、请求头、请求体中引用,具体引用详见:签名配置
- 动态参数:非必填,由用户手动输入 key 和 value,可新增多个动态参数;
- 请求次数:
- 单次请求:每次调度仅请求一次,获取全量数据;
- 循环请求:若来源接口已分页,可通过循环多次请求获取数据,提供以下默认请求设置:
- 循环请求对应参数:当前页码参数,默认为pageNum,可根据接口实际情况修改,以实现基于页码变化循环取数;
- start_index:循环请求的起点,默认为1,则初始从第一页开始取数;可修改,如改为5,则从第5页开始取数;
- end_index:循环请求的终点,默认为不填,则若有新数据都会获取;若填写,如100,则最多仅取到100页的数据;
- step:循环请求的步长,默认为1,则按步长为1取数;可修改,如改为2,则取数页码为1、3、5、7...以此类推;
- API请求地址:必填项,根据业务实际场景填写 API 地址;
- 请求头:非必填项,根据 API 请求方式填写请求头;
- 请求体:非必填项,根据 API 请求方式填写请求体;
- 连接超时时间:必填项,默认120秒,最大可设置为600秒;以控制平台与API建立连接最大时长,超过时长自动终止;
- 读取超时时间:必填项,默认120秒,最大可设置为600秒;以控制平台读取、处理API数据最大时长,超过时长自动终止;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 描述:对此数据源作用或其他方面信息进行描述。
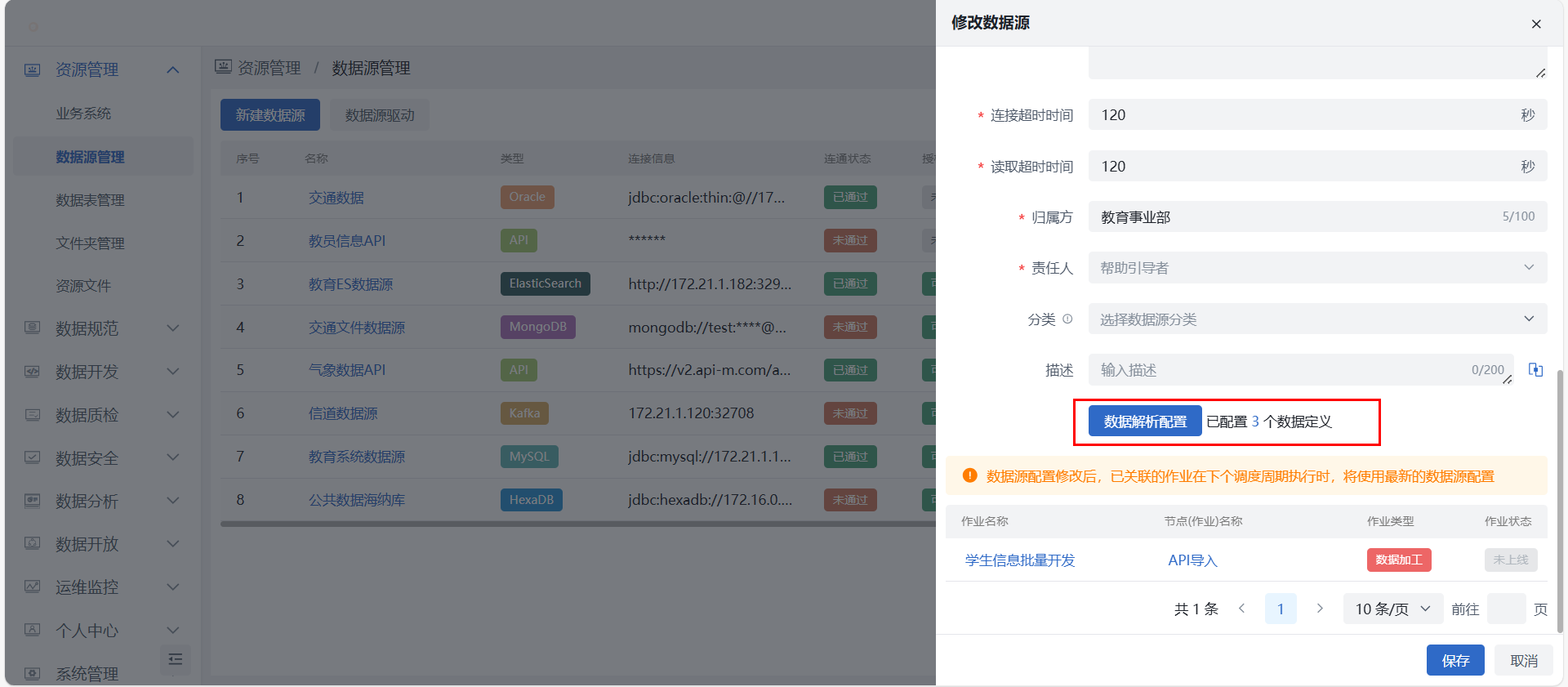
数据解析配置
API数据源配置解析只支持接口响应格式为 JSON 的数据。
在资源管理 > 数据源管理界面,点击“新建数据源”或对现有数据源进行“修改”操作,进入到操作界面后下拉至最底层,点击“数据解析配置”,即可进入数据源解析配置界面。
- 成功响应示例解析路径使用方法:
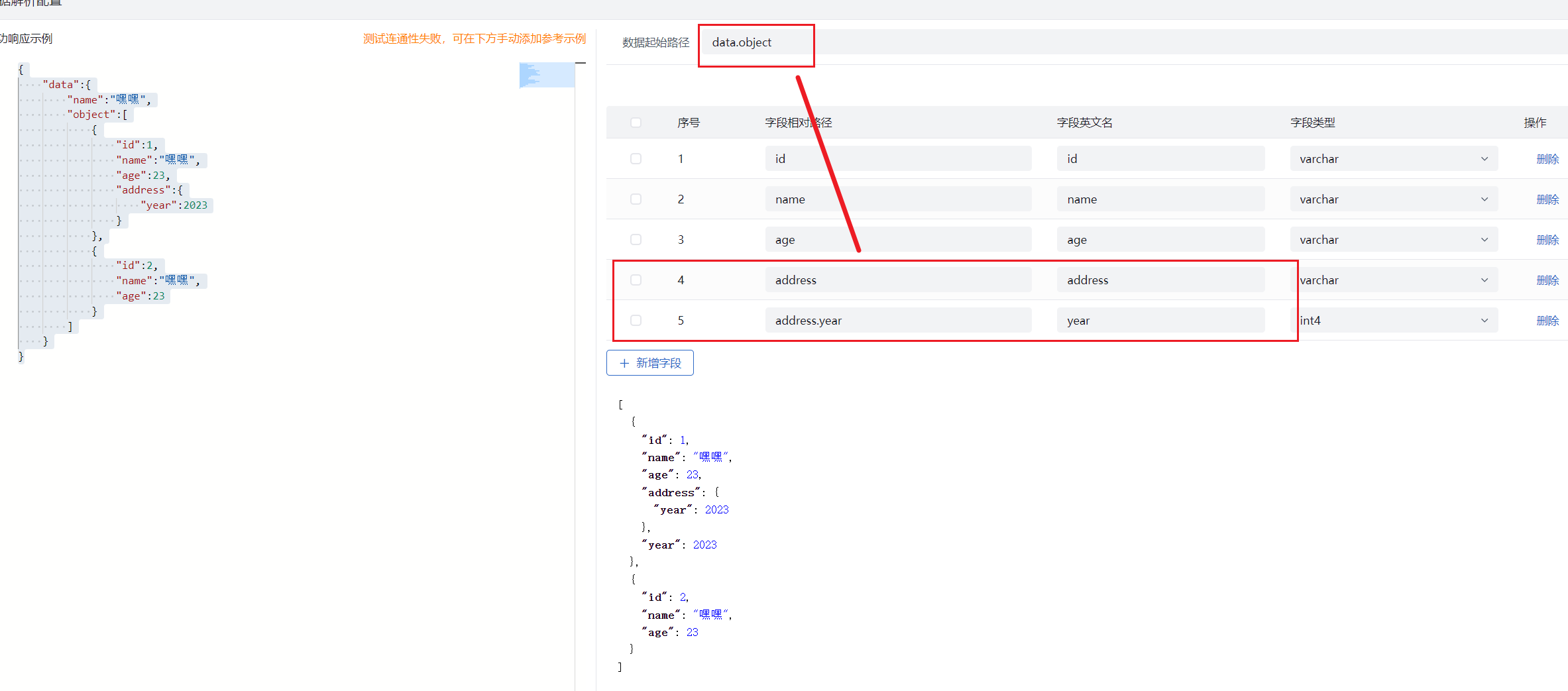
- 配置数据起始路径。用户可点击输入框直接配置数据起始路径。该路径表示获取接口的数据的起始位置。数据起始路径为相对于 JSON 数据的最外层。
- 解析数据起始路径。用户可点击“解析”自动获得当前起始路径下对象属性,并作为字段相对路径。如果当前起始路径指向非对象属性,则解析失败。
- 字段相对路径是相对于数据起始路径的相对路径,不可跨越层级设置;
- 路径设置遵循 JSONPath 语法,但根路径不需要按 JSONPath 语法以 $ 开始。
- 数据起始路径不缺省:
- 数据起始路径缺省:
- 返回对象示例解释:
- 设置数据起始路径:示例中 JSON 响应下的 data.object,表示想获取当前响应数据 data 这个属性下的 object 数据,此时 object 属性必须也是一个 JSON 对象;
- 数据的起始路径必须从响应 JSON 的根元素开始,不可越层级设置,譬如直接设置 object 是错误的,起始路径一定是形如 data.object 或者缺省留空,留空表示 JSON 数据的一级属性可以作为字段路径;
- 起始路径设置正确后,解析当前起始路径,得到当前起始路径下对象的一级属性,自动填充到字段相对路径中;
- 新增字段配置:字段相对路径必须也是相对于数据起始路径这个属性对象下的属性字段,譬如解析图中的 data.object 只能自动填充 id、name、age、address 这 4 个属性,但是可以新增一个字段取到该 address(必须是 JSON)下的 year,即相对起始路径下的 address.year。
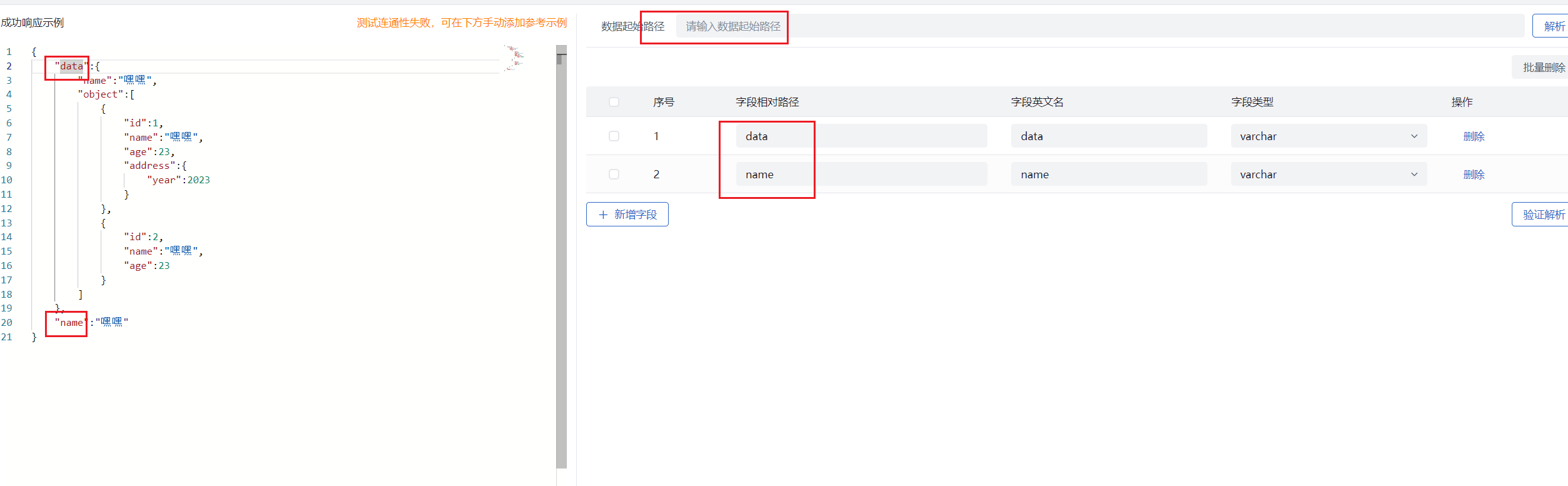
- 返回数组示例解释:
- 数据起始路径缺省:
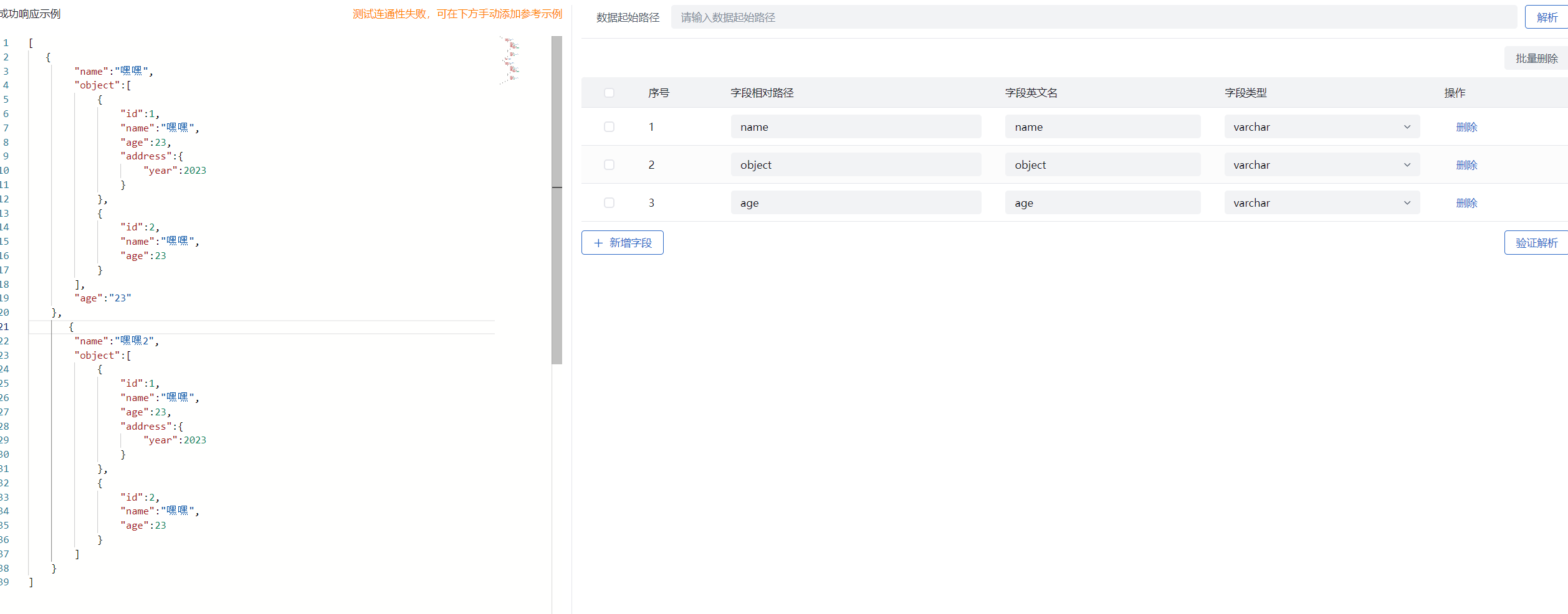
- 图中起始路径缺省,自动获取数组中第一个对象属性作为字段相对路径,解析数据为整个数组下每个对象中的属性值,即图中 2 条数据,新增字段配置同上。
- 数据起始路径不缺省:
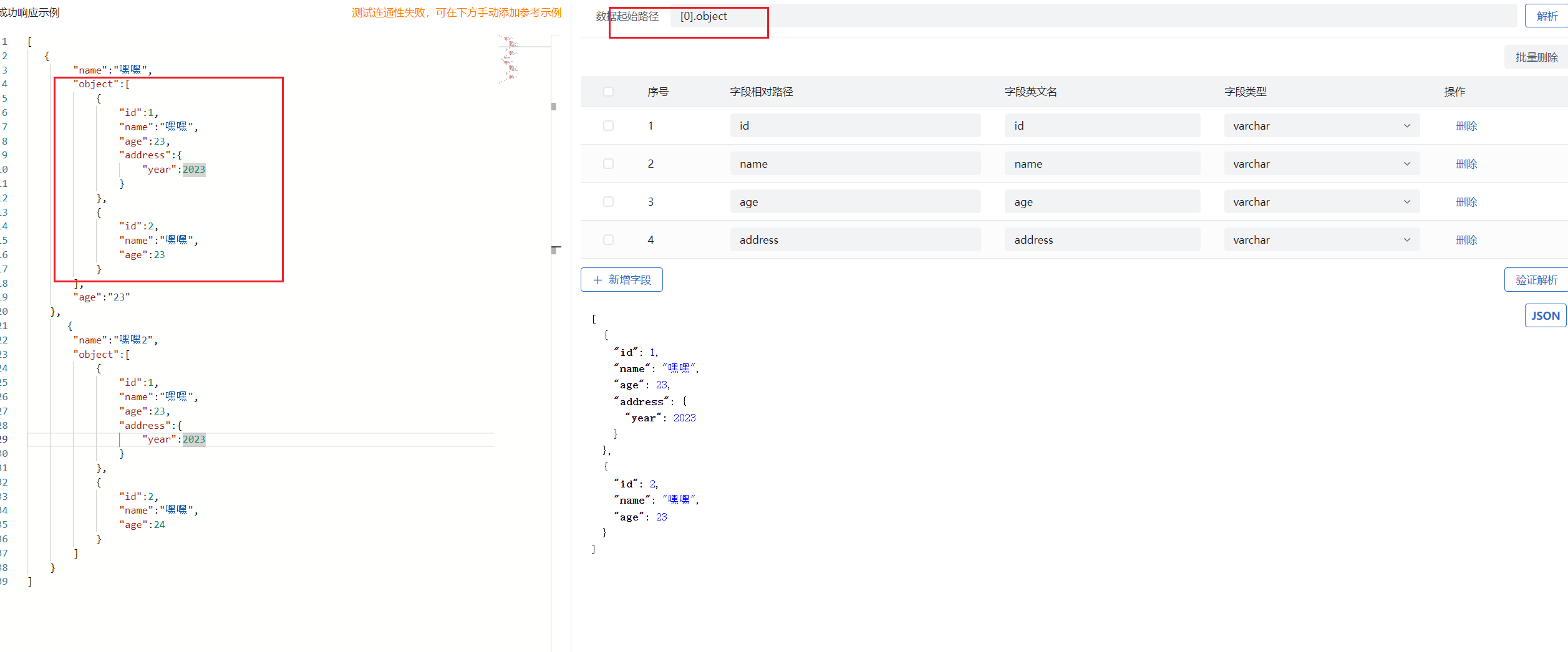
- 图中样例为获取接口中数组元素第一个,并取到第一个属性对象下的 object 中的属性作为字段相对路径设置,即将接口数据取出赋值到这个路径下的字段中。
- 数据起始路径缺省:
Kafka
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个Kafka 数据源。点击 “新建数据源” 按钮开始新建数据源。
- 进入新建数据源页面,下拉选择Kafka数据源类型后填写目标数据源信息,用来作为FTP导入的来源。
- 填写项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API、ElasticSearch、FTP,这里我们选择FTP;
- 名称:必填项,根据业务实际场景填写数据源名称;
- 归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- 部署模式:必填项,下拉选择单机模式(Standalone)或集群模式(Shard Cluster);
- 成员:若选择单机模式,则继续填写下方数据源地址和端口;若选择集群模式,则可分别填写各成员的地址和端口;
- 数据源地址:必填项,根据根据业务实际场景填写数据源地址;
- 端口:必填项,根据根据业务实际场景填写端口;
- SASL认证:非必填,下拉选择加密方式SASL_PLAINtext、SCRAM-SHA-256或SCRAM-SHA-512,不填写时默认无认证,无需填写用户名与密码;
- 用户名:必填项,输入目标数据库连接用户名;
- 密码:必填项,输入目标数据库连接密码;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 描述:非必填,对此数据源作用或其他方面信息进行描述。
FTP
- 进入资源管理 > 数据源管理界面,即进入数据源管理页面,假设我们要注册一个FTP数据源。点击 “新建数据源” 按钮开始新建数据源。
- 进入新建数据源页面,下拉选择FTP数据源类型后填写目标数据源信息。
- 填写项说明:
- 类型:必填项,下拉选择,包含 HexaDB、MySQL、Oracle、PostgreSQL、SQL Server、DM、KingbaseES、HighGo、Kafka、MongoDB、API、ElasticSearch、FTP,这里我们选择FTP;
- 名称:必填项,根据业务实际场景填写数据源名称;
- 数据源归属方:必填项,根据实际业务场景填写数据源归属方;
- 责任人:必填,新建时默认为当前用户,仅空间管理员可修改;注意
若开启“资源权限管控”,数据源信息仅责任人可修改,其他有数据源修改权限的用户也不可修改非自身负责的数据源。
- 协议:单选,支持SFTP和FTP两种;
- 模式:需填写,当前仅支持被动模式,即由平台向数据源服务器发起请求;
- 主机地址:必填项,根据根据业务实际场景填写数据源的主机地址;
- 端口:必填项,根据根据业务实际场景填写端口;
- 用户名:必填项,输入目标数据库连接用户名;
- 认证方式:必填项,仅协议为SFTP时可选择认证方式,包括密钥认证和密码认证;FTP协议无认证方式配置,仅支持密码认证;
- 密钥:若选择SFTP的密钥认证,则必填,可直接将密钥复制至输入框;注意
此处填写为私钥,需在FTP服务器上生成对应私钥。
- 密码:必填项,输入目标数据库连接密码;
- 连接超时时间:必填项,默认60秒,最大可设置为600秒;以控制平台与FTP建立连接最大时长,超过时长自动终止;
- 数据源分类:非必填,下拉选择开发环境或生产环境,配置数据源分类后,作业试运行时选用开发环境版,正式运行选用生产环境;
- 描述:非必填,对此数据源作用或其他方面信息进行描述。
相关连接配置
数据源驱动
使用场景:用户使用同一类型数据库的不同版本时,需要不同的数据库连接驱动,保证数据库连通成功。
使用角色:数据集成人员、数据开发人员。
功能描述:平台支持管理自定义数据源驱动,新建数据源时可选择已创建的自定义驱动,以保证连通成功。
进入资源管理 > 数据源管理界面,点击界面上方的“数据源驱动”按钮,再点击新弹窗页面左上方“新建驱动”按钮,在新建驱动弹窗中填写界面信息项后点击右下角“保存”按钮即可。
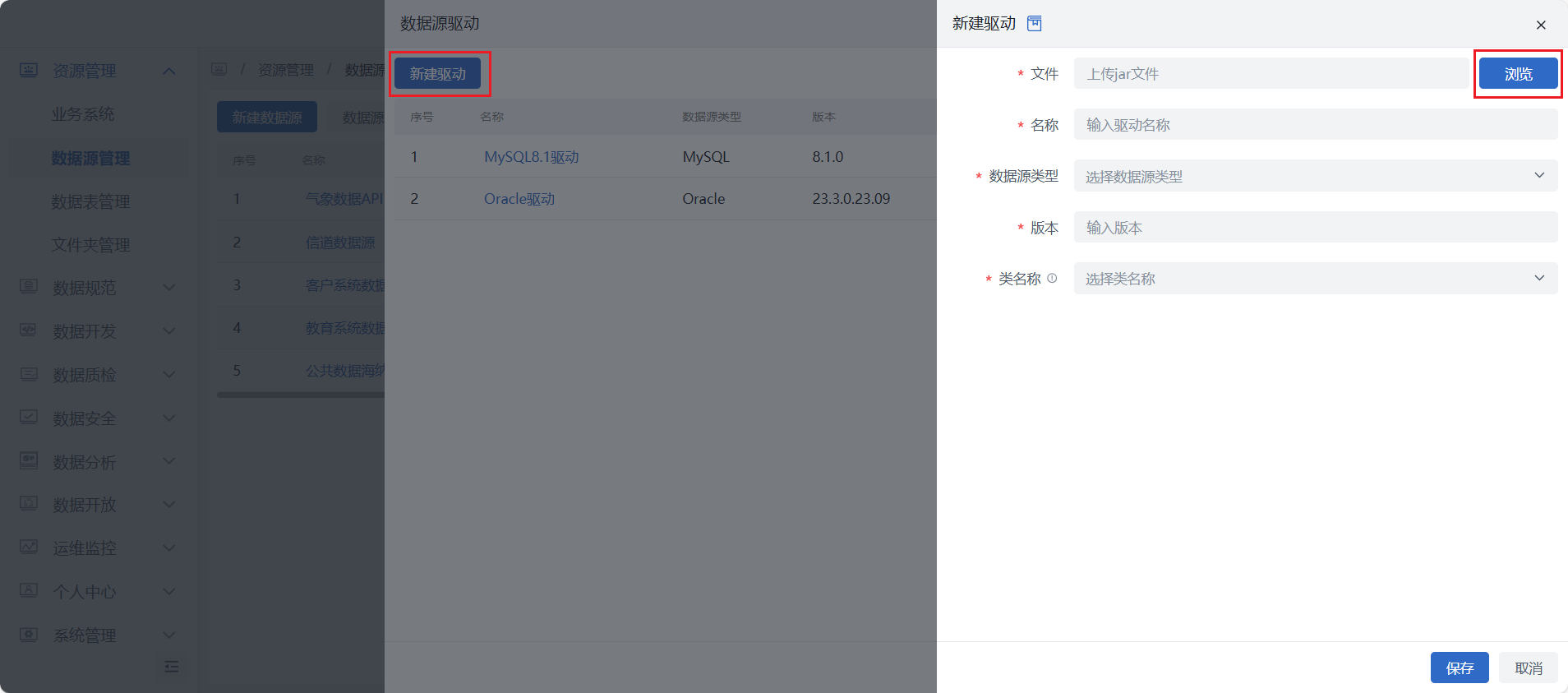
填写项说明
驱动名称:根据实际业务场景填写驱动名称;
驱动文件:仅支持 JDBC 驱动文件,文件格式为 '.jar',大小不超过200M;
数据源类型:下拉选择当前支持的七种目标库类型,即 MySQL、SQL Server、PostgreSQL、Oracle、DM(达梦)、KingbaseES(人大金仓)、HighGo(瀚高);
版本:自动解析驱动文件适用的数据源版本,可手动修改;
类名称:根据实际业务场景选择类名称。
注意不同数据库类型的驱动支持类名称如下:
- MySQL默认驱动: ['com.mysql.cj.jdbc.Driver'(适用于6.0以上版本),'com.mysql.jdbc.Driver'(适用于6.0以下版本)]
- Oracle默认驱动: 'oracle.jdbc.OracleDriver'
- 达梦默认驱动: 'dm.jdbc.driver.DmDriver'
- SQLServer默认驱动: 'com.microsoft.sqlserver.jdbc.SQLServerDriver'
- PostgreSQL默认驱动: 'org.postgresql.Driver'
- KingBaseES默认驱动: 'com.kingbase8.Driver'
- HighGo默认驱动: 'com.highgo.jdbc.Driver'
- HexaDB默认驱动: 'org.opengauss.Driver'
账号特殊字符处理
- 添加数据库直连账号密码中包含特殊字符时,可能造成连接失败,如密码中包含‘@’字符,这种情况需要对密码进行UrlEncoding,示例如下:
python 实例
from urllib.parse import quote_plus
from sqlalchemy import create_engine
username = 'your_username'
password = quote_plus('your@password') # URL encode the entire password
host = 'your_host'
port = 'your_port'
database = 'your_database'
connection_string = f'mysql+pymysql://{username}:{password}@{host}:{port}/{database}'
engine = create_engine(connection_string)
# Now you can use the engine to connect to the database
connection = engine.connect()
# Don't forget to close the connection
connection.close()
Java 实例
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DatabaseConnection {
public static void main(String[] args) {
String username = "your_username";
String password = "your@password";
String host = "your_host";
String port = "your_port";
String database = "your_database";
try {
// URL encode the password
String encodedPassword = URLEncoder.encode(password, StandardCharsets.UTF_8.toString());
// Create the connection string
String connectionString = String.format("jdbc:mysql://%s:%s@%s:%s/%s", username, encodedPassword, host, port, database);
// Connect to the database
Connection connection = DriverManager.getConnection(connectionString, username, password);
// Do something with the connection
System.out.println("Connected to the database!");
// Close the connection
connection.close();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试连通性
使用场景:用户对已配置的数据源信息进行连通性测试,以保证配置正确,可正常连通。
使用角色:数据集成人员、数据开发人员。
功能描述:平台支持一键测试数据源是否与平台连通,并可查看最近一次连通情况及失败原因。
进入资源管理 > 数据源管理界面,对数据源进行测试连通性的方式有三种:
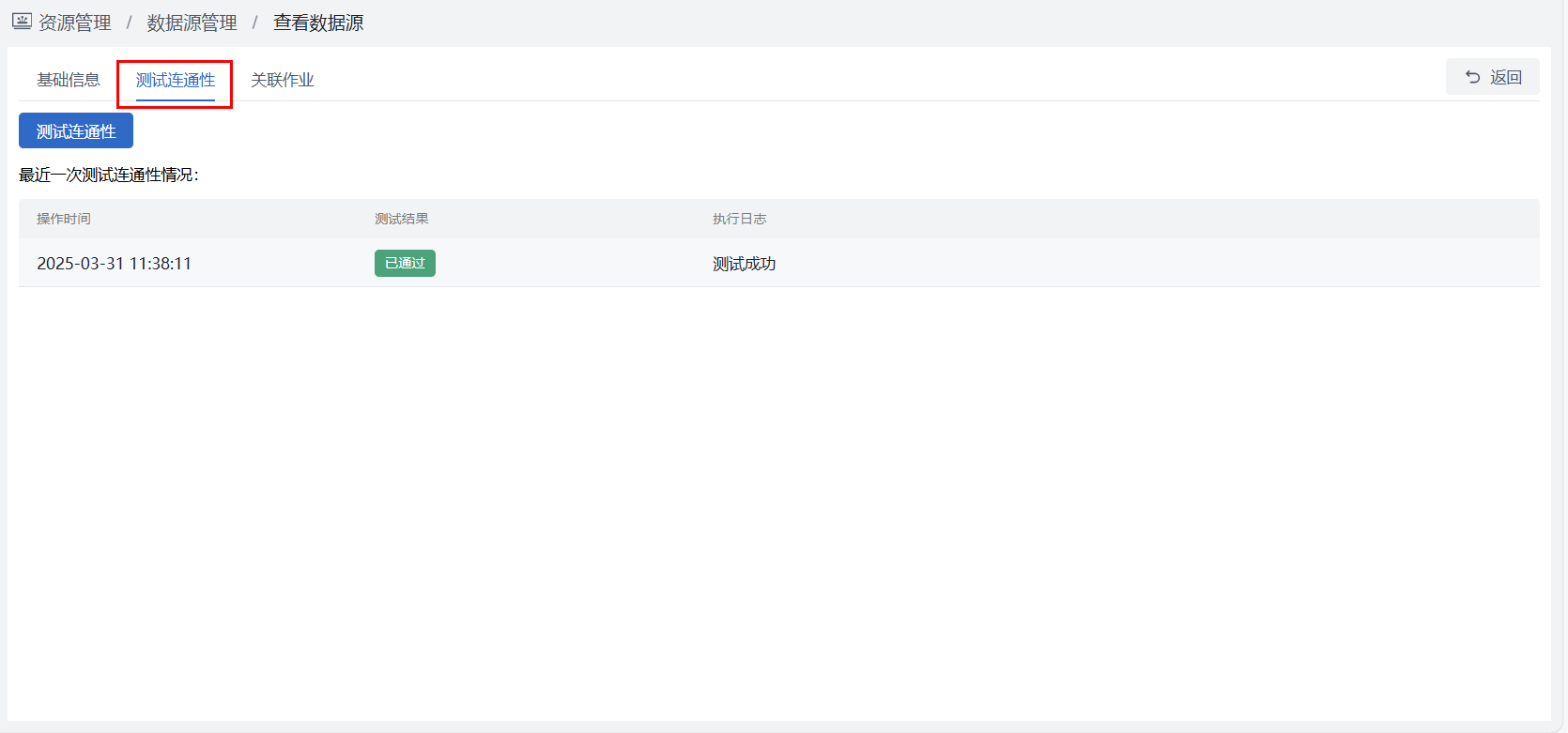
- 点击“数据源名称”链接后进入查看界面的“测试连通性”按钮。
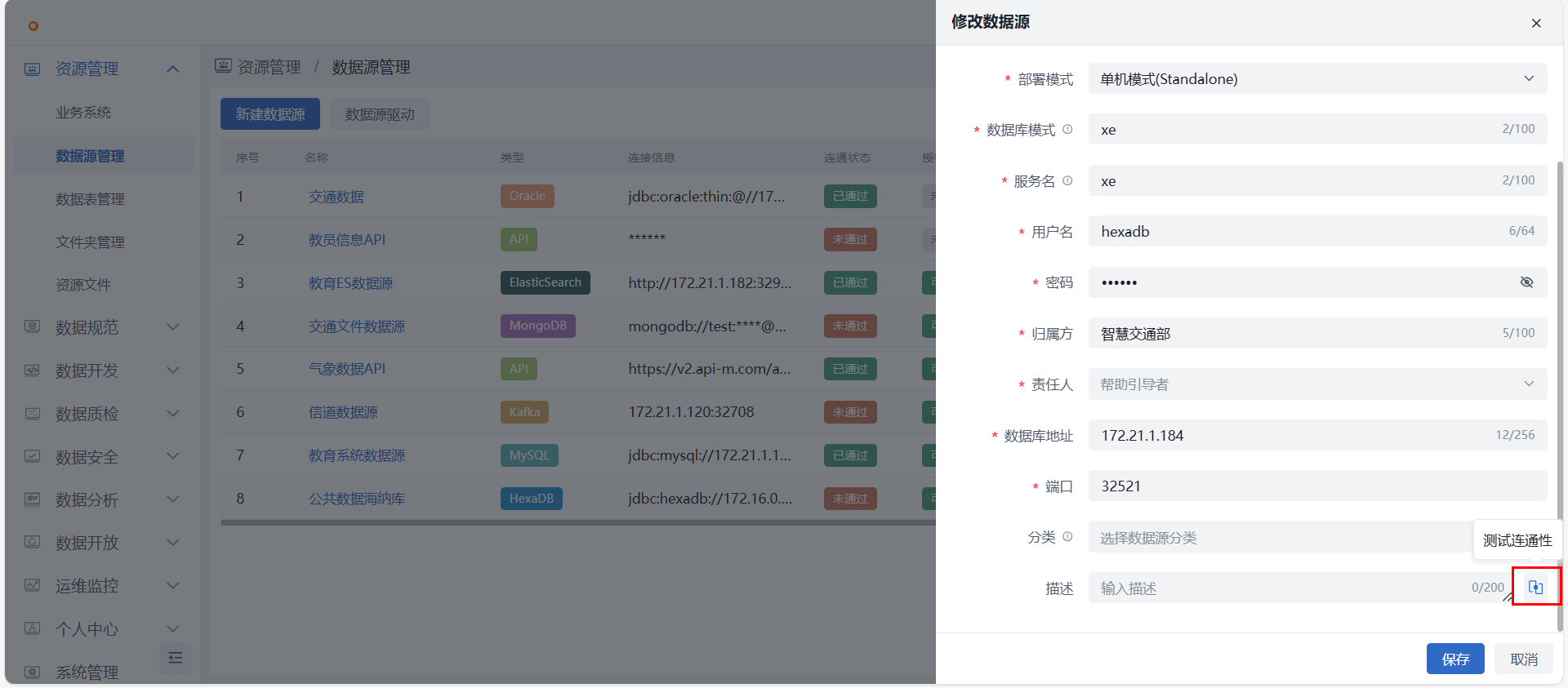
- 点击“修改”按钮后弹出界面底部的“测试连通性”按钮。
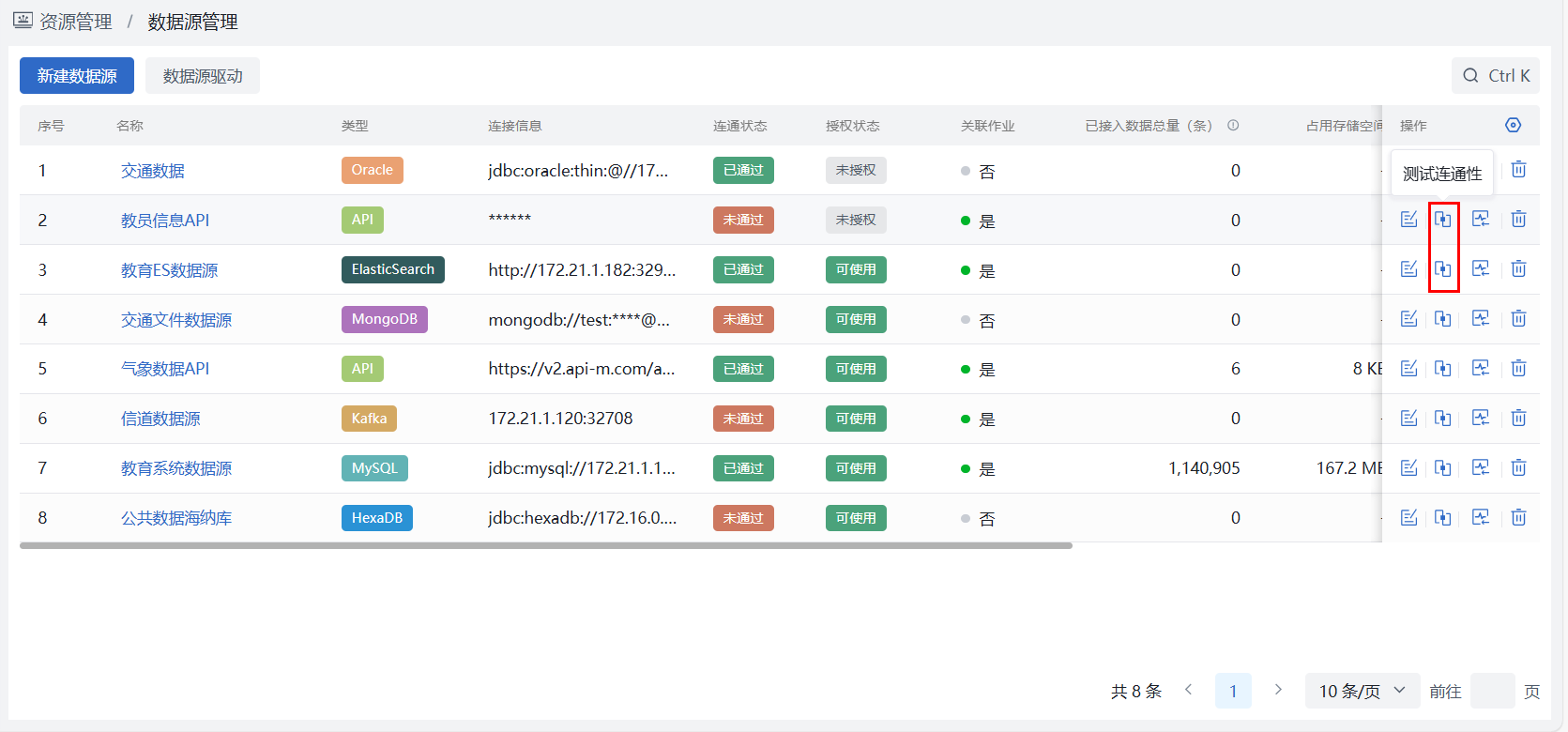
- 数据源列表操作列“测试连通性”按钮。
新建、修改时在弹窗内测试连通性,不计入数据源查看页面中的最近一次测试连通性情况。
相关维护配置
资源权限
授权使用:若已开启“资源权限管控”,使用以下功能时只可选择有资源权限的数据源,授权操作详见权限管理-资源权限
库表导入:来源库,无资源权限数据源过滤不可见
库表导出:目标库,无资源权限数据源过滤不可见
API导入:来源API,无资源权限API数据源过滤不可见
信道作业:来源topic,无资源权限Kafka数据源的topic过滤不可见;外部目标库,无资源权限数据源过滤不可见(同理,新建topic时也过滤无资源权限的Kafka数据源)
实时同步:来源库,无业务权限数据源过滤不可见
回显:查看/修改无权限数据源节点/作业,正常回显数据源、数据表、字段信息,但无法保存
权限回收:当数据源资源权限回收,相关作业下次调度运行失败,作业编辑页面会提示无资源权限(当前正在运行作业在收回时决定是否终止)
修改
- 拥有数据源修改系统权限可修改数据源,但不可修改数据源类型
- 若已开启“资源权限管控”,拥有数据源修改系统权限的用户不可修改非自身负责的数据源
- 数据源配置修改后,已关联的作业在下个调度周期执行时,将使用最新的数据源配置
删除
- 拥有数据源删除系统权限可删除数据源
- 若已开启“资源权限管控”,拥有数据源删除系统权限的用户不可删除非自身负责的数据源
- 若数据源已关联作业,需先解除作业的关联后再进行删除操作
接入流量监控
数据源管理列表展示所有已注册数据源的接入和连通情况,以及已接入数据总量、占用存储空间等信息,并支持点击查看“接入流量监控”。
- 接入流量监控:点击展示每个数据源近30次接入情况,数据源中任一数据表成功完成一次接入即参与统计。