加工节点
平台提供了多种数据加工节点,以满足数据集成、开发的需要,用户可根据所需选择对应节点拖至作业画布完成配置即可,同一节点类型可添加多个,但名称不可重复。
节点分类
库表导入
使用场景:用户通过数据表的库表集成能力,实现数据的复制迁移,提升资产同步便捷性和效率。
使用角色:数据开发人员。
功能描述:平台可将多种类型的第三方来源数据库数据导入至平台进行加工。
前置条件:用户已创建好加工作业并且画布中配有库表导入节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行库表导入操作的加工作业,在画布中双击“库表导入”节点,跳转至库表导入操作界面。根据页面内容填写相关信息后点击“保存”按钮,待系统校验通过后即可创建成功。
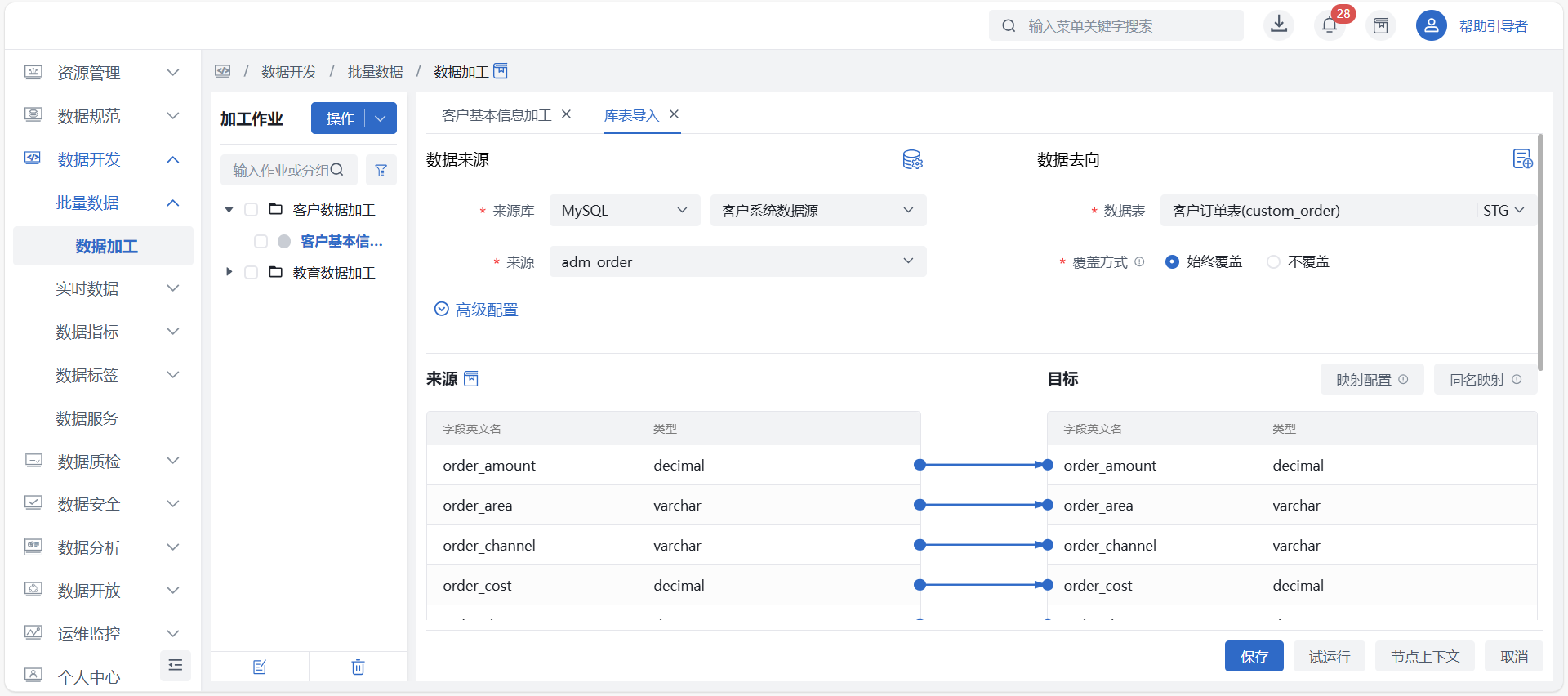
数据来源
- 来源库:必选,下拉选择数据来源数据库;
注意- 若已开启“资源权限管控”,则来源数据库不再展示当前操作用户无权限的数据源
- 库表导入不支持选择API、Kafka、ElasticSearch类型数据源
- 来源:必填,联动选择所选来源库中的数据表、文档;
高级配置
并发数:非必填,默认为5,最大15;主键(不支持联合主键)数据类型为整型时,可配置并发数提升数据集成速度,反之并发数不可配。
注意- 设置并发数后会在运行时按所设数量并发执行,但效率提升不是简单的线性相乘,会受多方面因素影响,如初始并发5,设置为10后,速度不会直接提升至2倍,可能在1.5-2倍之间。
- 并发数过高可能对来源库造成过大压力,导致链接失败,请谨慎设置并发数值。
同步速率:默认不限流,选择限流后可填写限流上限值,单位MB/s,值域为1-1000正整数;此处限流速率为总体传输速率,当存在并发时会按并发数进行平均分配,如限流10MB/s,5个并发,则每个并发分片的上限为2MB/s。
注意限流实际速率可能在所填数值附近上下波动。
读写失败上限:非必填,设置可容忍读写失败条数,达到阈值后作业将自动置为失败,默认为0,即不允许失败。
失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
批获取量:控制单次从数据库获取数据的行数(fetchSize),单次获取量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值1000。
批提交量:控制单次提交写入数据的行数(batchSize),单次提交量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值2048。
运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
数据过滤:非必填,填写后可通过过滤语句实现增量复制,支持引用参数,例如系统时间、函数变量等。
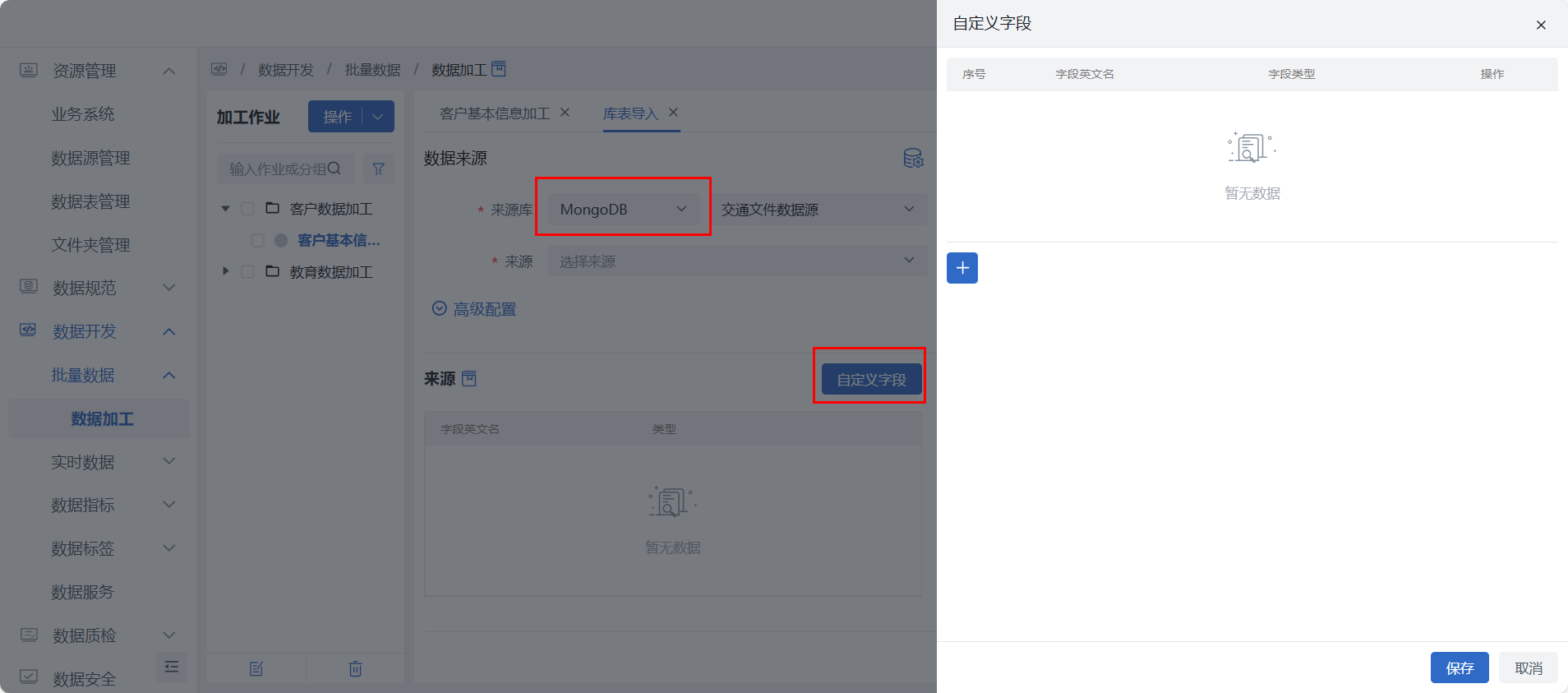
自定义字段:当数据源类型为MongoDB时,可手动添加自定义字段,以免自动解析字段存在遗漏。
数据去向
- 数据表:必填,选择当前空间中数据表管理中数据表;
- 覆盖方式:必选,单选始终覆盖或不覆盖,默认选择始终覆盖;选择不覆盖则无论增量数据是否为空,均不覆盖;选择始终覆盖则无论增量数据是否为空,均进行覆盖。 注意
覆盖逻辑举例如下:
- 始终覆盖:第一次导入10条数据,第二次导入前会自动清空已有数据,第二次导入20条数据,则数据表中最终只会有第二次导入的20条数据;
- 不覆盖:第一次导入10条数据,第二次导入20条数据,则数据表中最终会有第一次+第二次导入的30条数据;不覆盖采用追加逻辑,即不会对相同数据增量更新,因此可能存在重复数据。
- 快速创建与来源表相同结构的表:若无目标表,点击数据去向右侧该功能按钮,可自动填充来源表元数据信息以快速创建数据表。
- 若开启业务权限管控,目标表会自动过滤掉当前操作用户无读写权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 目标表不可选择其他空间授权的跨空间数据表。
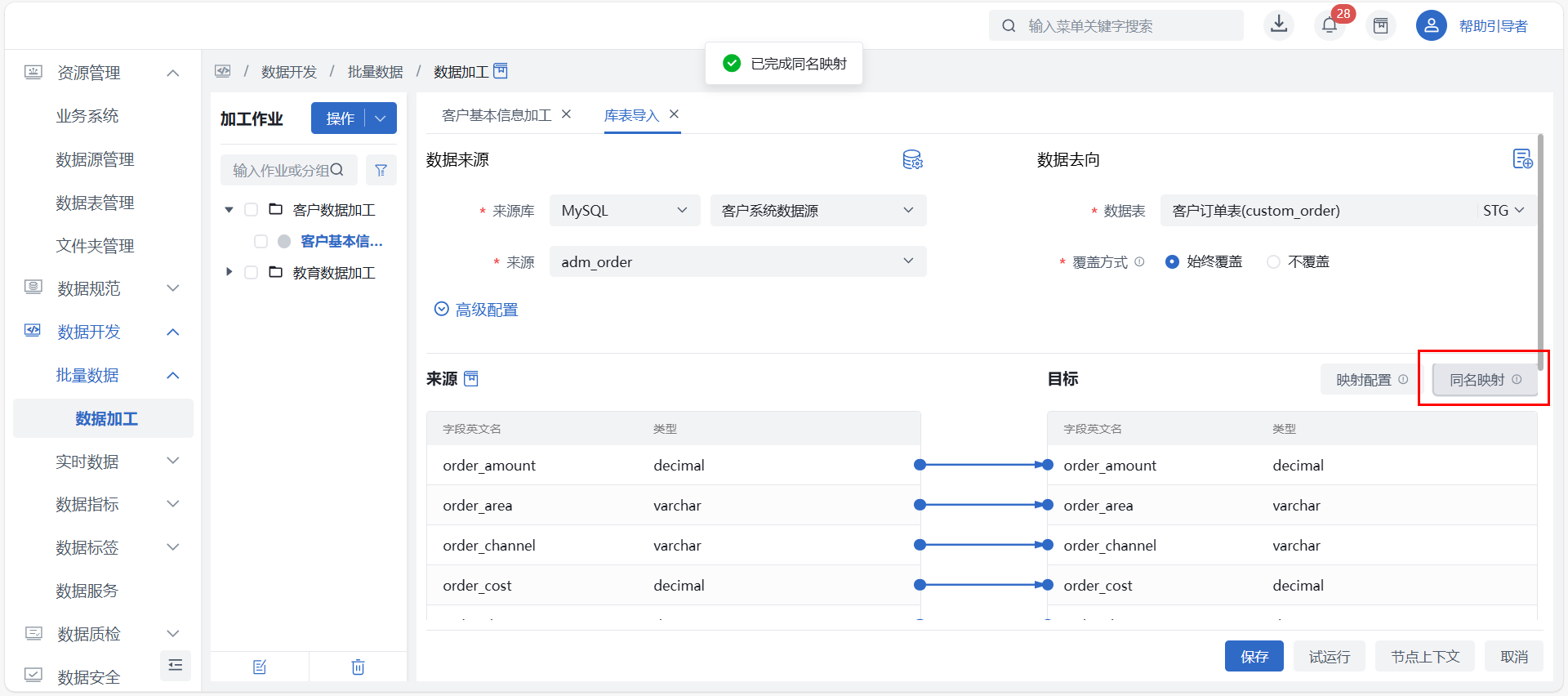
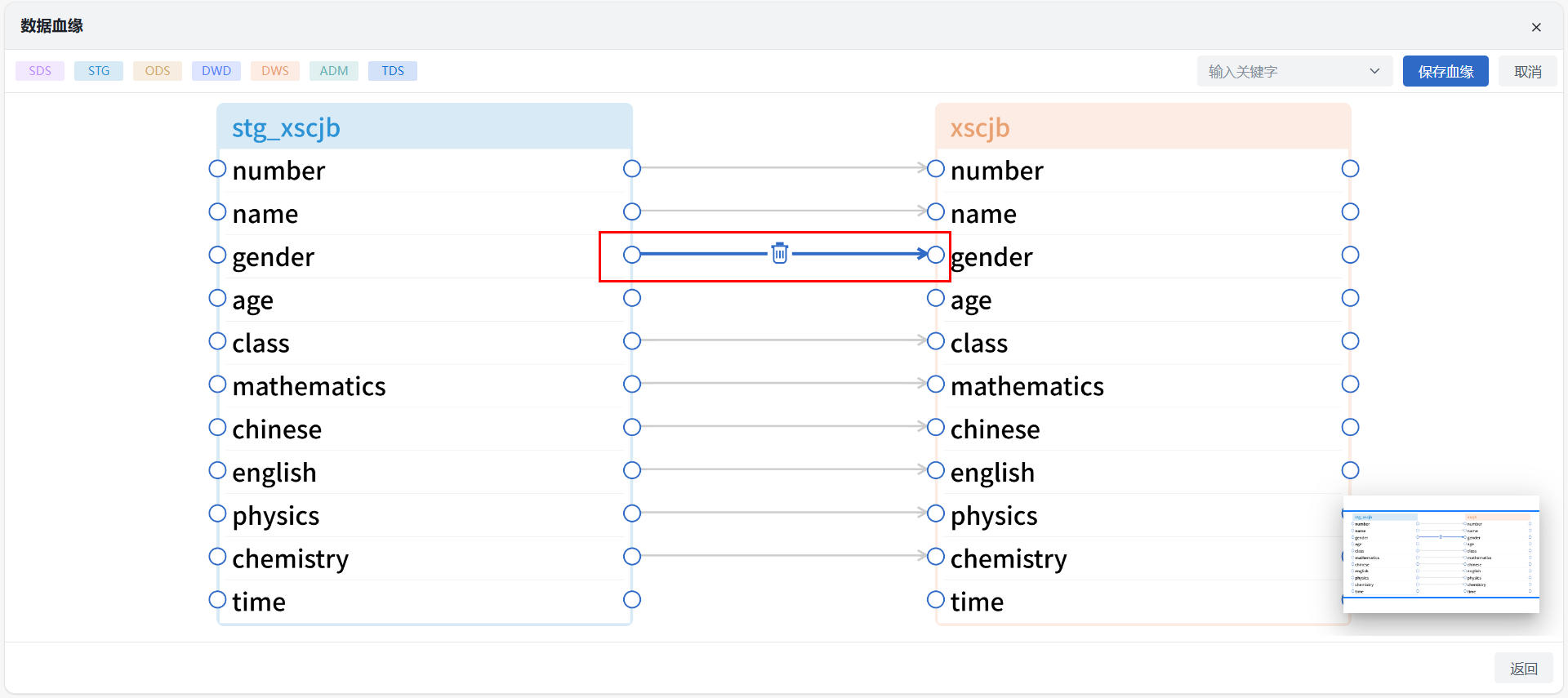
同名映射
当两个字段的英文名(不分大小写)相同且字段类型兼容时,定义为同名字段。用户可通过点击页面内的 “同名映射” 按钮一键自动映射同名字段。
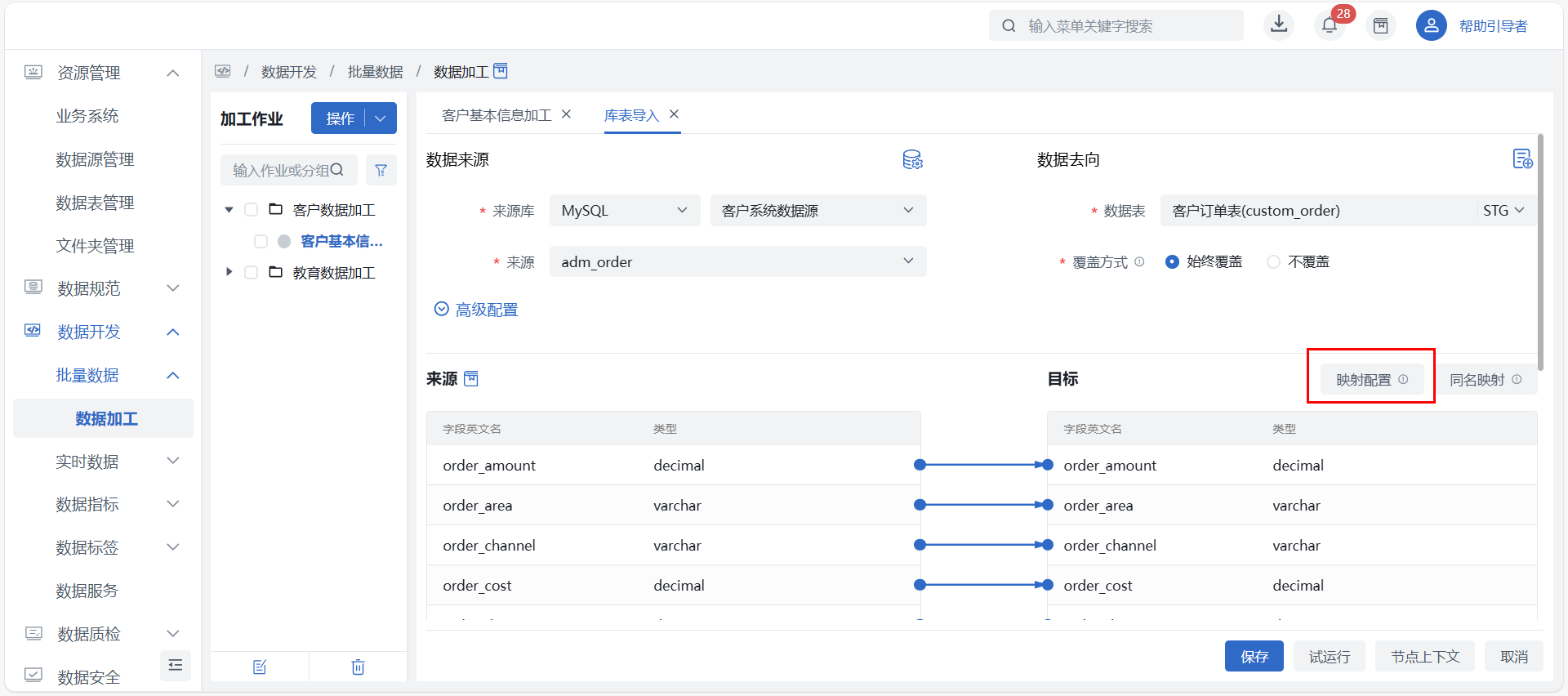
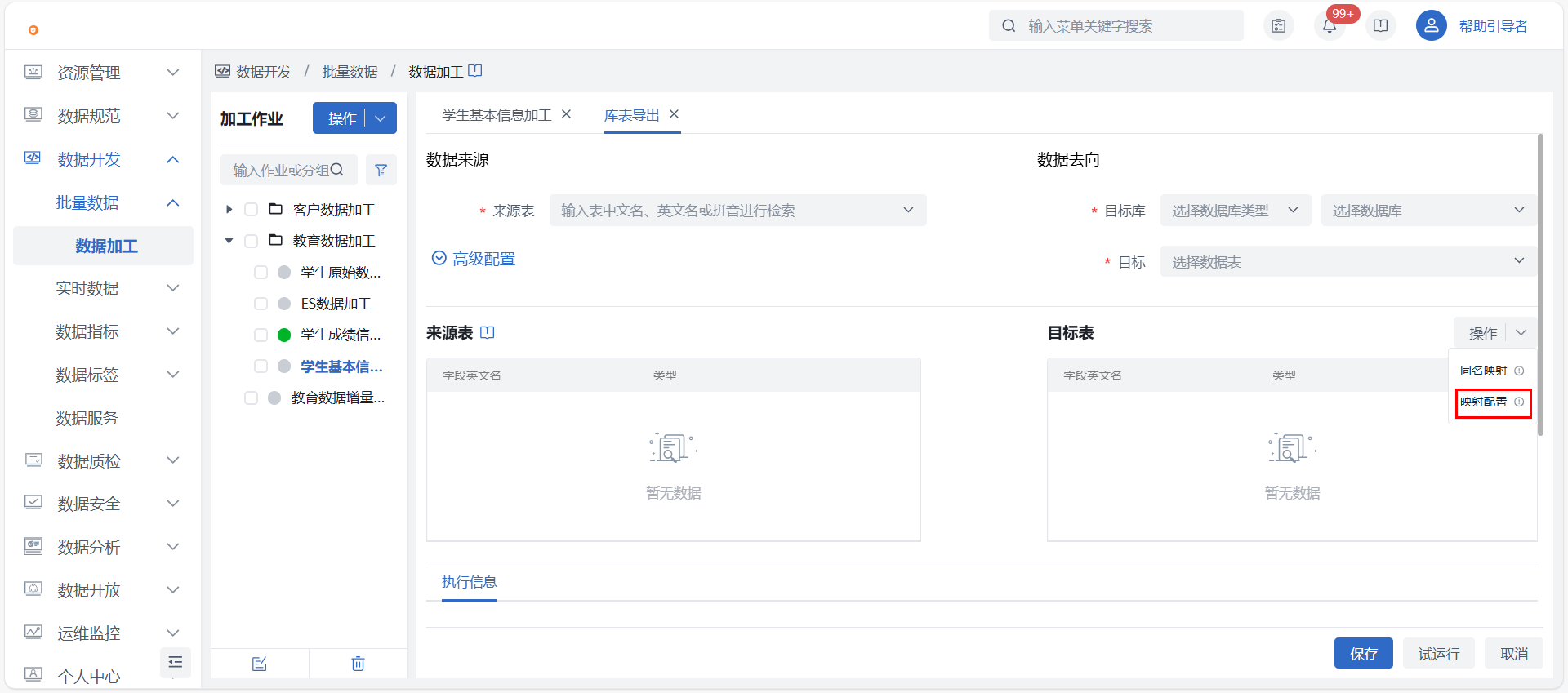
映射配置
点击页面上的 “映射配置” 按钮可进行两端字段的选择,配置当前未连线字段的映射关系。
同时用户也可通过手动连线进行来源表与目标表的字段配置。目标表中不可连接字段系统会自动提示,方便用户判断。
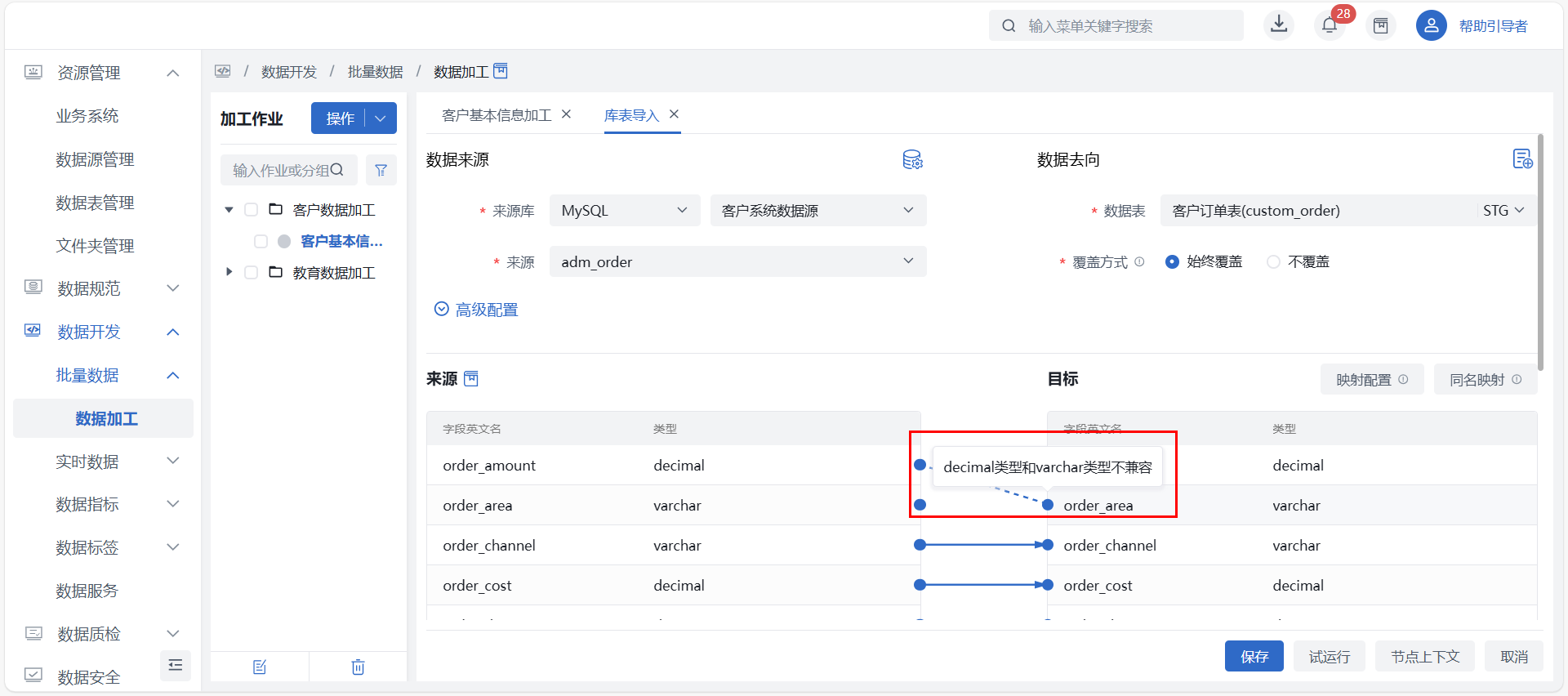 注意
注意不兼容字段类型将无法自动、手动连线映射,内置兼容类型详见:字段类型兼容说明。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
说明:当前节点类型仅支持传递参数,暂无法引用。试运行
用户完成来源表与目标表相关配置后,可点击页面右下方的“试运行”按钮,提前测试来源表与目标表配置是否正确。
试运行逻辑:试运行系统将抽样 1000 条导入至临时表中,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。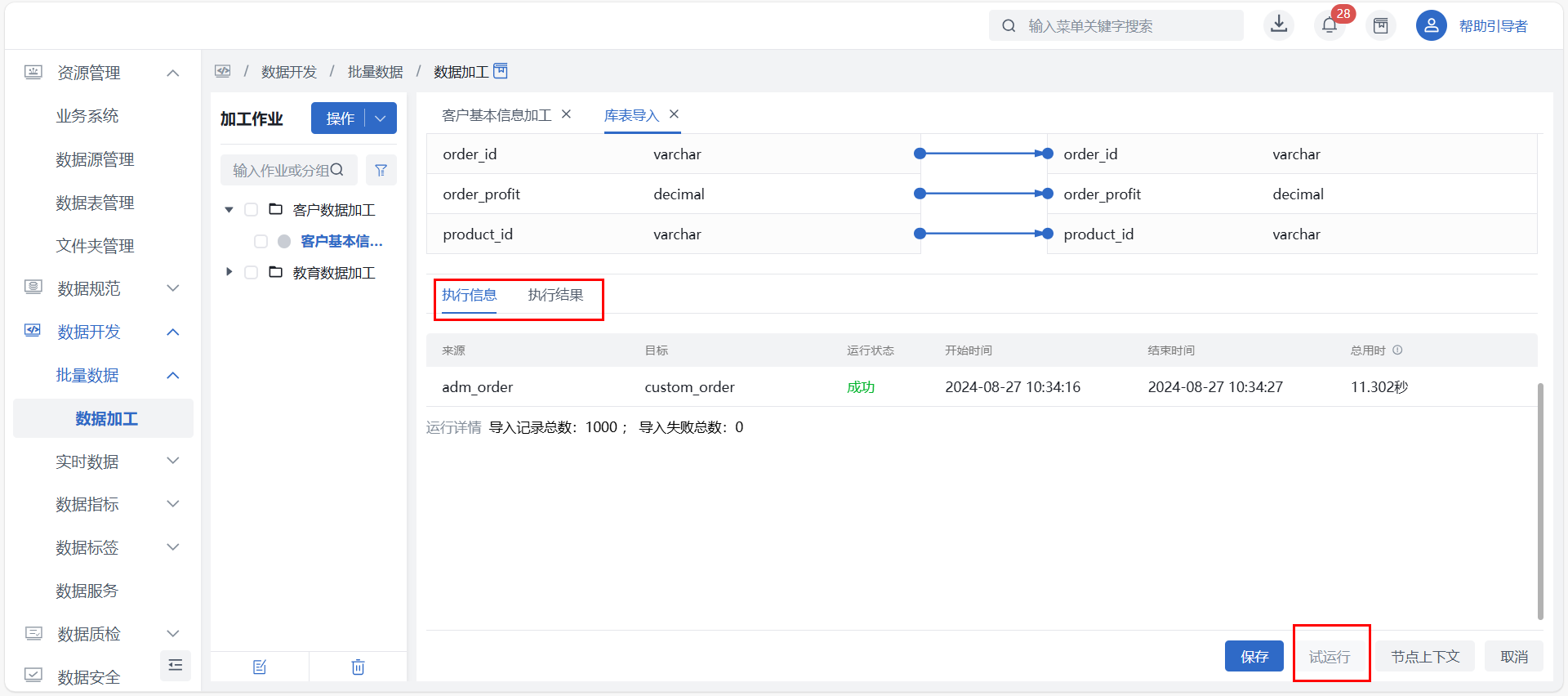
若选择 MongoDB 数据库,数据过滤语法可能存在差异,MongoDB过滤语法说明如下:
- 逻辑运算符

比较运算符
- $gt: 如果请求的值“大于”查询中提供的值,则匹配;
- $gte: 如果请求的值“大于或等于_”,则匹配查询中提供的值;
- $lt: 如果请求的值是“小于”,则匹配查询中提供的值;
- $lte: 如果请求的值是“小于或等于_”,则匹配查询中提供的值。
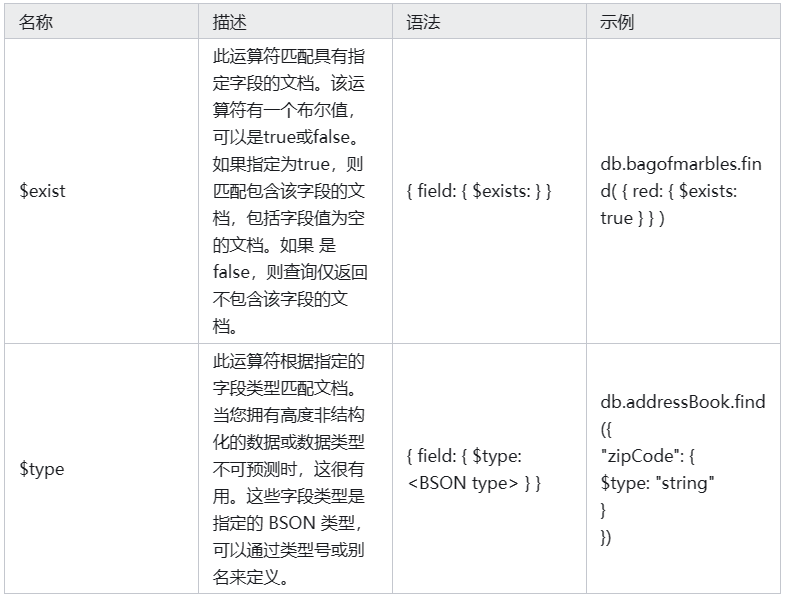
元素运算符
元素查询运算符可以使用文档的字段来识别文档。元素运算符由$exist和$type组成。
- 数组运算符

批量库表导入
使用场景:用户通过批量数据表集成能力,可快速选择多张表进行集成,提升集成配置与管理效率。
使用角色:数据开发人员。
功能描述:平台可将第三方来源数据库多张表数据批量导入至画布进行加工。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行批量库表导入操作的加工作业,在画布中双击“批量库表导入”节点,跳转至库表导入操作界面。根据页面内容填写相关信息后点击“保存”按钮,待系统校验通过后即可创建成功。
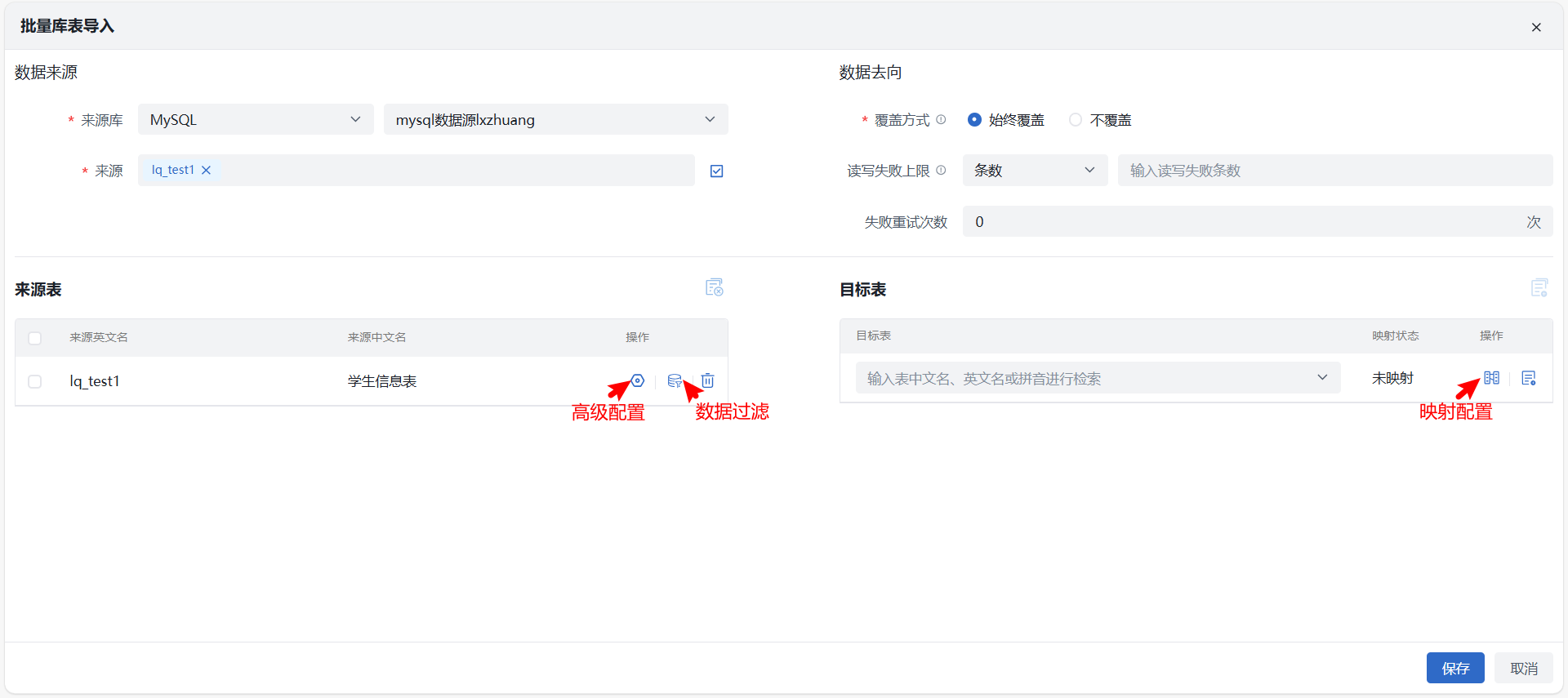
数据来源
- 数据源:可选择数据库数据源,选择 MongoDB 数据库后,会通过抽样自动解析文档字段,数据过滤将隐藏不显示;注意
- 若已开启“资源权限管控”,则来源数据库不再展示当前操作用户无权限的数据源
- 库表导入不支持选择API、Kafka、ElasticSearch类型数据源
- 来源表:支持多选,最多30张表格,多次选择增量更新已选表;
- 并发数:非必填,默认为5,最大15;主键(不支持联合主键)数据类型为整型时,可配置并发数提升数据集成速度,反之并发数不可配,需每个来源表独立配置。
- 同步速率:默认不限流,选择限流后可填写限流上限值,单位MB/s,值域为1-1000正整数;此处限流速率为总体传输速率,当存在并发时会按并发数进行平均分配,如限流10MB/s,5个并发,则每个并发分片的上限为2MB/s。
- 读写失败上限:非必填,设置可容忍读写失败条数或比例,达到阈值后作业将自动置为失败,默认为0,即不允许失败。
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 批获取量:控制单次从数据库获取数据的行数(fetchSize),单次获取量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值1000。
- 批提交量:控制单次提交写入数据的行数(batchSize),单次提交量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值2048。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
- 数据过滤:非必填,填写后可通过过滤语句实现增量复制,支持引用参数,例如系统时间、函数变量等,可对单表进行配置。
- 批量删除已选表:仅从下方列表中批量删除已选表。
- 数据源:可选择数据库数据源,选择 MongoDB 数据库后,会通过抽样自动解析文档字段,数据过滤将隐藏不显示;
数据去向
覆盖方式:必选,单选始终覆盖或不覆盖,默认选择始终覆盖。当用户选择不覆盖则无论增量数据是否为空,均不覆盖;当用户选择始终覆盖则无论增量数据是否为空,均进行覆盖。
注意覆盖逻辑举例如下:
- 始终覆盖:第一次导入10条数据,第二次导入前会自动清空已有数据,第二次导入20条数据,则数据表中最终只会有第二次导入的20条数据;
- 不覆盖:第一次导入10条数据,第二次导入20条数据,则数据表中最终会有第一次+第二次导入的30条数据;不覆盖采用追加逻辑,即不会对相同数据增量更新,因此可能存在重复数据。
目标表:支持单表或勾选批量创建平台表;创建逻辑与已有一致,多表以多标签页展示;
查看映射:默认自动进行同名映射,查看可进行手动修改;
批量创建目标表:
- 勾选左侧来源表后,可点击批量创建目标表;
- 以多个页签进行创建,每个页签逻辑同现有“创建目标表”单表创建,并已自动填充来源表元数据信息;
- 批量建表完成保存后,可自动刷新填充数据库表和源表对应起来,并自动进行同名映射。
- 若开启业务权限管控,目标表会自动过滤掉当前操作用户无读写权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 目标表不允许选择相同的表,即不允许将左侧多张表导入到右侧同一张表;
- 目标表不可选择其他空间授权的跨空间数据表。
- 保存
用户完成相关配置保存后,会根据将每一组“来源表-目标表”分别创建一个库表导入节点,后续可独立维护。
API导入
使用场景:用户通过可视化配置将API数据直接写入至平台数据表,提升资产同步便捷性和效率。
使用角色:数据开发人员。
功能描述:平台提供API集成能力,以API导入的方式将API数据集成至平台,并可周期调度持续写入API数据进行加工。
前置条件:用户已创建好加工作业并且画布中配有API导入节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行 API 导入操作的加工作业,在画布中双击 “API导入” 节点,跳转至 API 导入操作界面。根据页面内容填写相关信息后点击 “保存” 按钮,待系统校验通过后即可创建成功。
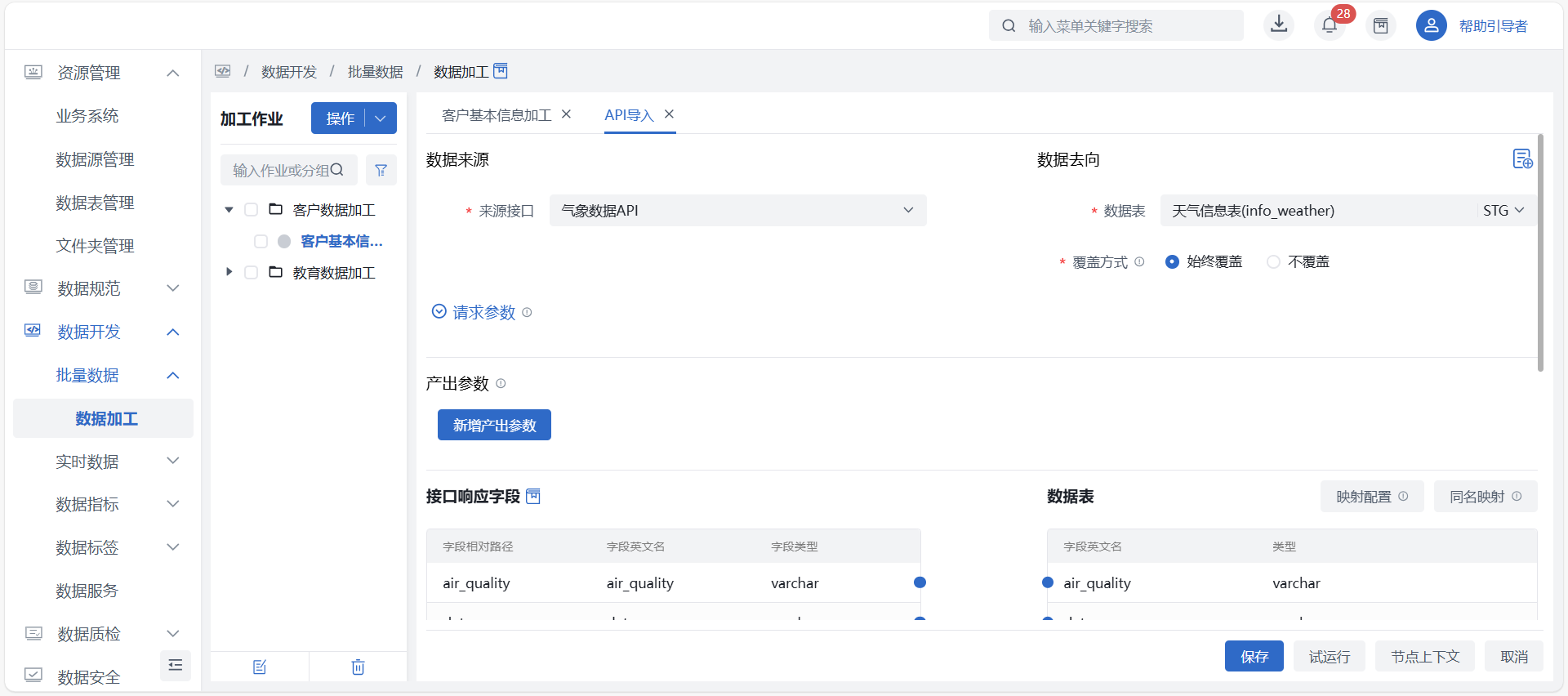
数据来源
- 来源接口:必填,下拉选择数据源管理中已配置的 API 数据源,选择后自动获取已解析的字段; 注意
- 若已开启“资源权限管控”,则来源接口不再展示当前操作用户无权限的API数据源
- 请求参数:点击后展开可新增请求参数配置,用于引用参数,获取参数值,作为本节点的执行输入,取值将覆盖 API 数据源对应参数的设置值;
- 参数名:默认空,选择来源参数后自动填充为所选参数名,可修改;
- 来源类型:选择作业变量或本地变量;
- 来源参数:作业变量选择当前作业已配置作业参数名;本地变量则选择由上游传递而来的参数;
- 传参方式:url、header、body三种类型;
- 引用时,将根据参数类型确定引用覆盖位置,取值覆盖 API 数据源对应与请求参数一致的参数设置值;
- 接口响应字段:选择来源接口后,自动展示该接口解析配置中的所有字段,不支持修改删除;
- 来源接口:必填,下拉选择数据源管理中已配置的 API 数据源,选择后自动获取已解析的字段;
数据去向
数据表:必填,选择平台当前空间中数据表管理中 STG 层数据表;
快速创建与来源表相同结构的表:若无目标表可点击右侧该按钮,可快速自动带入API响应字段信息创建目标表。
覆盖方式:必选,单选始终覆盖或不覆盖,平台默认选择始终覆盖。当用户选择不覆盖则无论增量数据是否为空,均不覆盖;当用户选择始终覆盖则无论增量数据是否为空,均进行覆盖。
注意覆盖逻辑举例如下:
- 始终覆盖:第一次导入10条数据,第二次导入前会自动清空已有数据,第二次导入20条数据,则数据表中最终只会有第二次导入的20条数据;
- 不覆盖:第一次导入10条数据,第二次导入20条数据,则数据表中最终会有第一次+第二次导入的30条数据;不覆盖采用追加逻辑,即不会对相同数据增量更新,因此可能存在重复数据。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
- 若开启业务权限管控,目标表会自动过滤掉当前操作用户无读写权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 目标表不可选择其他空间授权的跨空间数据表。
同名映射
当两个字段的英文名(不分大小写)相同且字段类型兼容时,定义为同名字段。用户可通过点击页面内的 “同名映射” 按钮一键自动映射同名字段。
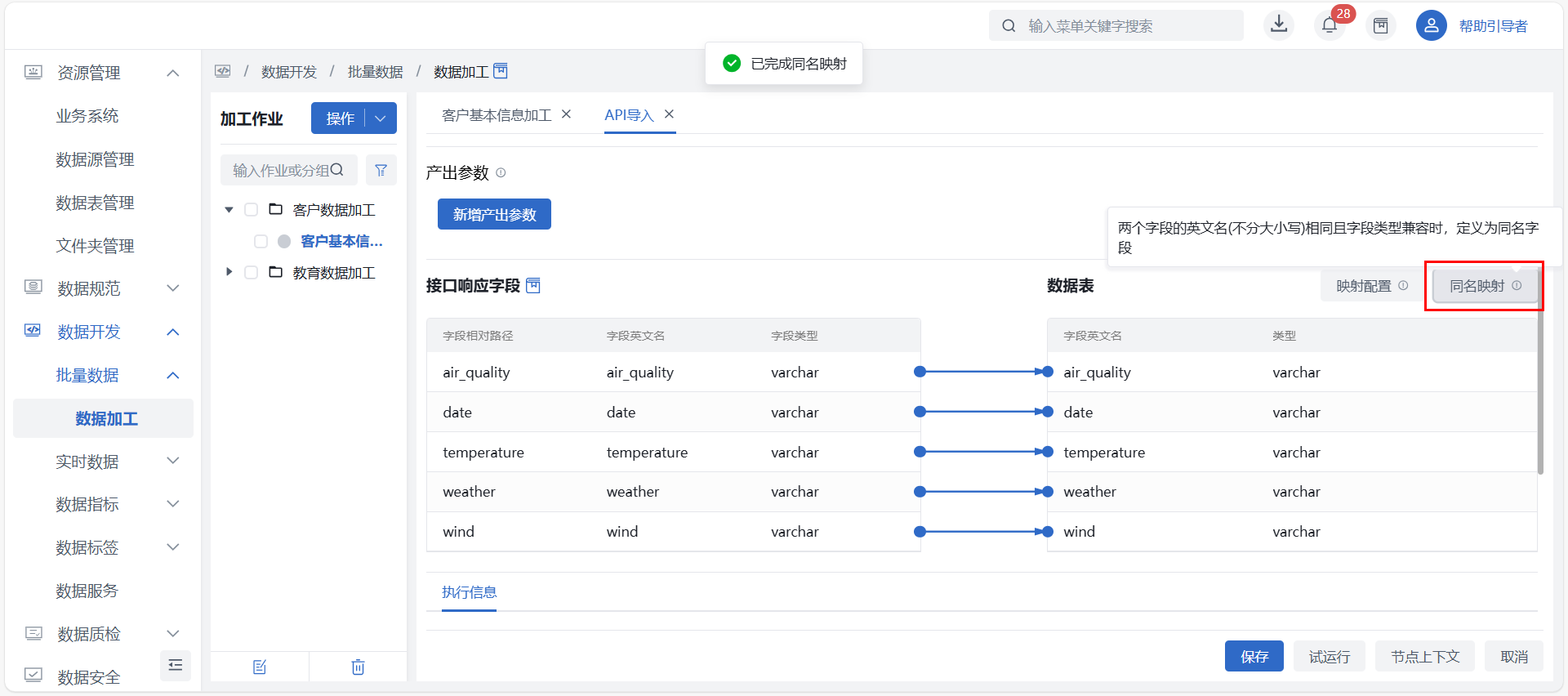
映射配置
点击页面上的 “映射配置” 按钮可进行两端字段的选择,配置当前未连线字段的映射关系。
同时用户也可通过手动连线进行来源表与目标表的字段配置。系统会自动将目标表中可连接字段连接点变为空心圆,方便用户判断。
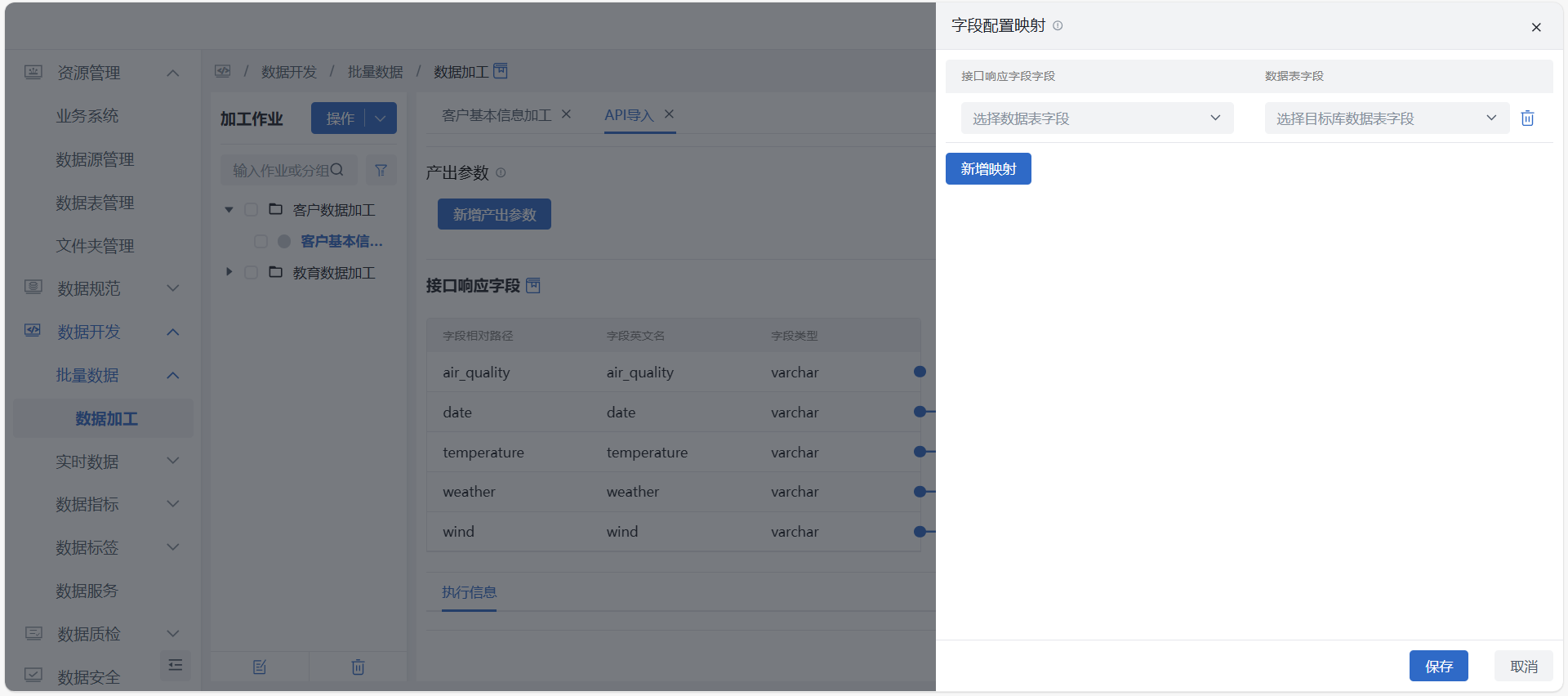
不兼容字段类型将无法自动、手动连线映射,内置兼容类型详见:字段类型兼容说明。产出参数:可自定义本节点的输出参数,以供下游节点引用传参;
- 例如:本节点可选择调用某个认证API,将返回值中的令牌信息作为输出参数 token 传递给下游数据 API 节点引用;
- 新增产出参数:可选择字段作为产出参数,参数名列可将字段英文名做为参数名,或自行修改为所需的映射参数名(参数名同一作业内唯一);
节点上下文 点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
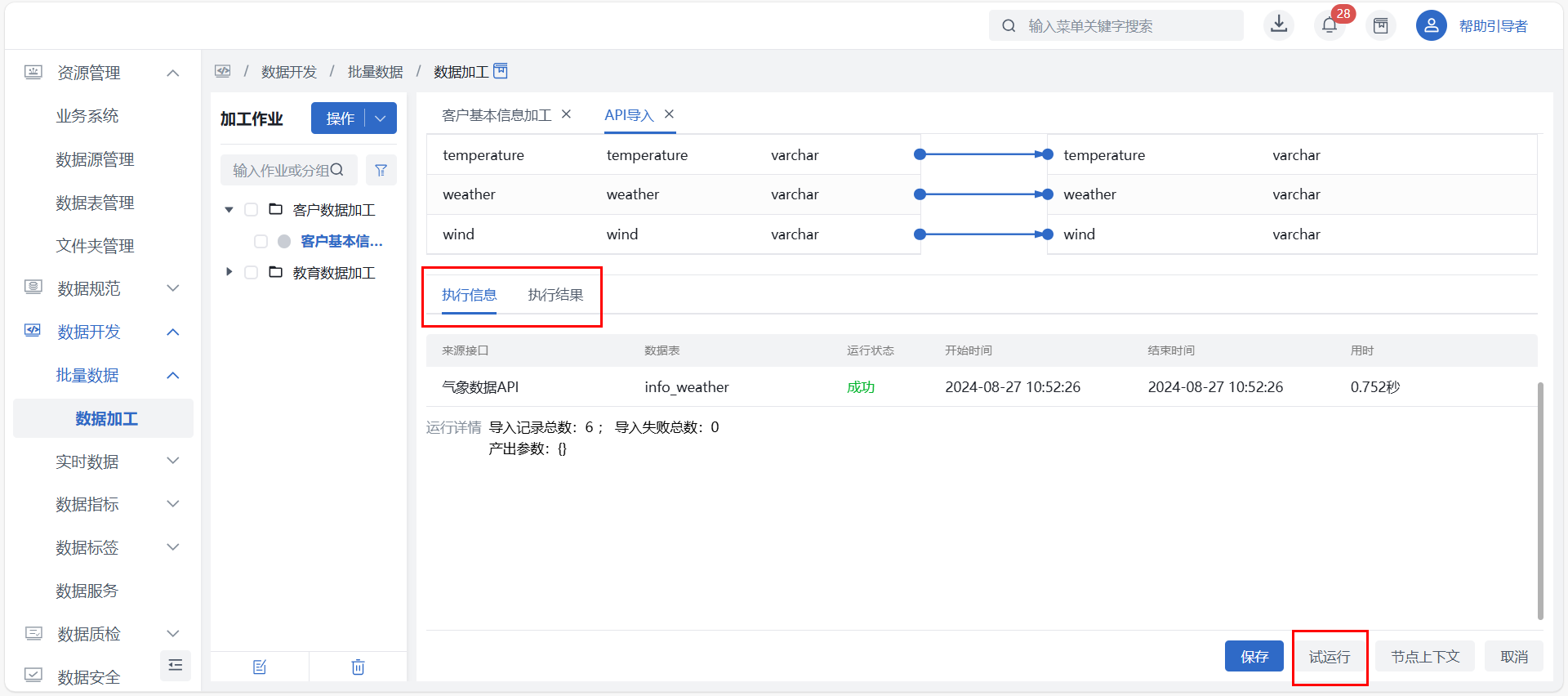
试运行
用户完成来源API与目标表相关配置后,可点击页面右下方的“试运行”按钮,提前测试来源API与目标表配置是否正确。
试运行逻辑:试运行系统将抽样 1000 条导入至临时表中,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。
脚本导入
使用场景:用户需将多接口嵌套等复杂接口数据导入至平台。
使用角色:数据开发人员。
功能描述:平台提供 JMeter 脚本的 API 导入能力,支持上传 JMeter 脚本,灵活写入数据。
前置条件:用户已创建好加工作业并且画布中配有脚本导入节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行脚本导入操作的加工作业,在画布中双击 “脚本导入” 节点,跳转至脚本导入操作界面。根据页面内容填写相关信息后点击 “保存” 按钮,待系统校验通过后即可创建成功。
在数据来源下拉框中选择 JMeter 脚本导入,点击上传,可上传 JMeter 脚本,若上传错误可点击“删除”,删除已上传脚本。
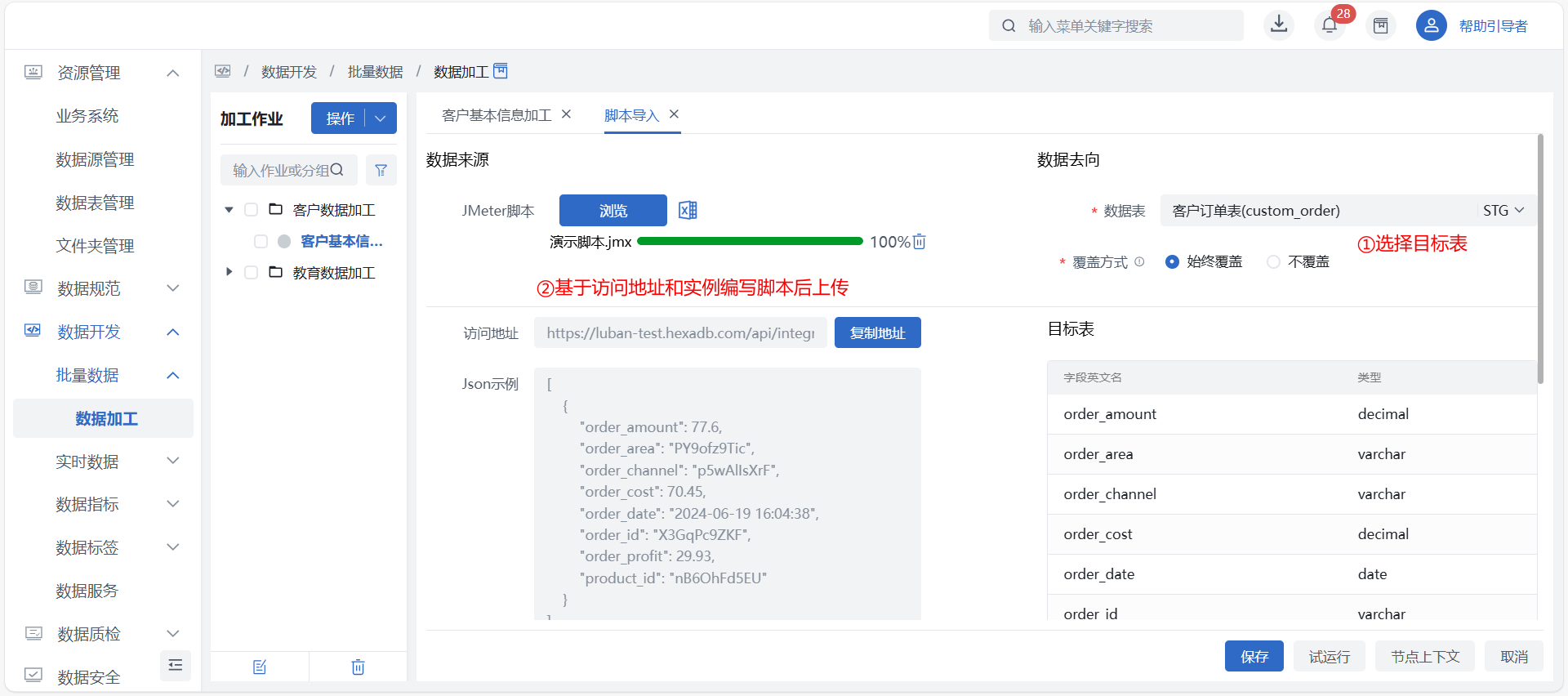
数据来源
- 访问地址:不可手动输入和修改,选择数据表后自动生成,地址包含通用地址、标识信息(自动拼接数据表及节点信息标识),且支持一键复制访问地址至剪切板;
- Json示例:选择平台表后自动生成,将平台表中所有字段组成Json示例数组,不可手动输入和修改,根据表中各字段类型,示例数据值将采用统一的示例:
- 字符型(varchar、char、text等):平台字符型json示例;
- 数值型(int、float、decimal等):66、3.14;
- 时间型(date、timestamp、timestamptz):2024-01-01 12:00:00。
数据去向
数据表:必填,选择平台当前空间中数据表管理中 STG 层数据表;
覆盖方式:必选,单选始终覆盖或不覆盖,平台默认选择始终覆盖。当用户选择不覆盖则无论增量数据是否为空,均不覆盖;当用户选择始终覆盖则无论增量数据是否为空,均进行覆盖。
注意覆盖逻辑举例如下:
- 始终覆盖:第一次导入10条数据,第二次导入前会自动清空已有数据,第二次导入20条数据,则数据表中最终只会有第二次导入的20条数据;
- 不覆盖:第一次导入10条数据,第二次导入20条数据,则数据表中最终会有第一次+第二次导入的30条数据;不覆盖采用追加逻辑,即不会对相同数据增量更新,因此可能存在重复数据。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
- 若开启业务权限管控,目标表会自动过滤掉当前操作用户无读写权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 目标表不可选择其他空间授权的跨空间数据表。
操作说明
- 保存:填写相关信息后点击 “保存” 按钮,待系统校验通过后即可创建成功,即使未上传 JMeter 脚本可正常保存;
- 修改:任意信息均可修改,但更换平台表可能造成脚本不可用,需由用户手动修改脚本内容;
- 试运行:未上传 JMeter 脚本不可试运行;
- 作业上线:若脚本导入节点未上传 JMeter 脚本,不允许上线作业。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
说明:当前节点类型仅支持传递参数,暂无法引用。试运行
用户完成相关配置后,可点击页面右下方的“试运行”按钮,提前测试来源与目标表配置是否正确。
试运行逻辑:试运行系统将脚本中所有数据导入至临时表中,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。
FTP导入
使用场景:用户通过FTP的文件集成能力,实现半结构化数据的复制迁移,提升资产同步便捷性和效率。
使用角色:数据开发人员。
功能描述:平台可将多种类型的第三方来源FTP文件导入至平台进行加工。
前置条件:用户已创建好加工作业并且画布中配有FTP导入节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行FTP导入操作的加工作业,在画布中双击“FTP导入”节点,跳转至库表导入操作界面。根据页面内容填写相关信息后点击“保存”按钮,待系统校验通过后即可创建成功。
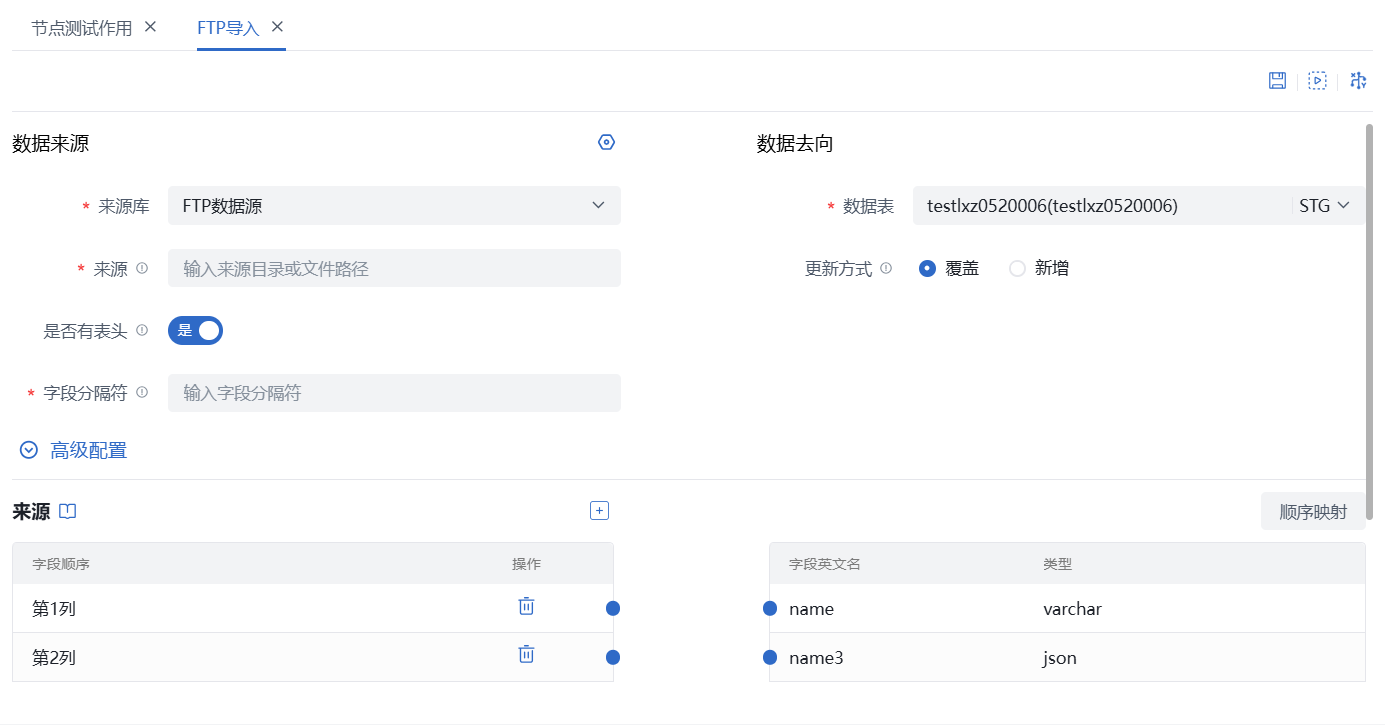
数据来源
- 来源库:必选,下拉选择数据来源FTP数据库;
注意- 若已开启“资源权限管控”,则来源数据库不再展示当前操作用户无权限的数据源
- FTP导入仅支持选择FTP类型数据源
- 来源:必填,手动输入所选来源库中的文件完整路径或目录路径;当前支持的文件格式包括csv、压缩文件(gzip,zip, lzo,压缩包中文件名不能包含中文)
- 是否有表头:默认为“是”,则将第一行视为表头,从第二行开始导入数据;选择“否”,则从第一行开始导入数据
- 字段分隔符:必填,输入文件中的字段分隔符,仅支持单个类型分隔符,如","、"|"等,使用Tab键作为分隔符请输入“\t”
数据去向
- 数据表:必填,选择当前空间中数据表管理中数据表、主数据;
- 更新方式:必选,默认选择覆盖,导入数据前删除原有数据后再插入新数据;选择新增,则保留已有数据,追加新数据。 注意
更新方式举例如下:
- 覆盖:第一次导入10条数据,第二次导入前会自动清空已有数据,第二次导入20条数据,则数据表中最终只会有第二次导入的20条数据;
- 新增:第一次导入10条数据,第二次导入20条数据,则数据表中最终会有第一次+第二次导入的30条数据;不覆盖采用追加逻辑,即不会对相同数据增量更新,因此可能存在重复数据。
- 若开启业务权限管控,目标表会自动过滤掉当前操作用户无读写权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 目标表不可选择其他空间授权的跨空间数据表。
高级配置
- 并发数:非必填,默认不并发,“来源”为目录时可支持填写值域1-5正整数,从而实现多个文件并发导入以提升数据集成速度,反之单个文件时并发数设置不生效。
注意- 设置并发数后会在运行时按所设数量并发执行,但效率提升不是简单的线性相乘,会受多方面因素影响,如并发5,速度不会直接提升至5倍,可能在3.5-5倍之间。
- 并发数过高可能对来源库造成过大压力,导致链接失败,请谨慎设置并发数值。
- 同步速率:默认不限流,选择限流后可填写限流上限值,单位MB/s,值域为1-1000正整数;此处限流速率为总体传输速率,当存在并发时会按并发数进行平均分配,如限流10MB/s,5个并发,则每个并发分片的上限为2MB/s。
- 标识文件:当源端路径下存在启动作业的标识文件时才启动节点,支持配置多个文件名,如.csv;名称中间使用“,”分隔,并可设置或与关系;若标识文件不存在或不满足判定关系,则节点运行状态立即置为失败,可在节点运行详情中查看失败原因。
- 文件过滤:非必填,可填写“正则表达式”进行文件名匹配,仅导入匹配成功的文件;支持配置多个规则,中间使用“,”分隔。
- 时间过滤:非必填,填写后仅导入“文件修改时间”在所设时间范围内的文件
- 支持输入具体时间进行过滤,格式为:yyyy-MM-dd HH:mm:ss;或引用作业参数,格式为:#{param}
- 支持开始结束时间可仅填写一个,如仅填写开始时间,则从开始时间起进行导入;仅填写结束时间,则仅导入截止结束时间的文件数据
- 读写失败上限:非必填,设置可容忍读写失败条数或比例,达到阈值后作业将自动置为失败,默认为0,即不允许失败。
- 其中比例采用实时计算当前已导入数据中的失败比例,即“当前错误数据总数/当前已导入数据总数”,如第一批次错误比例100/1000=10%,进行第一次判定,高于则结束,低于则继续第二批次,第二批次为1000条错误50条,则第二次判定比例为(100+50)/(1000+1000)=7.5%,将7.5%进行第二次判定,以此类推。
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
来源去向
来源:
- 选择目标表后自动在来源生成相同行数的字段列,如目标10个字段,则来源生成10个字段列,顺序为第1-10列
- 字段列按顺序生成列序号,不支持修改,可删除列,删除后下方自动补位,以保证顺序的连续性,如共10列,删除第5列,则列顺序自动变为1-9,不会将第5列序号空出,删除后同步删除连线
- 支持新增字段列,自动新增至最下方,并生成对应序号
目标:显示目标表字段信息,不可修改、删除
顺序映射:点击后自动将同一行进行水平连线,即左边第一行连右边第一行,以此类推
字段类型:来源不提供字段类型展示与修改,来源字段类型按所连线目标字段的字段类型处理
字段连线:若确认目标字段顺序和文件中列顺序一致,可直接通过【顺序映射】自动连线;若字段顺序不一致,请手动将目标字段与正确的来源列连线;仅导入连线字段,未连线字段不进行导入
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
说明:当前节点类型仅支持传递参数,暂无法引用。试运行
用户完成来源表与目标表相关配置后,可点击页面右下方的“试运行”按钮,提前测试来源与目标表配置是否正确。
试运行逻辑:试运行系统将抽样 1000 条导入至临时表中,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。
HTTP访问
使用场景:用户在数据集成开发过程中需获取动态参数以控制下游节点运行,如动态获取token等参数传递场景。
使用角色:数据开发人员。
功能描述:平台提供节点传参能力,数据开发人员可通过“HTTP访问”节点,控制来源API仅输出参数,作为下游节点的输入。
前置条件:用户已创建好加工作业并且画布中配有 HTTP 访问节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行“HTTP访问”操作的加工作业,在画布中双击 “HTTP访问” 节点,跳转至 HTTP 访问操作界面。根据页面内容填写相关信息后点击 “保存” 按钮,待系统校验通过后即可创建成功。
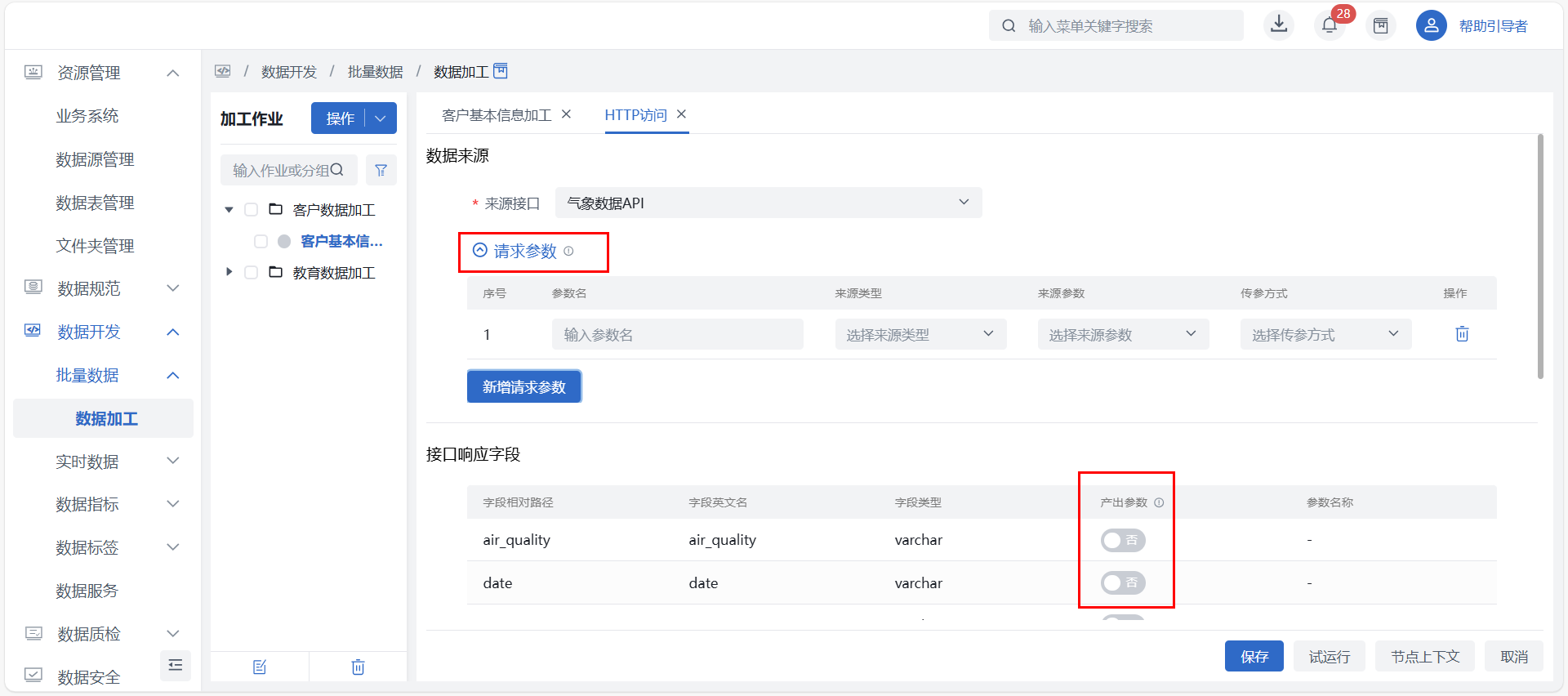
数据来源
- 来源接口:必填,下拉选择数据源管理中已配置的 API 数据源,选择后自动获取已解析的字段;
- 请求参数:点击后展开可新增请求参数配置,用于引用参数,获取参数值,作为本节点的执行输入,取值将覆盖 API 数据源对应参数的设置值;
- 参数名:默认空,选择来源参数后自动填充为所选参数名,可修改;
- 来源类型:选择作业变量或本地变量;
- 来源参数:作业变量选择当前作业已配置作业参数名;本地变量则选择由上游传递而来的参数;
- 传参方式:url、header、body三种类型;
- 引用时,将根据参数类型确定引用覆盖位置,取值覆盖 API 数据源对应与请求参数一致的参数设置值;
- 接口响应字段:选择来源接口后,自动展示该接口解析配置中的所有字段,不支持修改删除;
产出参数:可自定义本节点的输出参数,以供下游节点引用传参;
- 例如:本节点可选择调用某个认证API,将返回值中的令牌信息作为输出参数 token 传递给下游数据 API 节点引用;
- 新增产出参数:可选择字段作为产出参数,参数名列可将字段英文名做为参数名,或自行修改为所需的映射参数名(参数名同一作业内唯一);
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。- 说明:本节点作为上下文参数的源头,往往初始上下文参数就为该节点参数,后续由“API导入”节点接收,或传递给下游节点。
- 刷新:每次打开节点参数,检查当前节点的最新上游节点设置为向下输出的参数;若存在连线删除,则自动剔除对应节点的参数;
- 保存:HTTP 访问节点中,产出参数、请求参数,两者中须任意一个配置了一条参数才可保存。
试运行
用户完成相关配置后,可点击页面右下方的“试运行”按钮,提前测试节点配置是否正确。
试运行逻辑:试运行系统将根据所设置“产出参数”去真实获取来源API的值,并生成对应产出参数值,可验证产出参数配置是否符合预期,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。
SQL加工
使用场景:数据开发人员对入仓的数据表需要使用 SQL 语句进行数据加工。
使用角色:数据开发人员。
功能描述:平台支持 SQL 脚本编写,数据开发人员主要通过该能力做数据开发;可通过试运行检查作业任务配置,确保线上运行的成功率;支持对 SQL 脚本进行版本管理,便于数据开发人员调试与切换;可通过表名、字段名或常用字段检索,辅助数据开发。
前置条件:用户已创建好加工作业并且画布中配有 SQL 加工节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行 SQL 加工操作的加工作业,在画布中点击 SQL 加工节点,进入脚本编写界面并写入 SQL 语句待运行后即可对目标表进行 SQL 加工操作。
- SQL 加工节点同样支持主数据表加工,需注意区分主数据模型版本号,同时支持查询视图数据;
- 若开启业务权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据表、视图的对应业务权限,校验通过方可保存成功;
- SQL 加工节点支持SELECT其他空间授权的跨空间数据表。
- 使用帮助
- 表名前请添加具体的“数据库模式”前缀,即:数据库模式.表名,其中数据库模式在SQL编辑框上方的“字段检索”中可查看;
- SQL加工支持HexaDB数据库中对数据操作的DML语法;
- 对于INSERT INTO SELECT语句,如果SELECT语句中的字段使用了函数,请给字段定义别名,如substr(col1, 3) as col1;
- 对于TRUNCATE语句的使用需谨慎,执行效率较高但是会删除表中所有行
- Ctrl+F 可进行 SQL 代码检索。
常用语法示例
| 分类 | 常用语法 |
|---|---|
| SQL语法 | select/insert/update/delete/truncate/with/merge/set |
| 条件查询 | WHERE |
| 分组 | GROUP BY |
| 排序查询 | ORDER BY |
| 分组过滤 | HAVING |
| 分页查询 | SELECT * FROM 表名 LIMIT 10 OFFSET 20 -- 返回第21到第30条记录 |
| 多表查询 | INNER JOIN、LEFT OUTER JOIN、RIGHT OUTER JOIN |
| 自连接:表与其自身进行连接 SELECT a.列名, b.列名 FROM 表名 a, 表名 b WHERE a.某列 = b.某列; | |
| 子查询:将一个查询嵌套在另一个查询中 SELECT 列名 FROM 表名 WHERE 列名 IN (SELECT 列名 FROM 另一个表名 WHERE 条件); | |
| 字段重命名 | as |
| 其他 | 行尾注释、单行注释 |
产出参数:可自定义本节点的输出参数,以供下游节点引用传参;
①参数名:手动输入,可将字段英文名做为参数名,或自行修改为所需的映射参数名(参数名同一作业内唯一)
②来源语句:下拉单选语句排列序号,即第几行SQL,编辑器中有几行则可选择几行
③来源语句类型:解析语句类型并显示,不可修改
④取数逻辑:不同语句类型可选择不同逻辑,具体如下
select/with:可输入语句中的字段英文名,获取该字段值(仅可选择已选来源SQL语句的参与字段,一个参数仅可输入一个字段值,同一语句若需多个参数,需创建多行,一行一个参数对应一个字段)
update/insert/delete/merge:当前支持获取影响行数,即统计执行结果影响数据行数并返回(选项默认填充且不可修改“影响行数”)
truncate/set/函数:不支持以上类型语句产出参数,选择对应行后提示不支持
⑤参数传递:配置完成参数可传递至下游节点,并在“节点上下文”中查看,或供分支判断、API导入等可接收参数的节点使用;如查询某个表的字段的最新更新时间,用以判断上游节点是否加工完成,从而确定是否触发下游节点运行
⑥传递逻辑:select/with默认取查询结果中参数字段的第一条值;若SQL中涉及过滤和排序,则取排序后的第一条;其他语句均返回单值节点上下文 点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
说明:当前节点类型仅支持传递参数,暂无法引用。试运行
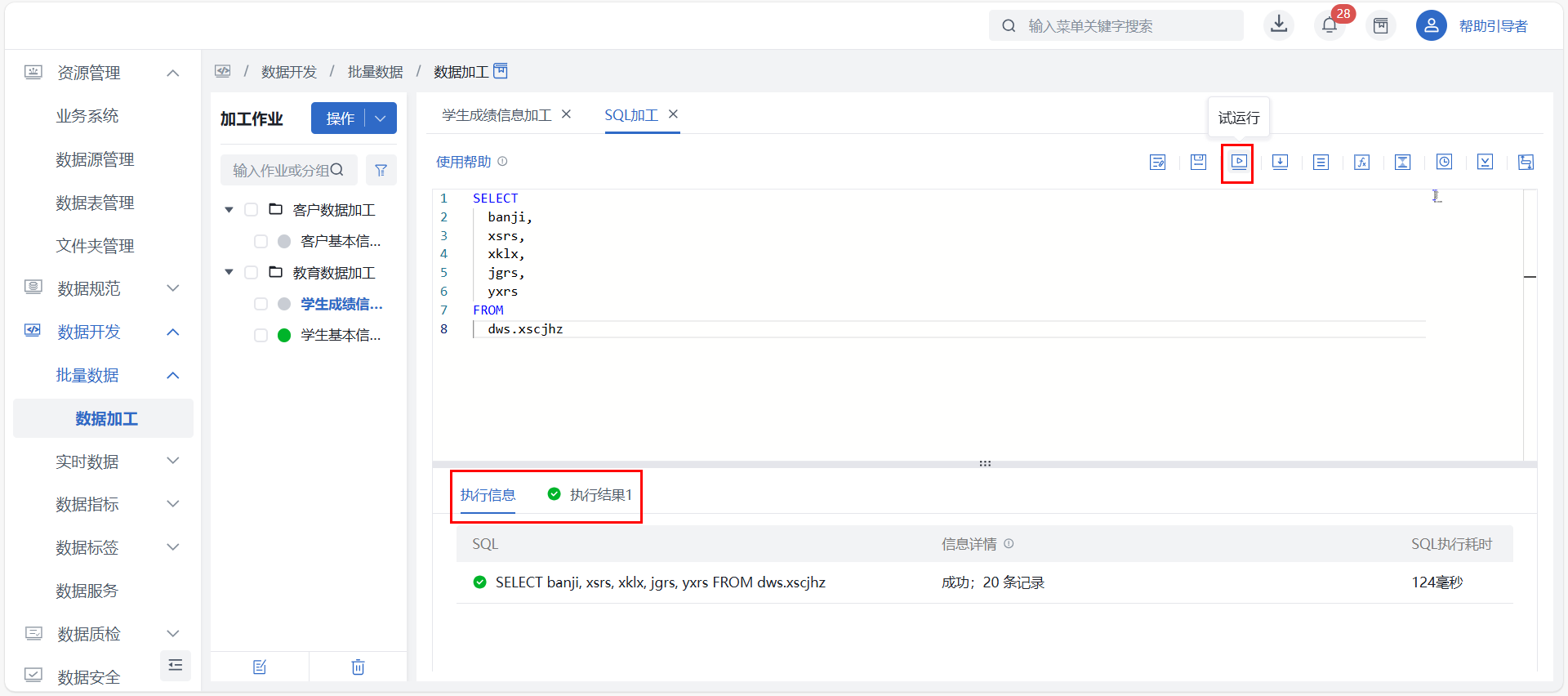
点击“试运行”按钮即可运行写入的 SQL 语句,试运行结束后界面最下方会反馈执行信息与运行结果,帮助用户提前排除如作业配置、SQL 脚本的问题。
试运行逻辑:为避免污染生产数据,试运行操作是在系统生成的测试数据表上执行,不会影响到实际数据表数据。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。
立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。保存版本 可保存当前所编辑的 SQL 脚本,点击 “保存版本” 按钮后根据实际需求填写完版本描述后即可。
注意版本保存信息可在 “版本管理” 中查看;
作业上线时会校验此刻 SQL 加工中的脚本是否与该 SQL 脚本的最新版本一致,若一致则不会生成新版本,反之则自动生成最新版本,版本描述为 “自动生成版本”。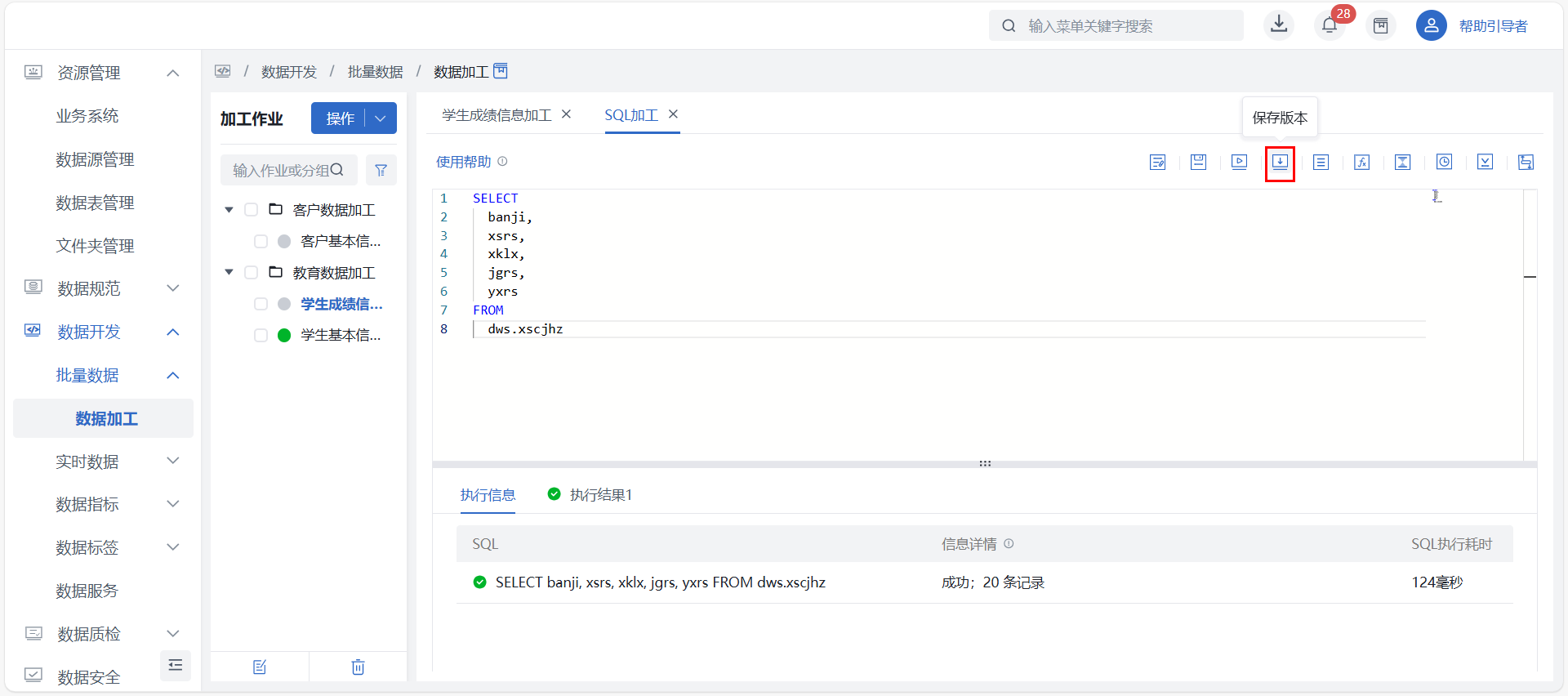
字段检索
单个检索
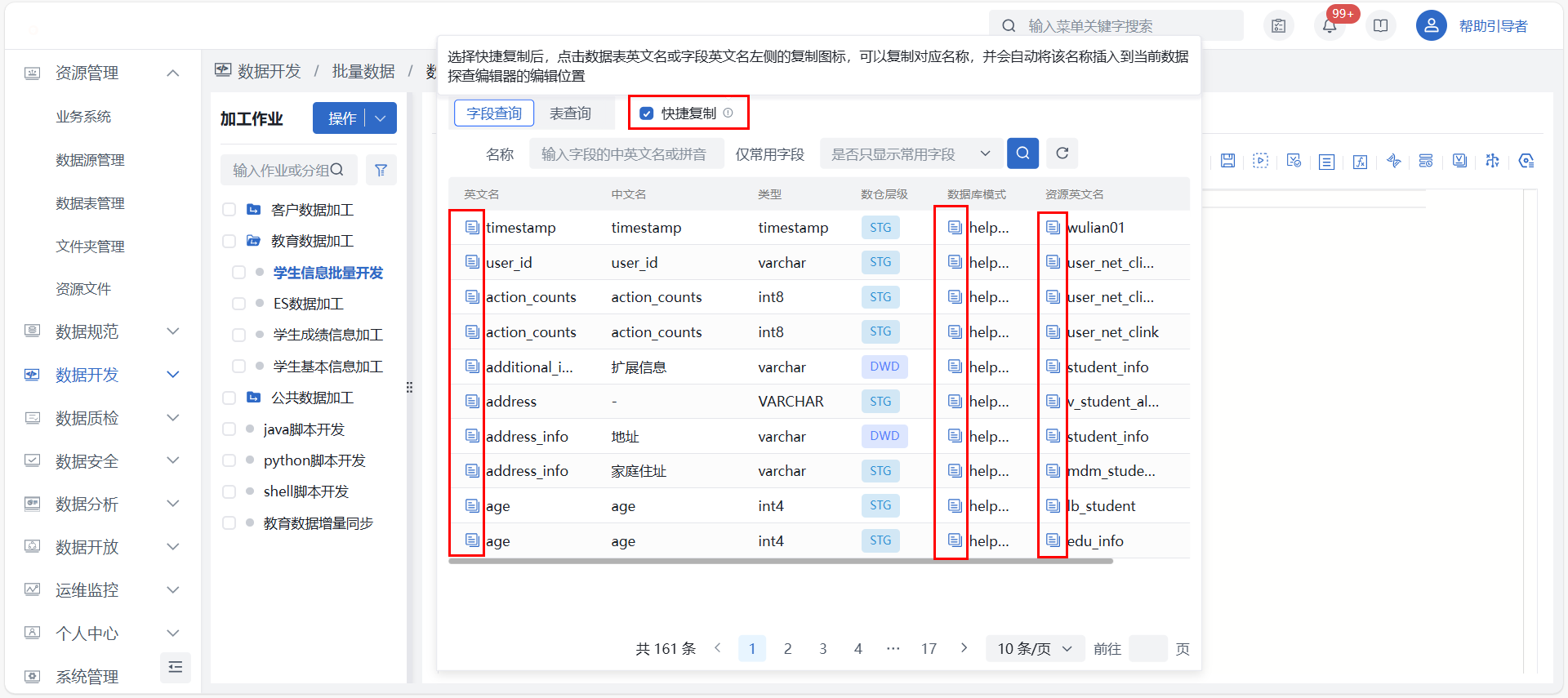
- 点击 “字段检索” 按钮后弹出字段查询详情界面,供提供字段查询或表查询两种方式进行名称复制,查询页面系统默认展示当前空间用户有业务权限字段、表和视图信息,及其他空间已授权的共享数据表/字段信息。
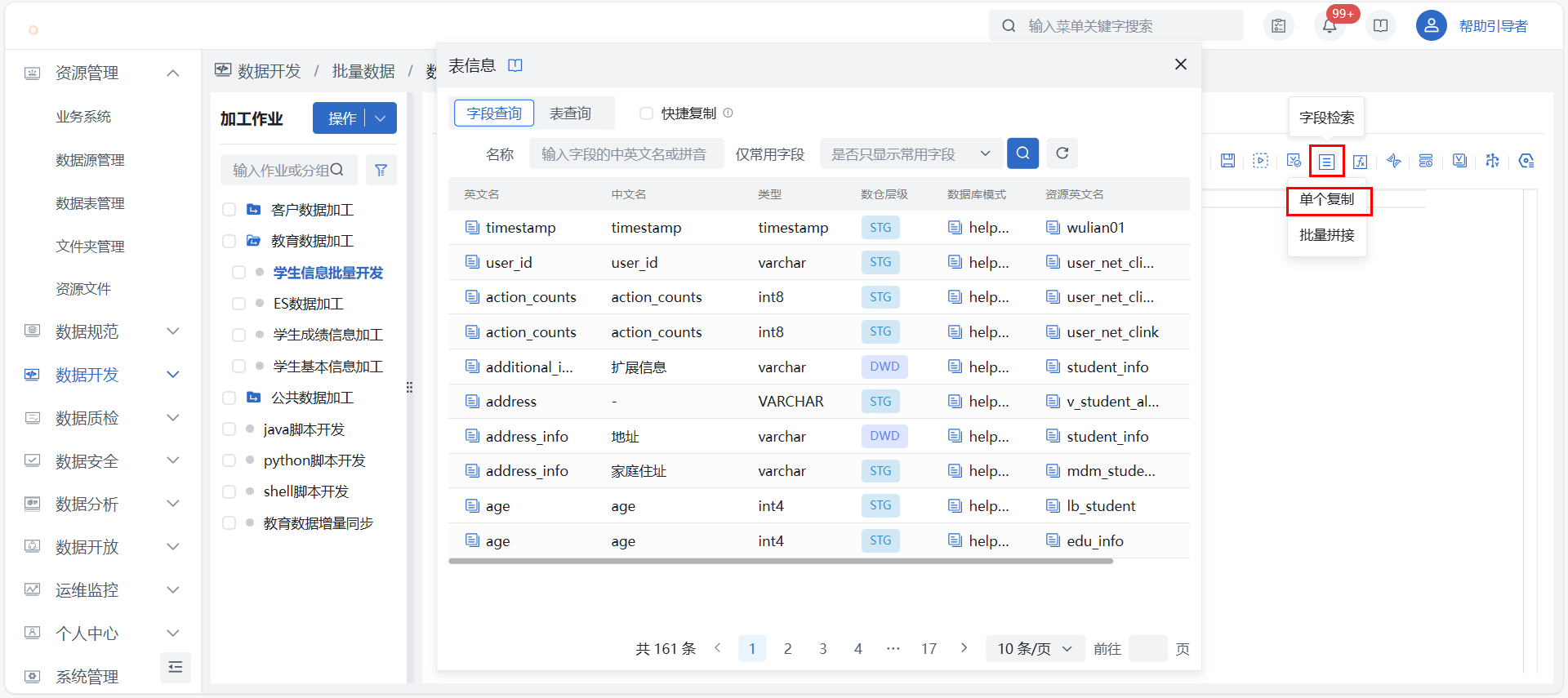
- 字段查询和表查询均可单独复制或快捷复制,单独复制点击字段/表名称前方的复制按钮即可复制目标字段/表名称;快捷复制需要勾选方框后,点击数据表英文名或字段英文名左侧的复制图标,即可复制对应名称。
- 进行表/字段名称复制时系统会自动将复制内容插入到当前 SQL 加工编辑器的编辑位置。
- 表查询界面选中数据表还可展示当前数据表中所有字段信息,表中字段名也可进行复制操作。注意
支持查看表字段的逻辑顺序、物理顺序,当逻辑顺序与物理顺序不一致时,若在SQL中执行
insert into table select *时会报错
逻辑排序:在平台数据表管理界面配置的字段展示顺序
物理排序:数据库中存储的字段实际排列顺序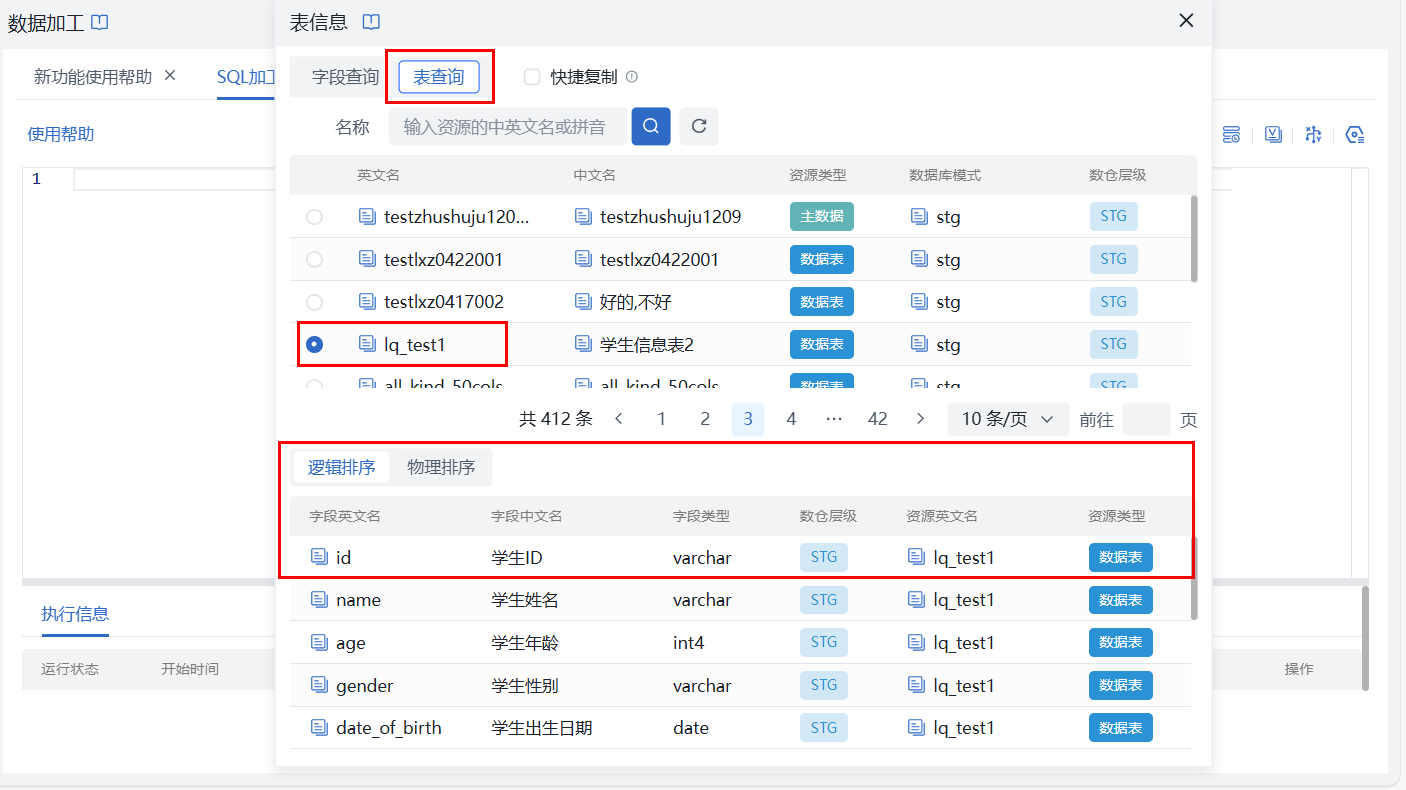
- 点击 “字段检索” 按钮后弹出字段查询详情界面,供提供字段查询或表查询两种方式进行名称复制,查询页面系统默认展示当前空间用户有业务权限字段、表和视图信息,及其他空间已授权的共享数据表/字段信息。
批量拼接
点击 “字段检索” 按钮后在下拉框中选择 “批量拼接” 跳转至批量拼接界面,按照“选择 SQL 模式 > 选择资源对象 > 勾选字段 > 预览”的操作流程即可完成批量拼接,并快速复制拼接结果。
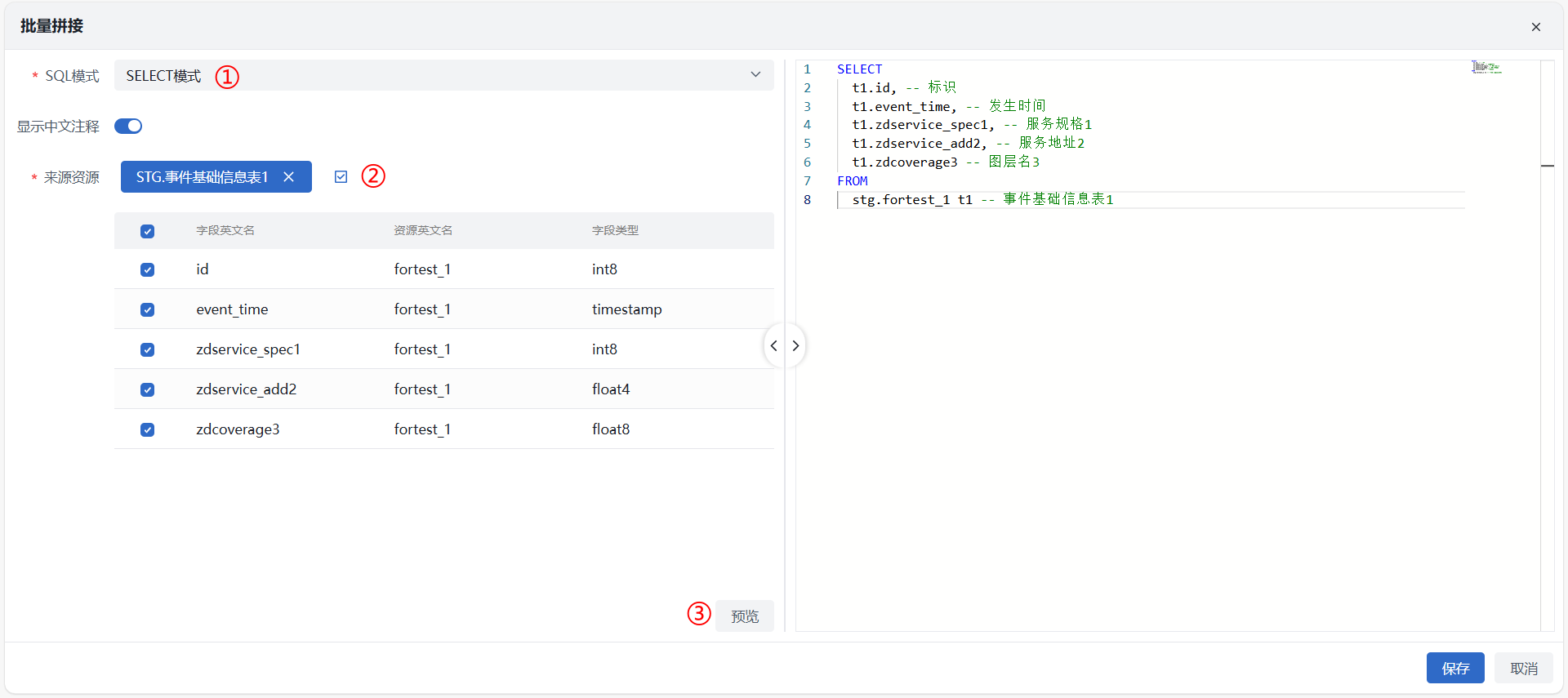
注意- 界面右侧预览框展示批量拼接信息,不同操作模式下单资源和多资源可作用情况有所区别,需注意区分
- 可拼接资源包括数据表、主数据、视图、跨空间共享表,其中视图、跨空间共享表仅支持SELECT模式
- 操作项说明
- 操作模式:下拉选择,平台提供四种 SQL 模式,即 SELECT、INSERT、DELETE、UPDATE;
- 单表对象:下拉选择,支持输入资源中英文名、拼音进行检索;
- 多表对象:点击按钮选择资源,可多选;
- 字段:勾选后在右侧实时预览可见,支持取消勾选,则预览框内容也会同步更新;
- 中文注释:支持手动开启显示中文注释,则预览中将显示对应注释信息,若无注释,如视图字段,则开启后依然不显示。
自定义函数
点击 “自定义函数” 按钮后弹出自定义函数详情界面,页面展示系统中所有在数据开发 > 批量数据 >自定义函数中已创建完成的函数名称、命令格式及描述。
自定义函数页面提供单独复制和快捷复制操作,单独复制点击命令格式前方的复制按钮即可复制函数信息;使用时需先复制“数据库模式”,再复制命令格式方能正常引用函数。
除自定义函数,SQL编辑器本身也支持常见函数,详细参见:常见函数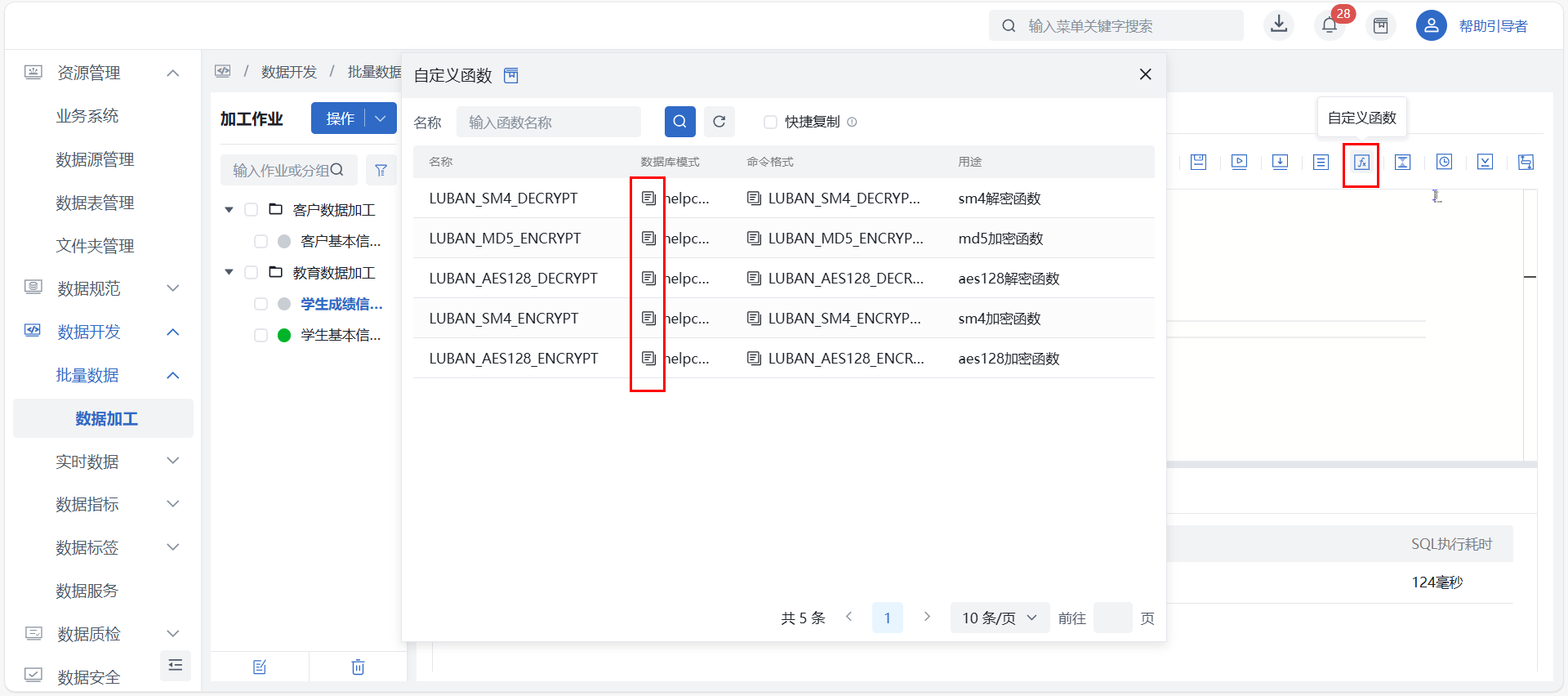
- 成本估算
用户点击 “成本估算” 按钮,点击“开始评估”可立即对 SQL 语句进行成本估算,评估完成后界面下方显示成本值与处理数据量,每条 SQL对应一个结果,同时显示“结果行数”。
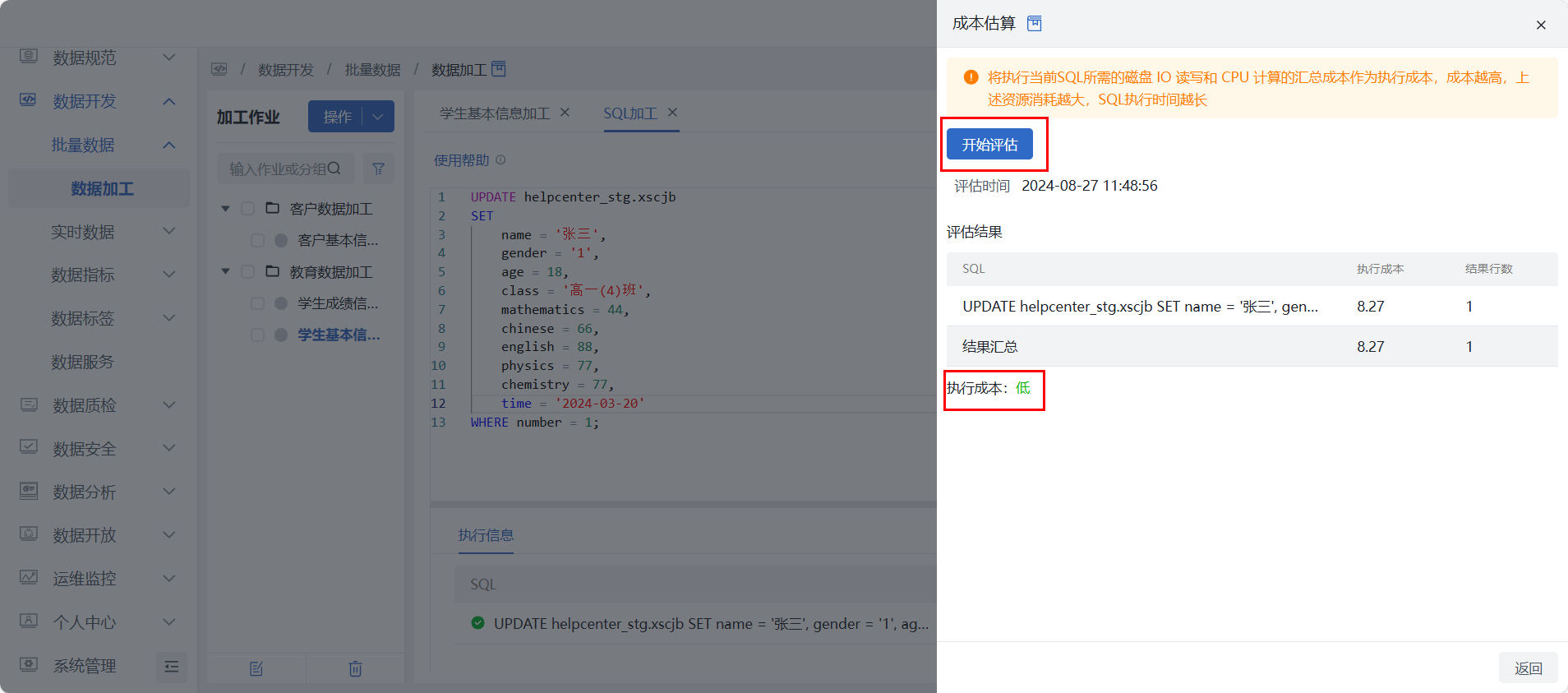
若此前已进行过成本评估,点击“成本评估”,抽屉中会展示上一次评估记录,若重新评估,则覆盖上次记录。
版本管理
用户点击 “版本管理” 按钮可查看近 100 次的版本保存记录。任意选择两条版本记录并勾选记录前面的多选框后,点击 “版本比对” 按钮可对两个版本进行对比,结果差异部分高亮显示。
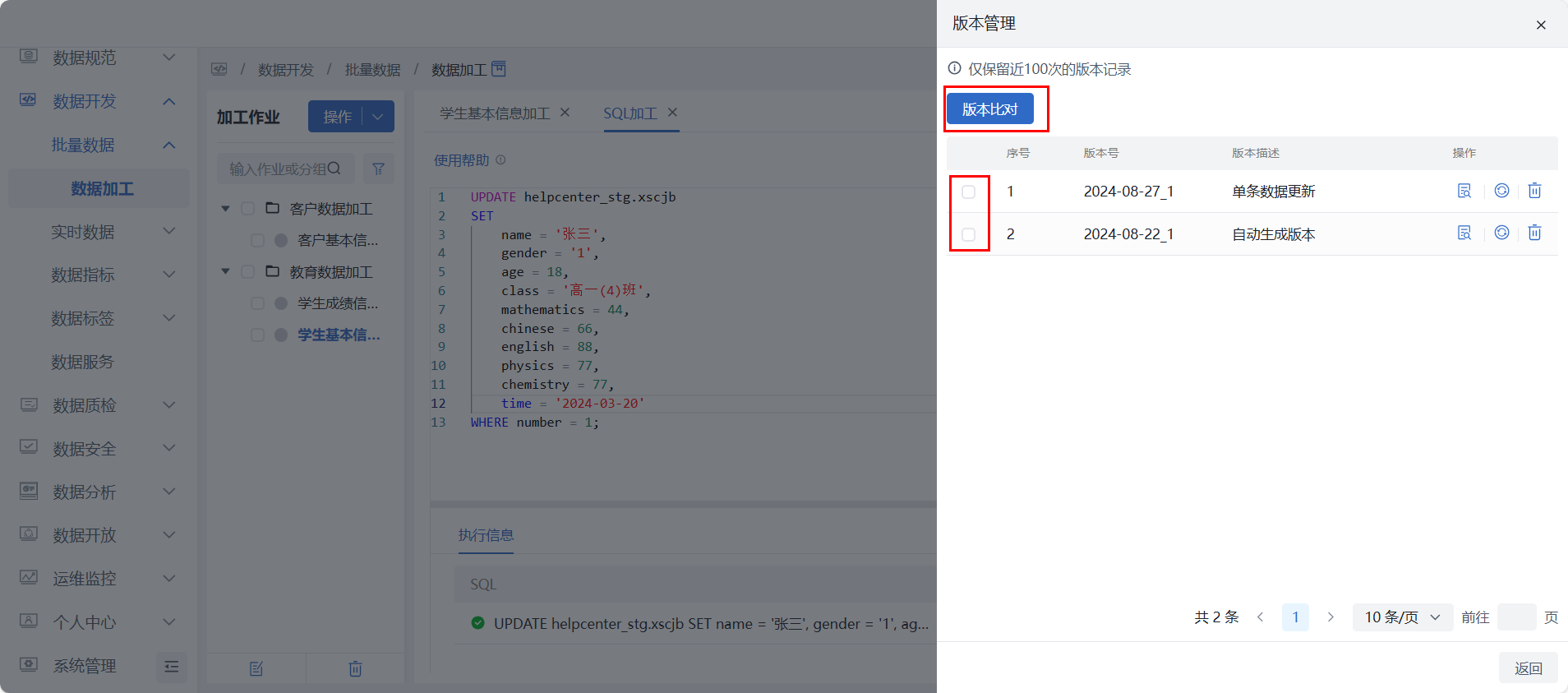
- 操作项说明:
- 点击“查看”,可查看对应版本SQL 脚本信息;
- 点击“恢复”,对应版本的SQL脚本会覆盖至编辑器中;
- 点击“删除”,删除对应版本记录。
- 操作项说明:
血缘检测
用户点击 SQL 加工界面上方“血缘检测”按钮会出现数据血缘弹窗界面,展示当前节点产生的数据血缘。血缘检测界面提供字段或表查询,输入关键字后在数据血缘中高亮展示该字段或表血缘关系,并可补录血缘。
- 此处为静态血缘,即主要根据当前SQL脚本内容解析而来
- 若SQL中包含视图,则血缘中会显示视图的源表血缘,即视图所有字段上游和下游血缘(包括视图在SQL中未输入的字段和已输入的所有字段关系),但该血缘暂不支持手动补录
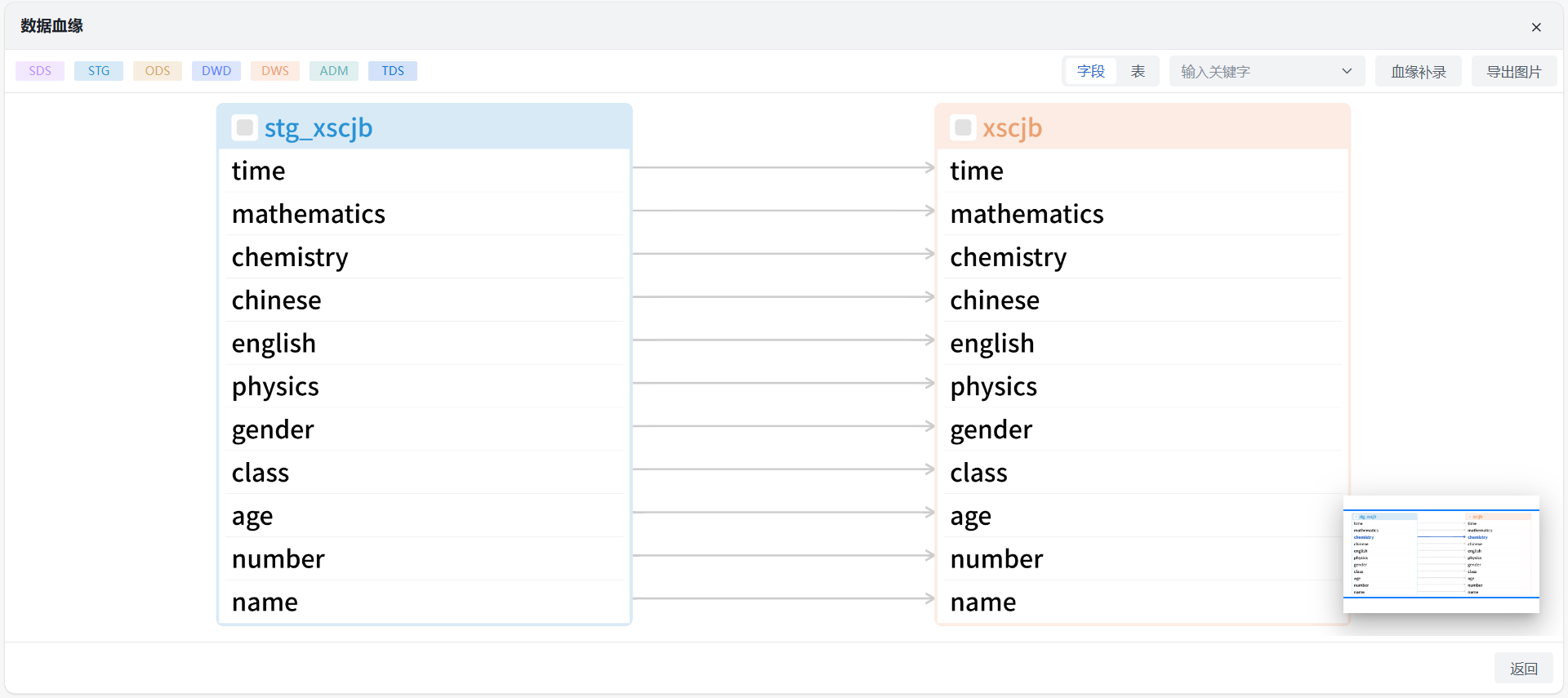
血缘补录:当前若SQL较为复杂或存在不支持语法时,可能存在血缘解析失败,无血缘展示或仅展示部分血缘,此时可通过手动连线的方式进行补录血缘,从而保证在其他功能模块查看血缘时可显示完整。
血缘支持语法包括但不限于以下语法,且后续将持续扩展:多表join、selfjoin、rightjoin、crossjoin、unionjoin、innerjoin、with子查询、merge、递归/线性cte、case when、insert...on conflict、常见函数列等。
- 自动解析的血缘连线不可修改删除,但两表之间可再手动补录字段血缘关系,如将未解析完全的字段连线;视图与基表血缘不可修改删除且不支持补录
- 手动连线补录血缘,无需校验字段类型是否兼容,且手动补录血缘可任意删除
- 自动血缘优先级高于手动血缘,若两表字段之间存在手动血缘,自动血缘解析成功后,则覆盖手动血缘
- 点击血缘检测、试运行、保存时,均会触发自动解析血缘,并更新自动血缘;同时展示可用的手动血缘,即仅保留原表、字段依然存在的手动血缘,其他不存在的字段连线自动清空
- 高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
库表导出
使用场景:当用户需要对平台仓内已治理好的数据表做进一步处理时,可通过“库表导出”将平台仓内的表数据导出至第三方数据库中的目标表。
使用角色:数据开发人员。
功能描述:平台可将已加工完毕的数据写入第三方目标数据库,可选择需要导出的目标数据库以及明细数据表。
前置条件:用户已创建好加工作业并且画布中配有库表导出节点。
操作流程:
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行数据导出操作的加工作业,在画布中双击 “库表导出” 节点,跳转至库表导出操作界面。根据页面内容填写相关信息后点击“保存”按钮,待系统校验通过后即可创建成功。
- 数据来源
- 来源表:必填,选择平台中的数据表作为来源表;
- 拆分主键:非必填,可配置拆分主键提升导入导出性能;
- 由用户手动选择源表中的字段作为主键;
- 主键拆分均支持用户手动选择字段进行配置;
- 字段类型无限制,选择字段后展示字段英文名与类型;
- 过滤 SQL:非必填,用于进行数据过滤,仅处理过滤后数据,目前支持单行 SQL,标准WHERE语句,并可引用作业参数。
- 若开启业务权限管控,来源表会自动过滤掉当前操作用户无权限数据表;且节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功。
- 来源表不可选择其他空间授权的跨空间数据表。
数据去向
目标库:必填,先下拉选择目标库类型,再选择前置工作中已在数据源管理注册的数据库作为目标库;
注意- 若已开启“资源权限管控”,则目标库不再展示当前操作用户无权限的数据源
- 库表导出不支持选择API、Kafka类型数据源
目标:必填,选择数据导出的目标表;选择ElasticSearch数据源时,目标为选择索引
高级配置
- 并发数:非必填,默认为5,最大15;主键(不支持联合主键)数据类型为整型时,可配置并发数提升数据集成速度,反之并发数不可配。
注意- 设置并发数后会在运行时按所设数量并发执行,但效率提升不是简单的线性相乘,会受多方面因素影响,如初始并发5,设置为10后,速度不会直接提升至2倍,可能在1.5-2倍之间。
- 并发数过高可能对来源库造成过大压力,导致链接失败,请谨慎设置并发数值。
同步速率:默认不限流,选择限流后可填写限流上限值,单位MB/s,值域为1-1000正整数;此处限流速率为总体传输速率,当存在并发时会按并发数进行平均分配,如限流10MB/s,5个并发,则每个并发分片的上限为2MB/s。
注意限流实际速率可能在所填数值附近上下波动。
失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
批获取量:控制单次从数据库获取数据的行数(fetchSize),单次获取量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值1000。
批提交量:控制单次提交写入数据的行数(batchSize),单次提交量越大可提升同步性能,但该值过大可能造成内存溢出(OOM),建议不超过2048,不填写则使用后台默认值2048。
运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
更新方式:
- 目标库为MySQL时: 目标表无主键时,数据更新方式默认为新增,选择覆盖后依然按新增执行 目标表有主键时,数据更新方式可选择覆盖,将更新主键所在行
- 目标库为ElasticSearch时: 覆盖:导出数据前删除原来的索引并重建同名索引,此操作会删除该索引下的数据 新增:导出数据前保留索引中已存在的数据
- 读写失败上限:非必填,设置可容忍读写失败条数或比例,达到阈值后作业将自动置为失败,默认为0,即不允许失败。
- 其中比例采用实时计算当前已导入数据中的失败比例,即“当前错误数据总数/当前已导入数据总数”,如第一批次错误比例100/1000=10%,进行第一次判定,高于则结束,低于则继续第二批次,第二批次为1000条错误50条,则第二次判定比例为(100+50)/(1000+1000)=7.5%,将7.5%进行第二次判定,以此类推。
- 前处理 SQL:非必填,对目标表原有数据进行前置处理,如删除数据;目前支持多条 SQL,使用分号 “;” 分割;
- 后处理 SQL:非必填,对导出至目标表数据进行后置处理;
注意仅目标库为ElasticSearch时出现以下配置:
- 分片数量:分片是ES中数据存储的基本单位,通过将数据分片,可以实现数据分布式存储和并行处理,从而提高索引的查询性能;必填,默认为1,仅可填写正整数,最大10000;
- 副本数量:副本是将数据冗余拷贝并存储在副本分片中,通过增加副本数量,当一个节点或分片出现故障时,可以从其他节点上的副本分片中恢复数据,从而保证数据的持续可用性;必填,默认为0,仅可填写正整数,最大10000。
- 更多参数
当导出目标库为“ElasticSearch” 时,提供更多高级参数供配置,但各配置均提供默认值,无需配置也可正常使用,参数说明具体如下:
| 参数 | 描述 | 默认值 |
|---|---|---|
| batchSize | 定义同步任务一次性插入ElasticSearch的Document条数。 | 1000 |
| trySize | 定义执行器往ElasticSearch写入数据失败后的重试次数。优先使用执行器重试次数,再使用节点重试,即最大重试次数为节点重试*执行器重试 | 3 |
| timeout | 任务是否启动节点发现功能 是:与集群中随机一个节点进行连接,启用节点发现将轮询并定期更新客户机中的服务器列表 否:与Elasticsearch集群进行连接 | 600秒 |
| discovery | 任务是否启动节点发现功能 是:与集群中随机一个节点进行连接,启用节点发现将轮询并定期更新客户机中的服务器列表 否:与Elasticsearch集群进行连接 | 否 |
| compression | HTTP请求,开启压缩 | 是 |
| multiThread | HTTP请求,是否有多线程 | 是 |
| ignoreWriteError | 忽略写入错误,不重试,继续写入 | 否 |
| ignoreParseError | 忽略解析数据格式错误,继续写入 | 是 |
| alias | 在数据导入完成后,为指定的索引创建别名。Elasticsearch的别名类似于数据库的视图机制,为索引my_index创建一个别名my_index_alias,对my_index_alias的操作与my_index的操作一致 | 无 |
| aliasMode | 数据导入完成后增加别名的模式,包括append(增加模式)和exclusive(只留这一个) append,表示追加当前索引至别名alias映射中(一个别名对应多个索引) exclusive,表示首先删除别名alias,再添加当前索引至别名alias映射中(一个别名对应一个索引) 后续会转换别名为实际的索引名称,别名可以用来进行索引迁移和多个索引的查询统一,并可以用来实现视图的功能 | append |
| dynamic | 定义当在文档中发现未存在的字段时,同步任务是否通过Elasticsearch动态映射机制为字段添加映射 是:保留Elasticsearch的自动mappings映射 否:默认值,不填写默认为否,根据同步任务配置的column生成并更新Elasticsearch的mappings映射 | 否 |
| actionType | 定义Elasticsearch在数据写出时的action类型,目前数据集成支持index和update两种actionType | index |
| primaryKeyInfo | 定义当前写入ElasticSearch的主键 | 无 |
| esPartitionColumn | 定义写入ElasticSearch时是否开启分区,用于修改ElasticSearch中的routing的参数 开启分区:把指定列的value通过分隔符空串连接指定为routing的值,在写入时,插入或更新指定shard中的doc,开启分区的情况下您需要指定分区列 不开启分区:不填写该参数,默认使用_id作为routing起到将文档均匀分布到多个分片上防止数据倾斜的作用 | 无 |
| enableWriteNull | 定义是否支持将来源端的空值字段同步至Elasticsearch 是:支持。同步后,Elasticsearch中对应字段的value为空 否:不支持。来源端的空值字段无法同步至Elasticsearch,即在Elasticsearch中不显示该字段 | 是 |
同名映射
当两个字段的英文名(不分大小写)相同且字段类型兼容时,定义为同名字段。用户可通过点击页面内的“同名映射”按钮一键自动映射同名字段。映射配置
点击页面上的“映射配置” 按钮可进行两端字段的选择,配置当前未连线字段的映射关系。
同时用户也可通过手动连线进行来源表与目标表的字段配置。系统会自动将目标表中可连接字段连接点变为空心圆,方便用户判断。
不兼容字段类型将无法自动、手动连线映射,内置兼容类型详见:字段类型兼容说明。
仅目标库为ElasticSearch时出现以下配置:
- 附加属性:非必填,用于分词,以便更精准映射索引层级,仅支持输入json
- 自定义字段:可手动添加自定义字段,以免来源表存在字段目标表没有的字段,可在导出时同步新建字段;
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。 说明:当前节点类型仅支持传递参数,暂无法引用。试运行
用户完成相关配置后,可点击页面右下方的 “试运行” 按钮,提前节点配置是否正确。
试运行逻辑:试运行系统将抽样来源1000条数据导入至目标库的真实表中,并将执行信息和执行结果在当前页面最下方展示,因此可能在目标表中产生脏数据。
取消试运行:处于试运行中的节点可点击“取消试运行”按钮,立即终止当前的节点级试运行;非运行中状态、或处于作业级试运行中状态时,取消按钮不可点。立即运行
平台提供节点级立即运行,点击按钮后即可立即触发当前节点立即运行。
立即运行逻辑:立即运行系统将按当前节点配置真实运行,并将执行信息和执行结果在当前页面最下方展示,但不会在“运维监控 > 调度管理”界面中生成对应的作业任务实例。
取消试运行:处于立即运行中的节点可点击“取消立即运行”按钮,立即终止当前的节点级立即运行;非运行中状态、或处于作业级立即运行中状态时,取消按钮不可点。
SHELL脚本
使用场景:数据开发人员对入仓的数据表需要使用SHELL脚本进行数据加工。
使用角色:数据开发人员。
功能描述:支持SHELL脚本编写,数据开发人员主要通过该能力执行一系列的SHELL脚本;可通过立即运行验证脚本命令执行效果;支持对SHELL脚本进行版本管理,便于数据开发人员调试与切换。
前置条件:用户已创建好加工作业并且画布中配有SHELL脚本节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行 SHELL脚本开发操作的加工作业,在画布中点击 SHELL脚本节点,进入脚本编写界面完成配置,即可立即运行,或作业上线后按调度运行。
- 若开启业务权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功;
- 若开启资源权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据源、主机的对应资源权限,校验通过方可保存成功。
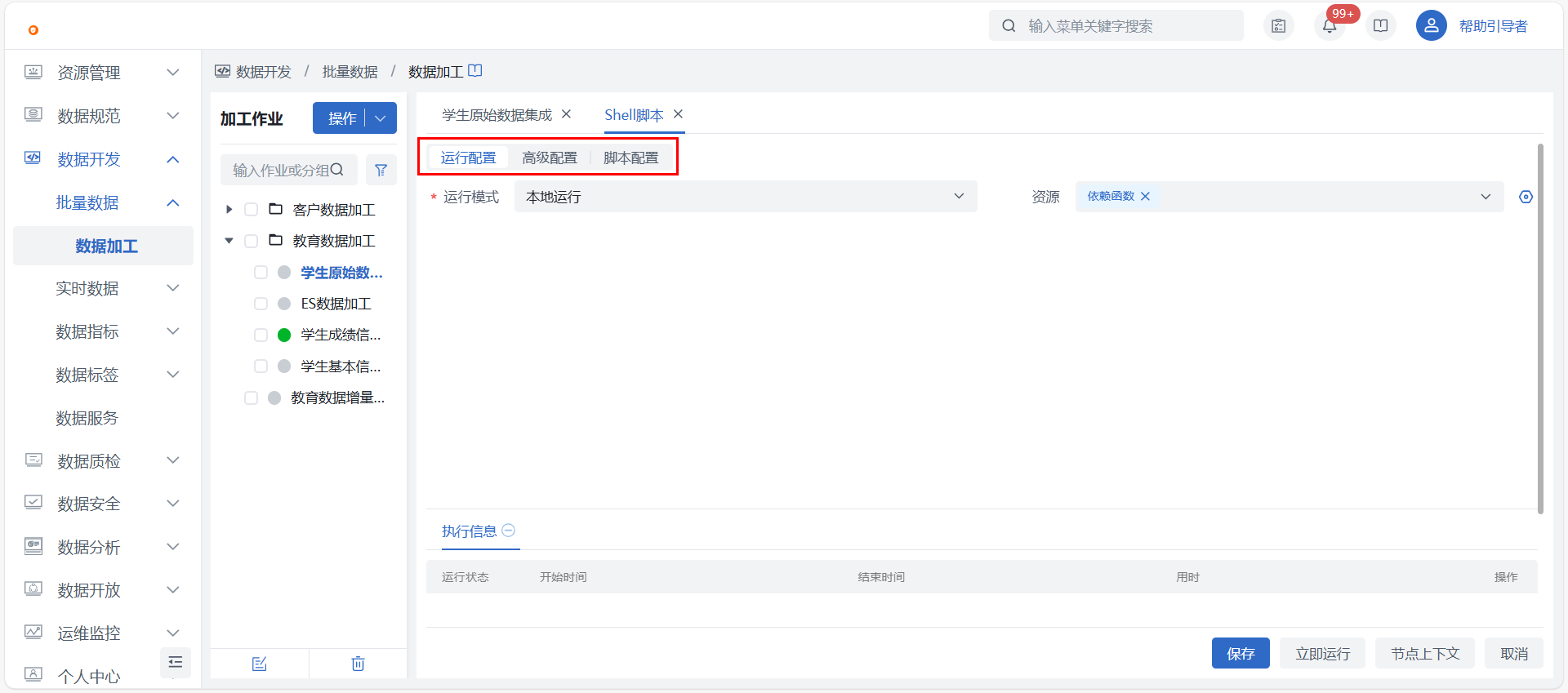
运行配置
脚本配置
- 根据实际需要编写SHELL脚本,脚本内容的注意不要越权,即权限不能超过连接主机所用用户的权限,否则脚本可能运行失败。
注意当前本地主机模式执行脚本时使用的root用户,请勿执行高危命令,特别是删除系统文件等命令,以免造成作业运行异常乃至影响平台正常运行。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。 说明:当前节点类型仅支持传递参数,暂无法引用。立即运行
点击“立即运行”按钮即可运行写入的SHELL脚本语句,该运行为真实运行,在界面最下方会反馈运行状态与运行详情,帮助用户了解实际运行情况。立即运行过程中,支持取消运行以结束运行状态。保存版本 保存版本可保存当前所编辑的SHELL脚本,点击 “保存版本” 按钮后根据实际需求填写完版本描述后即可。
注意版本保存信息可在 “版本管理” 中查看;
作业上线时会校验此刻shell脚本中的脚本是否与该 shell脚本的最新版本一致,若一致则不会生成新版本,反之则自动生成最新版本,版本描述为 “自动生成版本”。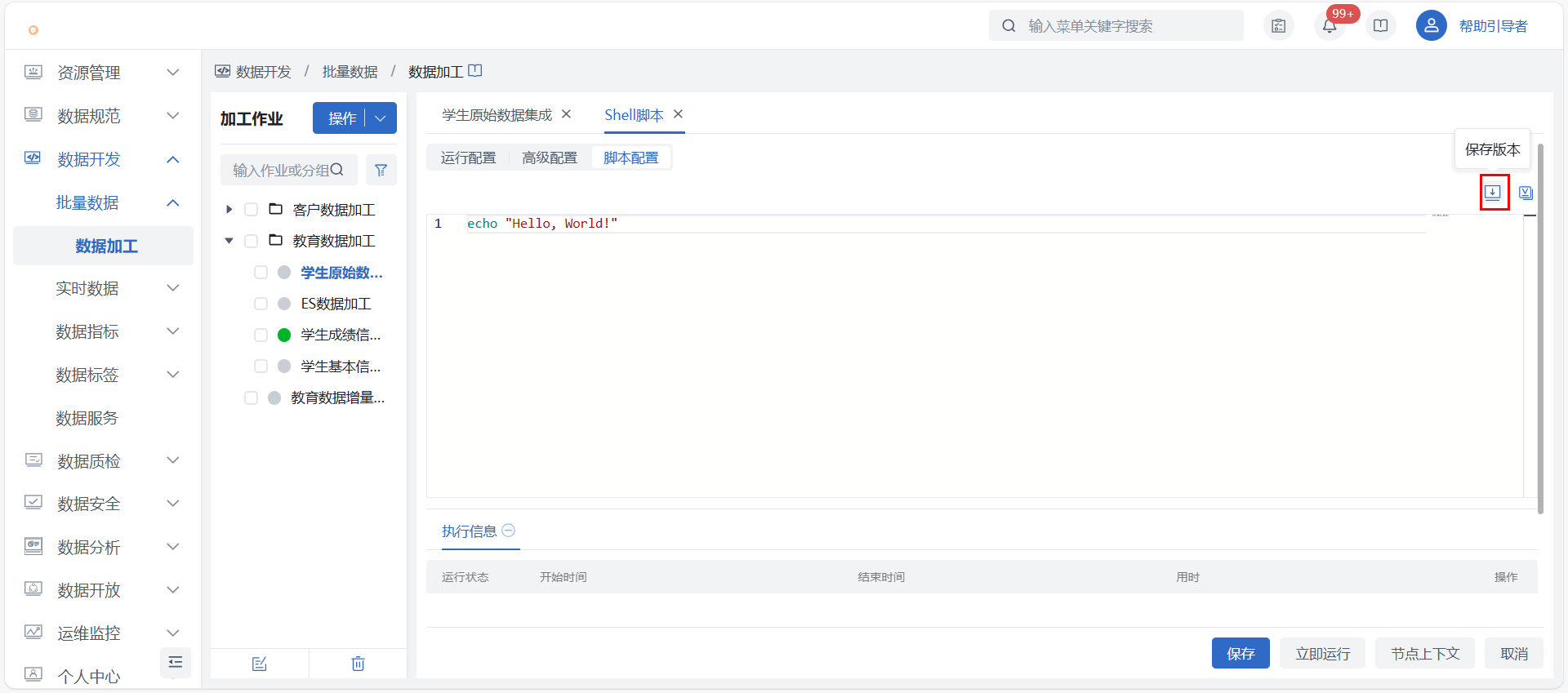
版本管理
用户点击 “版本管理” 按钮可查看近 100 次的版本保存记录。任意选择两条版本记录并勾选记录前面的多选框后,点击 “版本比对” 按钮可对两个版本进行对比,结果差异部分高亮显示。
- 操作项说明:
- 点击“查看”,可查看对应版本SHELL脚本信息;
- 点击“恢复”,对应版本的SHELL脚本会覆盖至编辑器中;
- 点击“删除”,删除对应版本记录。
- 操作项说明:
PYTHON脚本
使用场景:数据开发人员对入仓的数据表需要使用PYTHON脚本进行数据加工。
使用角色:数据开发人员。
功能描述:支持PYTHON脚本编写,数据开发人员主要通过该能力做更复杂逻辑的数据加工;可通过立即运行验证脚本命令执行效果;支持对PYTHON脚本进行版本管理,便于数据开发人员调试与切换。
前置条件:用户已创建好加工作业并且画布中配有PYTHON脚本节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行 PYTHON脚本开发操作的加工作业,在画布中点击 PYTHON脚本节点,进入脚本编写界面完成配置,即可立即运行,或作业上线后按调度运行。
- 若开启业务权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功;
- 若开启资源权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据源、主机的对应资源权限,校验通过方可保存成功。
运行配置
- 运行模式:必填,仅支持本地运行,即通过平台自身主机运行脚本;
- 资源:可选择依赖资源文件,单选,非必填,如若需要资源需在“资源管理-资源文件”完成资源文件上传;
- 启动参数:可设置脚本的启动参数,会替换脚本中以${变量}的内容,支持引用作业参数、节点上下文参数;
- 前置处理:非必填,支持输入shell语句等处理语句,执行脚本前会先完成前置处理执行,如多个依赖文件打包上传后,通过shell命令先完成解压操作,可参考最佳实践示例:python脚本开发
脚本配置
- 根据实际需要编写PYTHON脚本,如通过脚本处理SQL无法实现的数据加工逻辑。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。 说明:当前节点类型支持传递参数,并可在“启动参数”引用上下文参数。立即运行
点击“立即运行”按钮即可真实运行写入的PYTHON脚本语句,界面最下方会反馈运行状态与运行详情,帮助用户了解实际运行情况。立即运行过程中,支持取消运行以结束运行状态。保存版本 保存版本可保存当前所编辑的PYTHON脚本,点击 “保存版本” 按钮后根据实际需求填写完版本描述后即可。
注意版本保存信息可在 “版本管理” 中查看;
作业上线时会校验此刻PYTHON脚本中的脚本是否与该 PYTHON脚本的最新版本一致,若一致则不会生成新版本,反之则自动生成最新版本,版本描述为 “自动生成版本”。
版本管理
用户点击 “版本管理” 按钮可查看近 100 次的版本保存记录。任意选择两条版本记录并勾选记录前面的多选框后,点击 “版本比对” 按钮可对两个版本进行对比,结果差异部分高亮显示。
- 操作项说明:
- 点击“查看”,可查看对应版本PYTHON脚本信息;
- 点击“恢复”,对应版本的PYTHON脚本会覆盖至编辑器中;
- 点击“删除”,删除对应版本记录。
- 操作项说明:
JAVA脚本
使用场景:数据开发人员对入仓的数据表需要使用JAVA脚本进行数据加工。
使用角色:数据开发人员。
功能描述:支持JAVA脚本编写,数据开发人员主要通过该能力做更复杂逻辑的数据加工;可通过立即运行验证脚本命令执行效果;支持对JAVA脚本进行版本管理,便于数据开发人员调试与切换。
前置条件:用户已创建好加工作业并且画布中配有JAVA脚本节点。
进入数据开发 > 批量数据 > 数据加工界面,选中需要进行JAVA脚本开发操作的加工作业,在画布中点击JAVA脚本节点,进入脚本编写界面完成配置,即可立即运行,或作业上线后按调度运行。
- 若开启业务权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据表的对应业务权限,校验通过方可保存成功;
- 若开启资源权限管控,节点保存时会校验作业运行人是否拥有节点内所有数据源、主机的对应资源权限,校验通过方可保存成功。
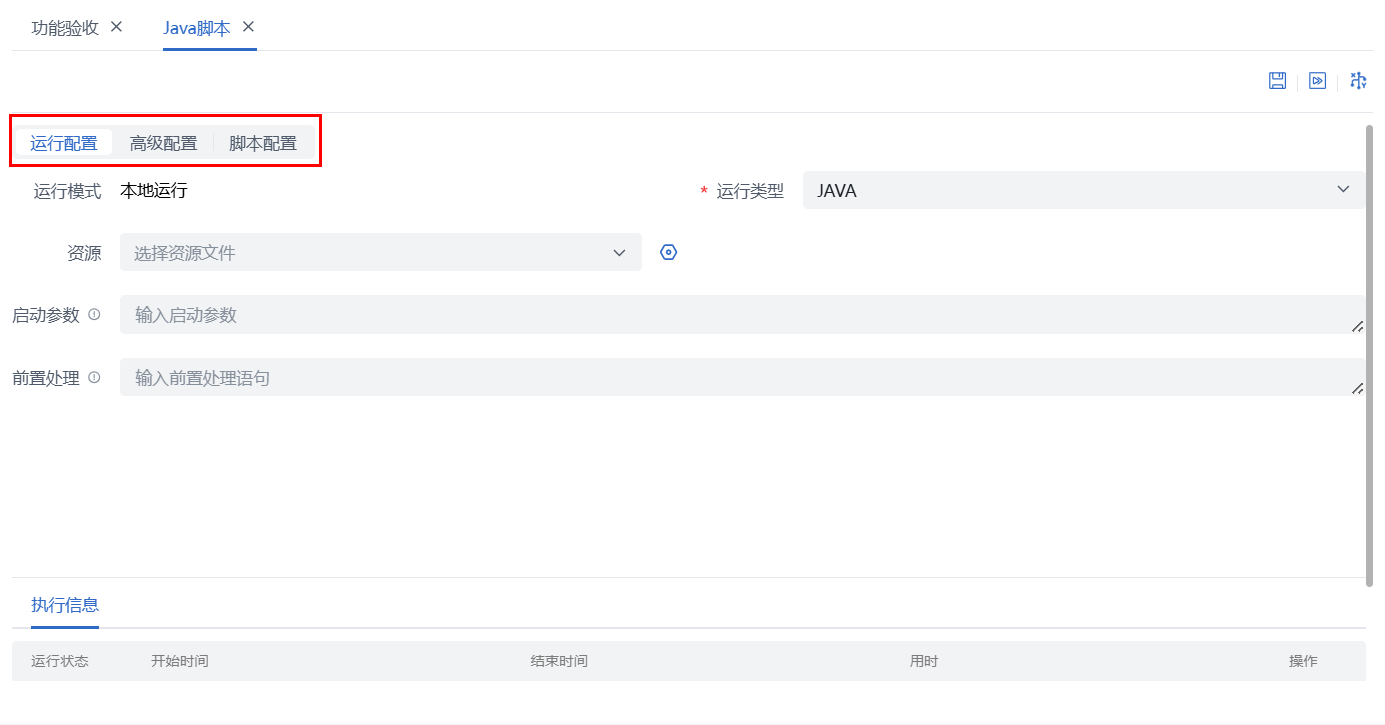
运行配置
脚本配置
脚本模式:运行类型为“JAVA”时出现脚本编辑器,可根据实际需要编写JAVA脚本,如通过脚本处理SQL无法实现的数据加工逻辑。
- 说明:JAVA代码中必须存在public类,不用写package语句
主程序包:运行类型为“JAR”时出现主程序包选择,单选,仅可选择已在“资源管理-资源文件”上传的主程序包
- 说明:主程序包为jar包,需包含MANIFEST.MF描述文件、.class类文件等,示例如下
在Java中使用Maven进行打包,以生成一个可执行的jar文件,通常会遵循以下步骤和jar结构概念:
1. POM.xml配置:首先确保你的pom.xml文件配置正确,需要包含maven-jar-plugin和maven-assembly-plugin(或者maven-shade-plugin,两者择一)来生成可执行jar。例如,使用maven-assembly-plugin的配置示例:
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>全限定类名</mainClass> <!-- 这里填写主类的全限定名 -->
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
markup
或使用maven-shade-plugin:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>全限定类名</mainClass> <!-- 主类的全限定名 -->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
markup
2. 可执行jar结构:一个可执行jar(所谓的“fat jar”或“uber jar”)通常包含以下结构:
• 应用程序代码:你的项目中的所有编译后的.class文件。
• 依赖库:项目依赖的所有第三方库被打包进jar,这样就不需要外部的类路径设置。
• Manifest文件:包含Main-Class属性,指定jar启动时执行的主类。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 运行内存:节点运行所占的最大内存,不填写则使用后台所配置的统一初始值,可单独为各节点配置[256-4096]区间的正整数,当资源紧张时可输入较小值,以避免所需资源较大而无法启动,当运行实际使用内存超过所设值时,将自动停止运行,状态置为失败。
节点上下文
点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。 说明:当前节点类型支持传递参数,并可在“启动参数”引用上下文参数。立即运行
点击“立即运行”按钮即可真实运行写入的JAVA脚本语句,界面最下方会反馈运行状态与运行详情,帮助用户了解实际运行情况。立即运行过程中,支持取消运行以结束运行状态。保存版本 保存版本可保存当前所编辑的JAVA脚本,点击 “保存版本” 按钮后根据实际需求填写完版本描述后即可。
注意版本保存信息可在 “版本管理” 中查看;
作业上线时会校验此刻JAVA脚本中的脚本是否与该JAVA脚本的最新版本一致,若一致则不会生成新版本,反之则自动生成最新版本,版本描述为 “自动生成版本”。
版本管理
用户点击 “版本管理” 按钮可查看近 100 次的版本保存记录。任意选择两条版本记录并勾选记录前面的多选框后,点击 “版本比对” 按钮可对两个版本进行对比,结果差异部分高亮显示。
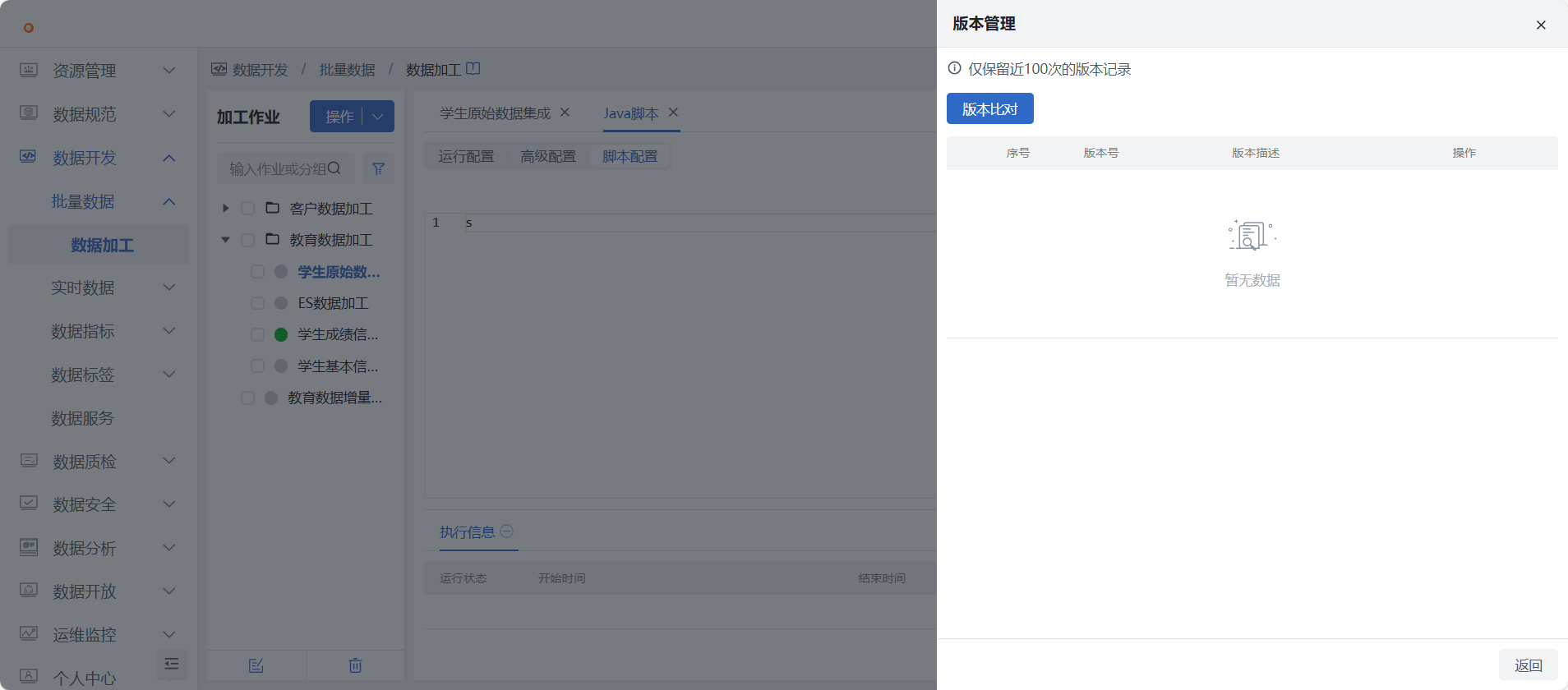
- 操作项说明:
- 点击“查看”,可查看对应版本JAVA脚本信息;
- 点击“恢复”,对应版本的JAVA脚本会覆盖至编辑器中;
- 点击“删除”,删除对应版本记录。
- 操作项说明:
分支判断
使用场景:数据开发人员在数据开发时需按不同条件执行不同加工逻辑,以满足不同场景的流程判断。
使用角色:数据开发人员。
功能描述:平台提供分支进行流程控制能力,分支判断可以定义分支逻辑和不同逻辑条件时下游分支走向。
操作流程:
进入数据开发 > 批量数据 > 数据加工界面,选中目标加工作业,在画布中双击 “分支判断” 节点,跳转至分支判断操作界面。根据页面内容填写相关信息后点击 “保存” 按钮,待系统校验通过后即可创建成功。
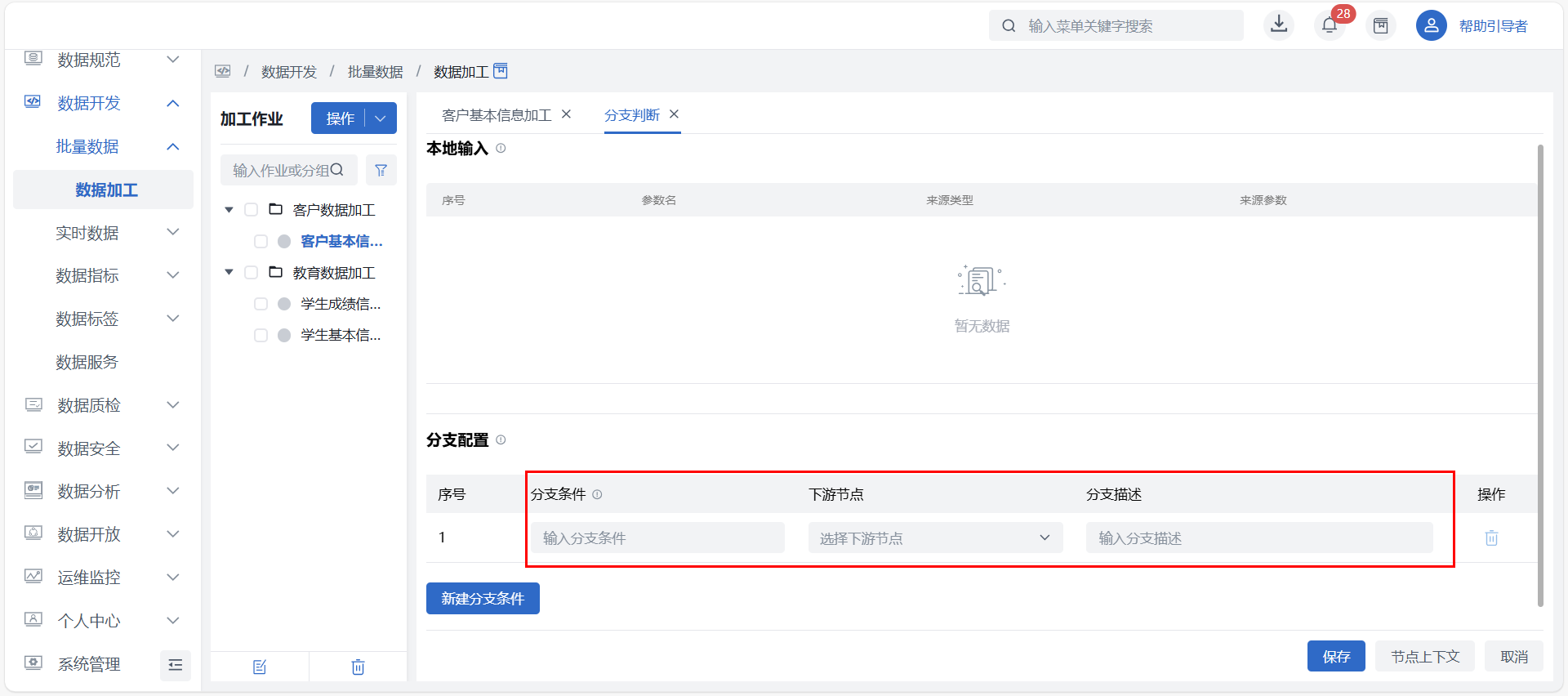
本地输入
- 由上下游输入、作业变量自动带入当前分支节点已新增完成的“上下文输入”及作业参数,参数可用于编写分支条件;
- 参数名:本地变量取上下文输入中的本地变量名称;作业变量取作业参数名;
- 来源类型:本地变量和作业变量;
- 来源参数:
- 本地变量,显示名称“上游节点名称-上游参数输出名称”;
- 作业变量,显示名称“作业名称-作业参数名称”;
- 由上下游输入、作业变量自动带入当前分支节点已新增完成的“上下文输入”及作业参数,参数可用于编写分支条件;
分支配置
- 点击新增一行,可选择下游节点并配置分支条件,非必填,全部不配置则节点分支判断不生效,下游所有节点正常运行;
- 请先保证分支节点已连线下游节点,方可选择下游节点配置分支条件;
- 分支条件执行逻辑如下:
- 满足分支条件的下游节点正常运行;
- 不满足条件的下游节点按“分支跳过”执行;
- 未配置条件的下游节点默认表达式为 true,会正常执行;
注意- 分支条件支持逻辑运算和比较运算
- 逻辑运算:支持与、或、非等逻辑运算
- 比较运算:支持等于、不等于、大于、小于、大于等于、小于等于等比较运算
- 可使用java语法,支持1==1、and、AND、or、OR、NOT、not、&&、||、!;不支持1=1、&、|;
- 引用本地变量方式为:#{key}
分支判断示例:
- 例如:上游“API导入”节点传递了“订单类型”参数,在“分支判断”节点的“本地输入”中可查看到该参数,并在分支条件中设置判断条件,如订单类型=对公,则走A下游分支;订单类型=对私,则走B下游分支,配置如下图所示。
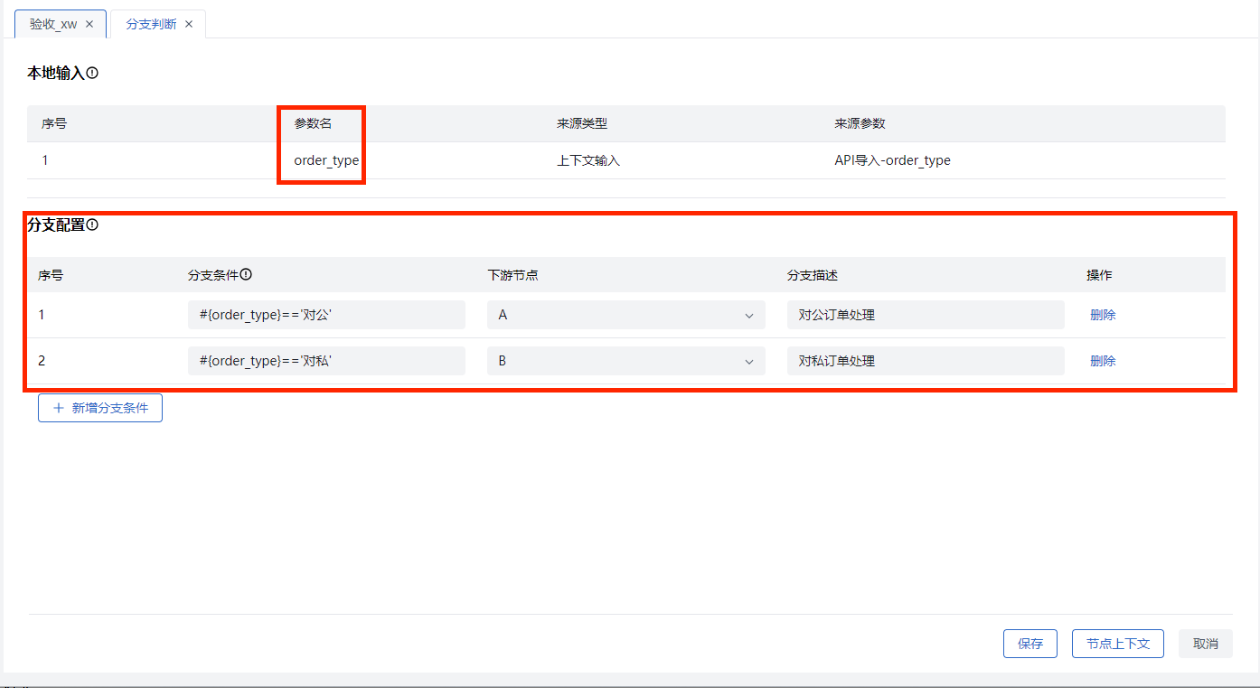
节点上下文
- 点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
说明:当前节点类型支持传递参数,并可在“分支判定条件”引用上下文参数。
- 点击 “节点上下文” 按钮,自动展示上游节点传递过来的参数,可将“向下游输出”开启,则会继续向下游传递;当前仅支持节点级传递,不支持跨节点,若需继续向下游的下游传递,需手动逐一开启“向下游输出”。
分支逻辑
- 满足分支条件的下游节点正常运行;
- 不满足条件的下游节点按“分支跳过”执行;
- 分支条件解析失败,则当前节点、整个作业状态将被置为运行失败;
- 以“分支跳过”或“设置跳过”方式执行的节点,仍然会按配置的方式传递上下文参数,只是本身不会有节点产出;
- 如果分支节点本身是“分支跳过”,它的所有分支都将按“分支跳过”执行;
- 支持设置作业级分支归并逻辑开关。
高级配置
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;
- 当触发节点重试时,会在作业重试同一次数内进行节点重试,具体计算公式为:(节点重试次数+1)*(作业失败重试次数+1)-1;第一次运行失败不记入失败重试次数。
- 失败重试次数:节点级失败重试,默认为0,即不重试,最大可配置重试5次;
节点通用配置
使用场景:数据开发人员需要维护作业中的节点信息。
使用角色:数据开发人员。
功能描述:平台提供节点重命名、跳过、复制、删除等操作,以管理作业节点。
节点跳过
在画布中选中目标节点,单击鼠标右键出现选项框后选择 “跳过”,在弹窗中单选是否跳过节点选项,如果选择是,则作业试运行、立即运行或运行时直接跳过。
跳过不包括在具体节点的试运行、立即运行;支持批量选中节点进行跳过操作。
节点复制
在画布中选中目标节点,单击鼠标右键出现选项框后选择 “拷贝”,则自动复制当前节点展示在画布上。
- 不支持跨作业复制;节点名称为 “当前节点名称_1”,再次点击复制则名称为 “当前节点名称_2”,以此类推;已复制的节点再次点击复制节点,则名称为 “当前节点名称_11”,以此类推;支持批量选中节点进行复制操作。
- 若已开始相关权限管控,但拷贝节点不会校验业务、资源权限,仅在节点修改保存时校验。
节点删除
在画布中选中目标节点,单击鼠标右键出现选项框后选择 “删除”,二次确认后即可删除该节点。
节点删除后,在作业调度配置中作业依赖链路展示情况也会发生变化。
相关术语
最佳实践
数据开发-参数传递
数据开发-FTP导入
数据开发-shell脚本开发
数据开发-python脚本开发
数据开发-java脚本开发
数据开发-JMeter脚本导入