python脚本开发
业务场景
使用python脚本将测试数据导出至Mongodb数据库。(当前平台仅提供Mongodb导入能力,此时可以通过脚本满足)
前提条件
1)相关的依赖包要通过资源文件上传后在python脚本中引用,并且要在脚本中自己解压。
使用限制
1) 暂只支持python3语法;
操作流程
第一步:上传资源文件
1)在“资源管理 > 资源文件”中上传相关的依赖资源包文件。
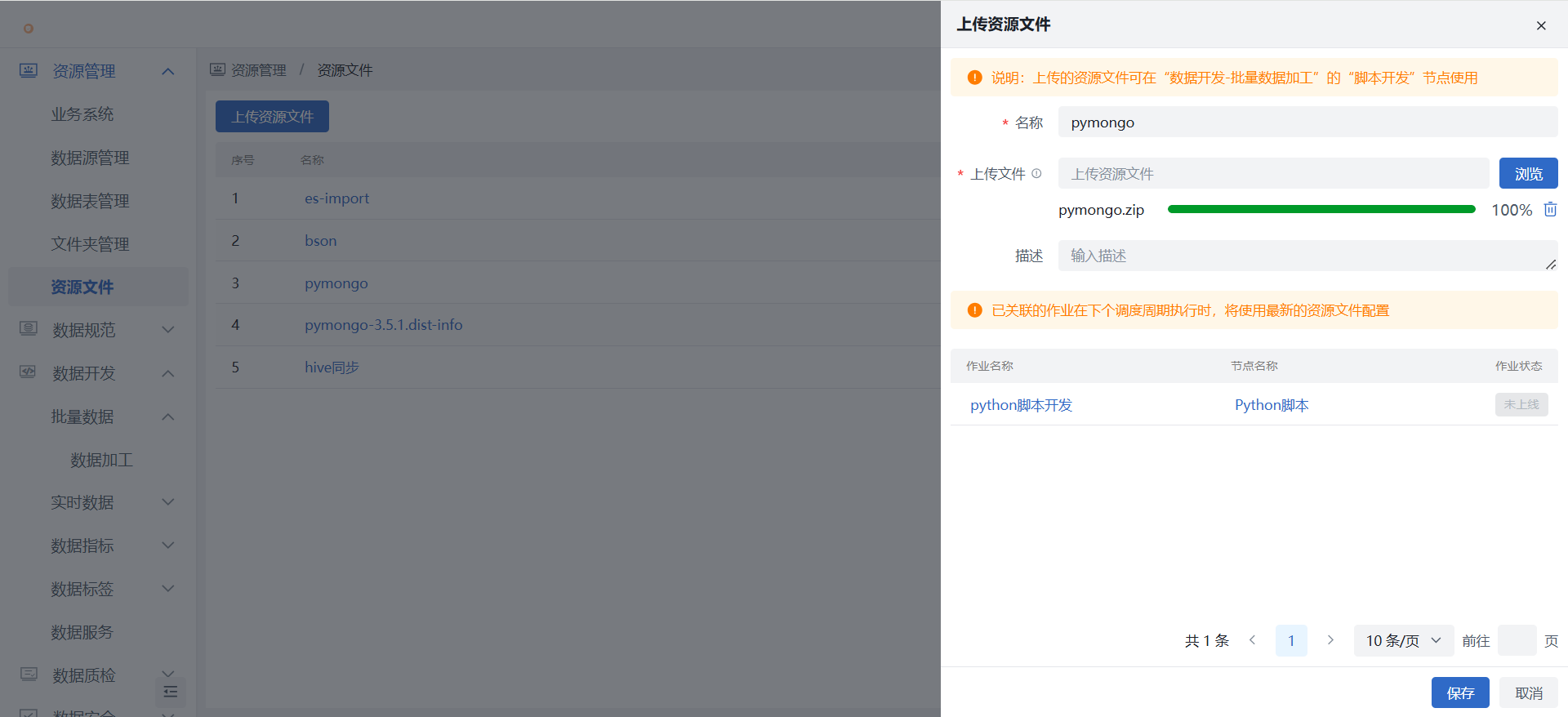
- 本实践中的资源文件主要为连接Mongodb数据库所需文件,及为导出json数据所需依赖文件;
- 压缩包须在脚本中解压,可使用unzip命令
第二步:创建数据开发作业
1)在数据开发 > 批量数据 > 数据加工中新建数据加工作业,并在画布中拖入【python脚本】节点。
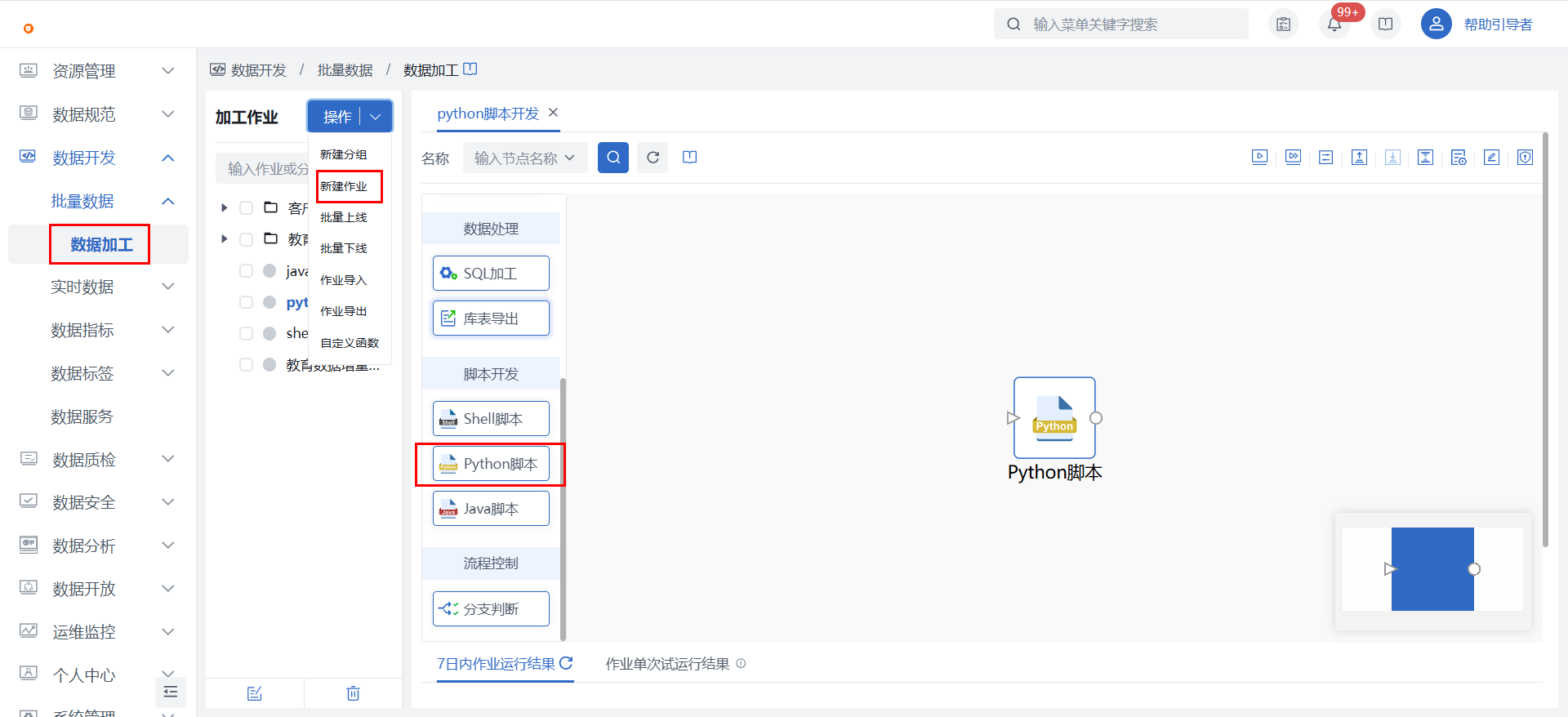
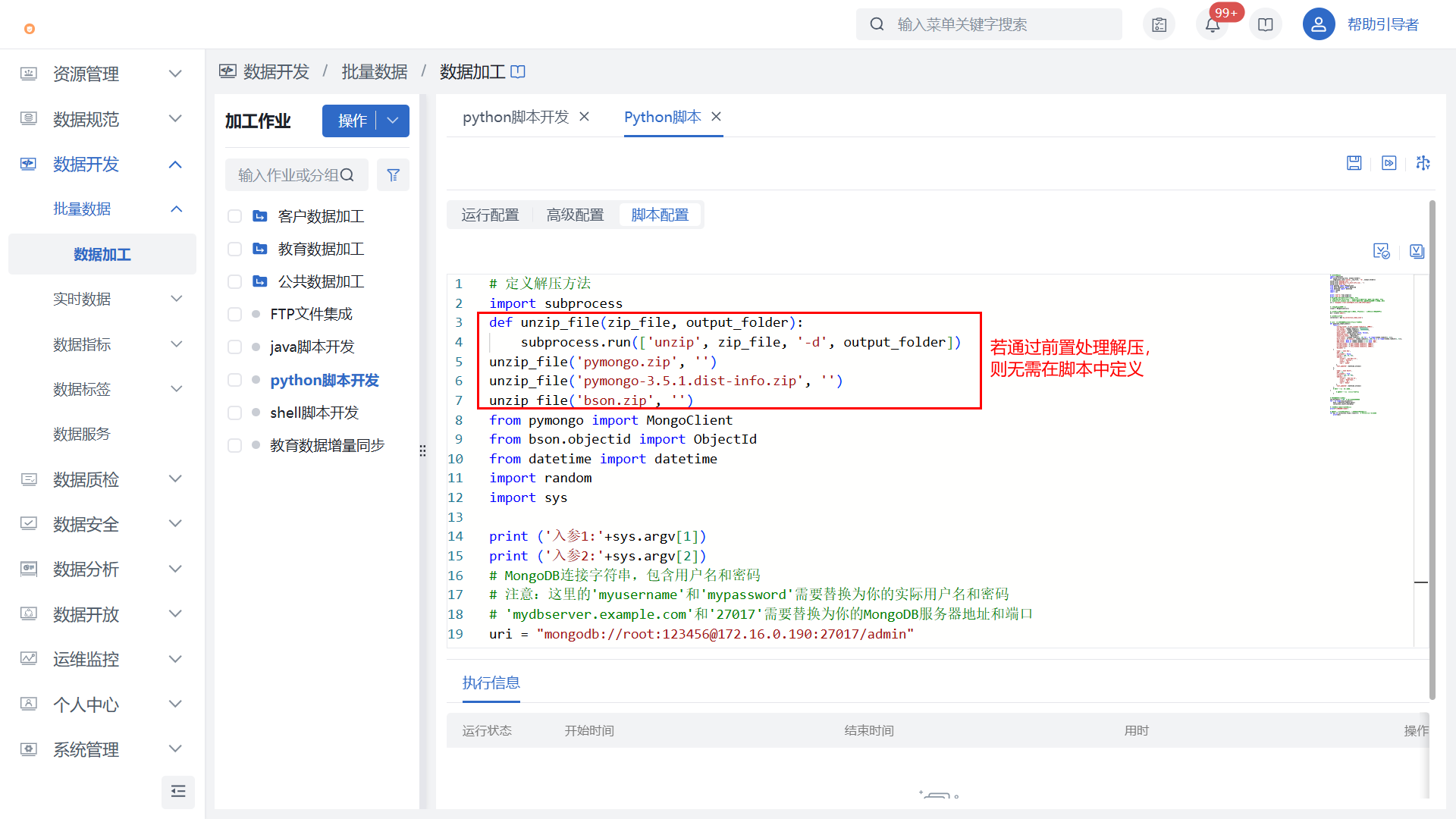
2)在【python脚本】节点中关联已上传的资源文件,并在“脚本配置”完成python脚本的编写,详见下方脚本示例。更多细节配置可查看python脚本节点介绍。
本实践示例中,启动参数可以输入需要引用的参数,通过空格分隔,并在脚本中可以通过sys.argv[1] 、sys.argv[2]这种方式引用,其中sys.argv[1]代表第一个参数,sys.argv[2]代表第二个参数
 可选: 提供前置处理能力,如上图中可通过shell命令快速解压,则后续无需在脚本中定义解压方法和解压资源
可选: 提供前置处理能力,如上图中可通过shell命令快速解压,则后续无需在脚本中定义解压方法和解压资源
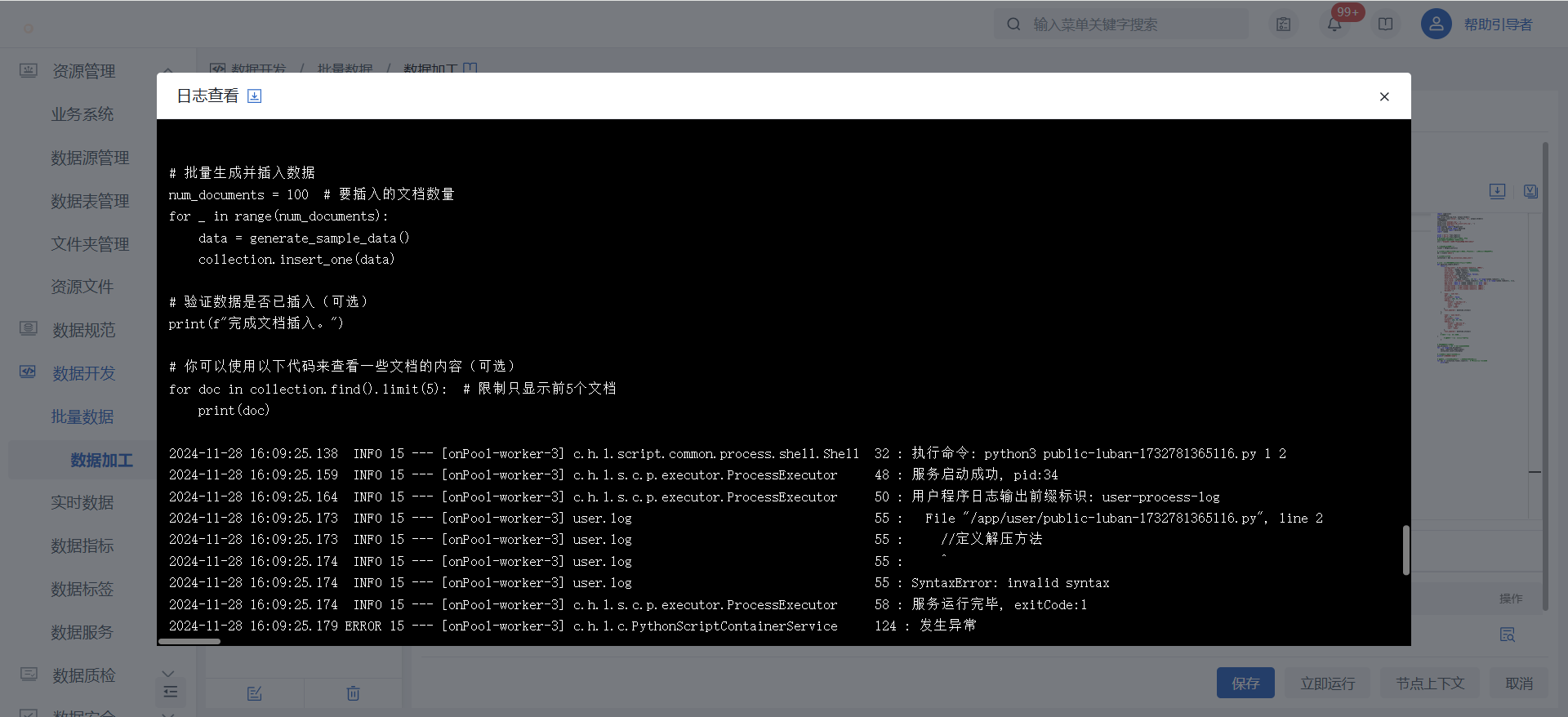
3)点击节点配置界面的“立即运行”,执行完成后可以点击查看日志。
第三步:运维监控
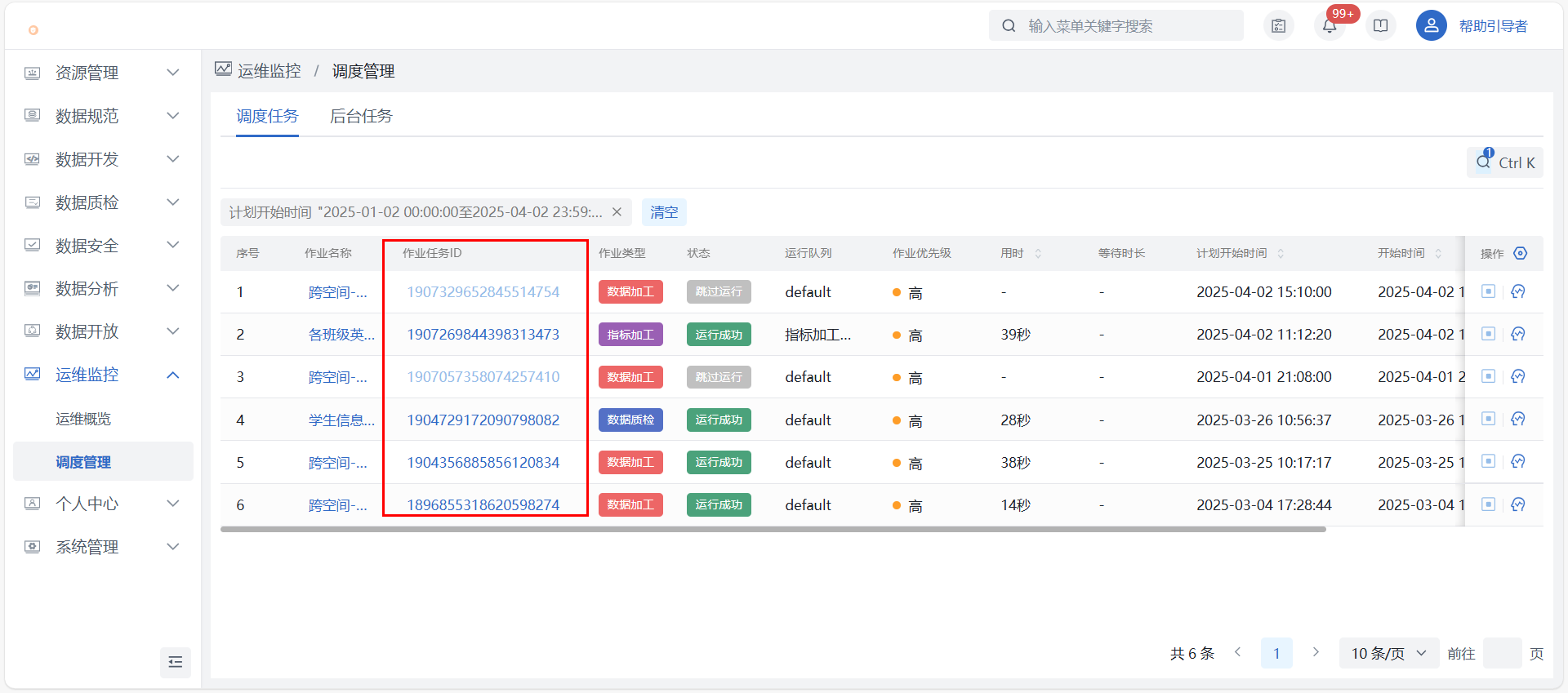
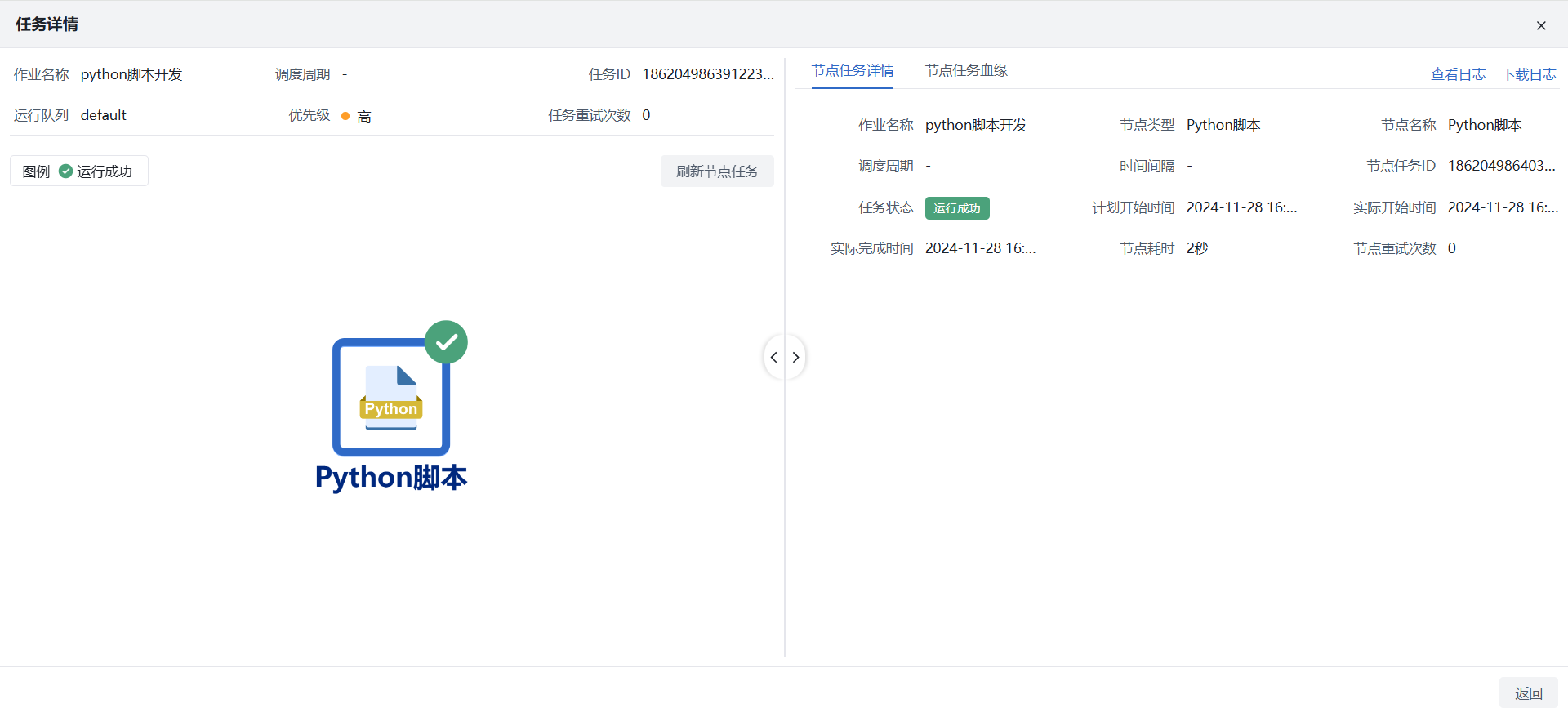
1)调度管理:在运维监控 > 调度管理找到对应作业,点击【查看作业任务】可查看运行详情,主要信息包含作业任务调度明细、各调度的导入数据量、日志下载、节点任务血缘等。
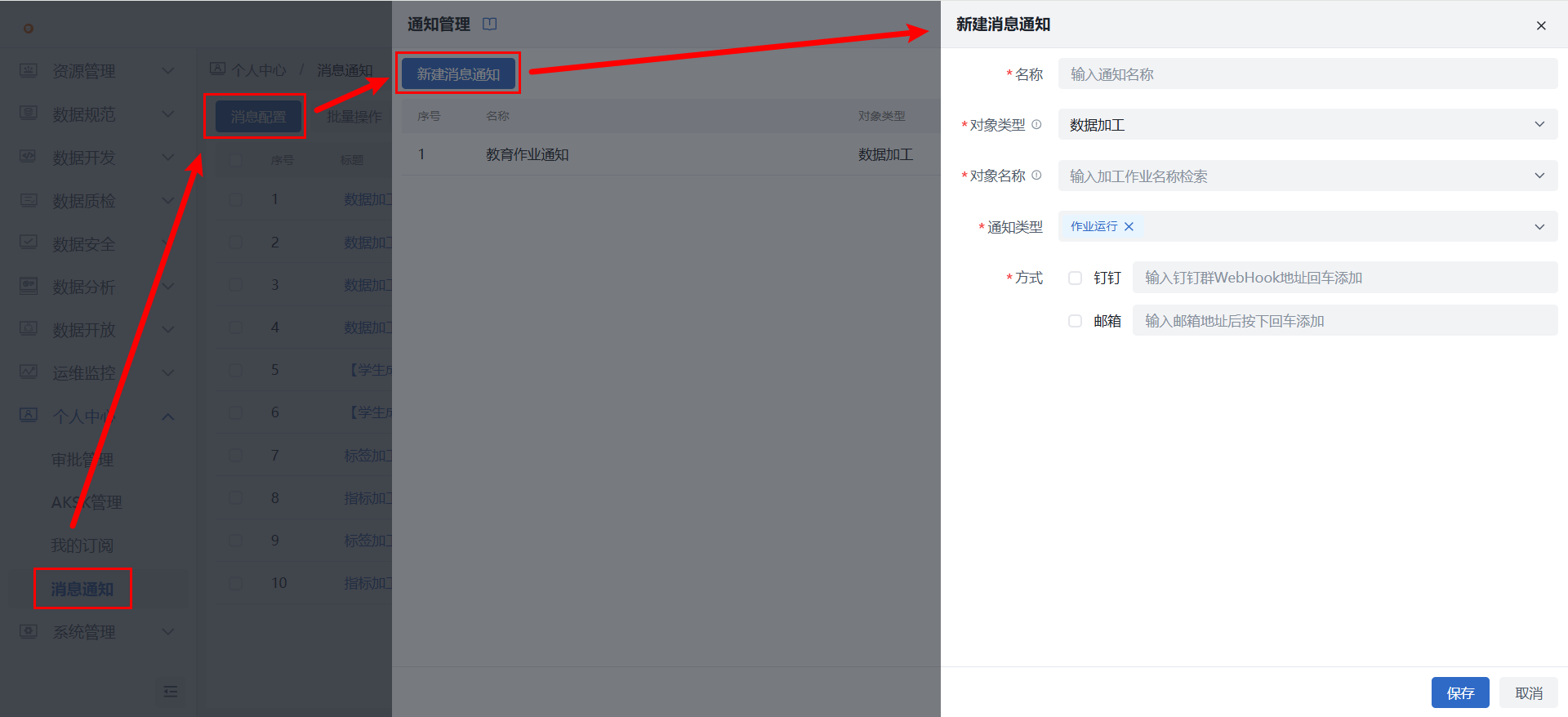
 2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。
2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。
脚本示例
示例场景:通过脚本解压依赖文件以连接到MongoDB数据库,并选择(或创建)名为admin的数据库。定义一个函数generate_sample_data来生成包含各种数据类型(如字符串、整数、浮点数、布尔值、日期时间、ObjectId、列表、字典等)的样本数据。然后,脚本批量生成100个这样的文档,并将它们插入到名为my_collection_luban_1122的集合中。
# 定义解压方法
import subprocess
def unzip_file(zip_file, output_folder):
subprocess.run(['unzip', zip_file, '-d', output_folder])
unzip_file('pymongo.zip', '')
unzip_file('pymongo-4.10.1.dist-info.zip', '')
unzip_file('bson.zip', '')
from pymongo import MongoClient
from bson.objectid import ObjectId
from datetime import datetime
import random
import sys
print ('入参1:'+sys.argv[1])
print ('入参2:'+sys.argv[2])
# MongoDB连接字符串,包含用户名和密码
# 注意:这里的'myusername'和'mypassword'需要替换为你的实际用户名和密码
# 'mydbserver.example.com'和'27017'需要替换为你的MongoDB服务器地址和端口
uri = "mongodb://root:****@172.16.0.190:27017/admin"
# 连接到MongoDB服务器
client = MongoClient(uri)
# 选择或创建数据库(这里假设用户名和密码已经为所选数据库设置了权限)
db = client['admin']
# 选择或创建集合
collection = db['my_collection_luban_1122']
# 定义一个函数来生成具有不同字段类型的数据
def generate_sample_data():
return {
'string_field': f'akx_{random.randint(1, 1000)}',
'int_field': random.randint(1, 9999999999),
'int_field2': random.randint(1, 9999999999),
'float_field': random.random(),
'bool_field': random.choice([True, False]),
'datetime_field': datetime.now(),
'object_id_field': ObjectId(),
'list_field': [random.randint(1, 10) for _ in range(random.randint(1, 5))],
'dict_field': {f'key{i}': random.randint(1, 100) for i in range(random.randint(1, 3))},
'aaa_field': None if random.random() < 0.5 else 'aaa',
'bbb_field': None if random.random() < 0.5 else 'bbb',
'string_field1': f'ask_{random.randint(1, 1000)}',
'string_field2': f'qqq_{random.randint(1, 1000)}',
'string_field3': f'zzz_{random.randint(1, 1000)}',
'Document':[
{
'name': 'John Doe',
'age': 30,
'is_student': False,
'scores': [90, 85, 92],
'address': {
'street': '123 Main St',
'city': 'Anytown',
'state': 'CA',
'zip': '12345'
},
'last_updated': datetime.utcnow()
},
{
'name': 'Jane Smith',
'age': 25,
'is_student': True,
'scores': [88, 95, 90],
'address': {
'street': '456 Elm St',
'city': 'Othertown',
'state': 'NY',
'zip': '54321'
},
'last_updated': datetime.utcnow()
},
# 可以继续添加更多文档...
]
# 你可以继续添加其他类型的字段
}
# 批量生成并插入数据
num_documents = 100 # 要插入的文档数量
for _ in range(num_documents):
data = generate_sample_data()
collection.insert_one(data)
# 验证数据是否已插入(可选)
print(f"完成文档插入。")
# 你可以使用以下代码来查看一些文档的内容(可选)
for doc in collection.find().limit(5): # 限制只显示前5个文档
print(doc)