shell脚本开发
业务场景
使用shell脚本将MySQL库中多张数据表批量同步至目标HIVE库。(当前平台暂不支持HIVE数据库同步,此时可以通过脚本满足)
前提条件
1)相关的依赖包要通过资源文件上传后在shell脚本中引用,并且要在脚本中自己解压。
使用限制
1) 不允许操作主机系统资源文件;
操作流程
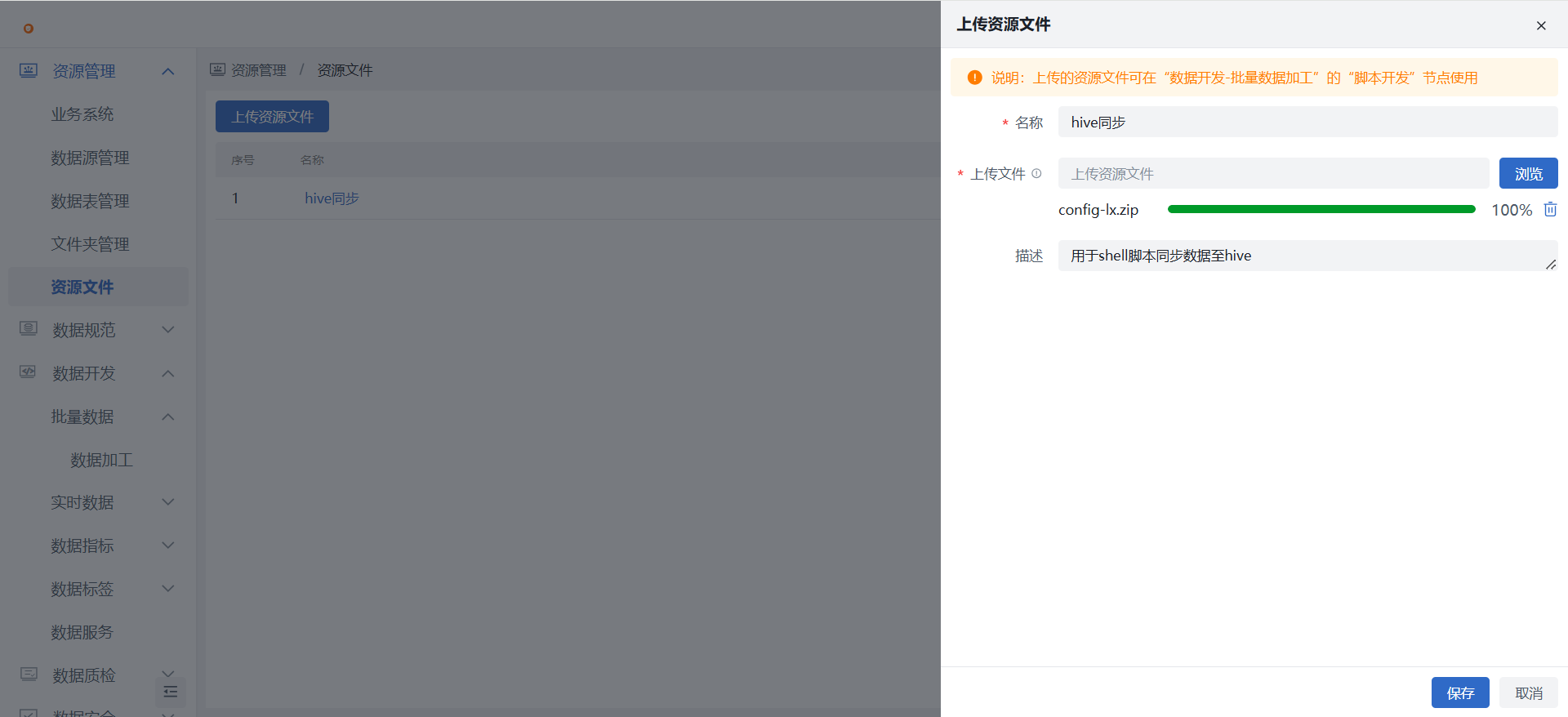
第一步:上传资源文件
1)在“资源管理 > 资源文件”中上传相关的依赖资源包文件。
注意
- 本实践中的资源文件为一个压缩包,主要用于验证数据插入,会打印所有同步的表结构,以便后续确认导入了哪些表、表的结构是否正确;
- 压缩包须在脚本中解压,可使用unzip命令
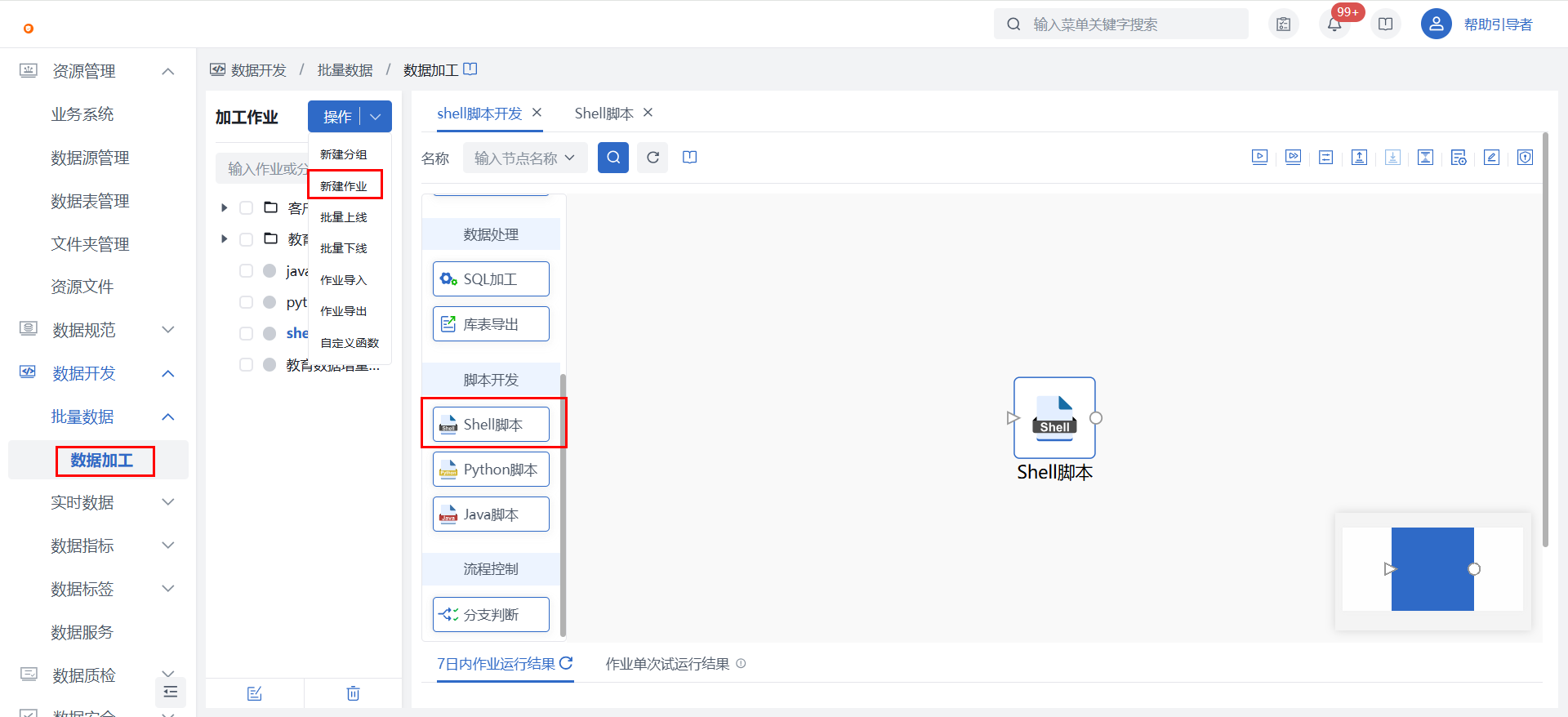
第二步:创建数据开发作业
1)在数据开发 > 批量数据 > 数据加工中新建数据加工作业,并在画布中拖入【Shell脚本】节点。
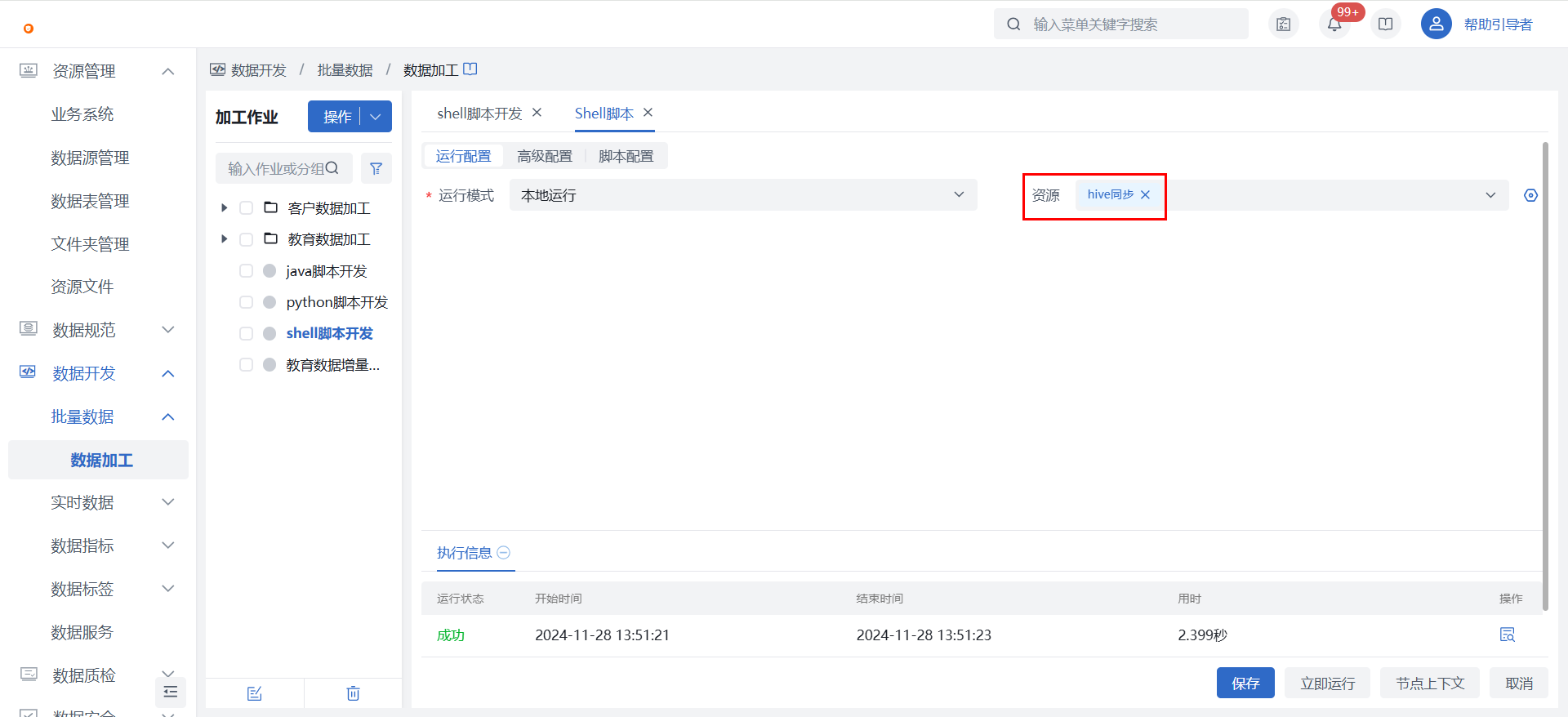
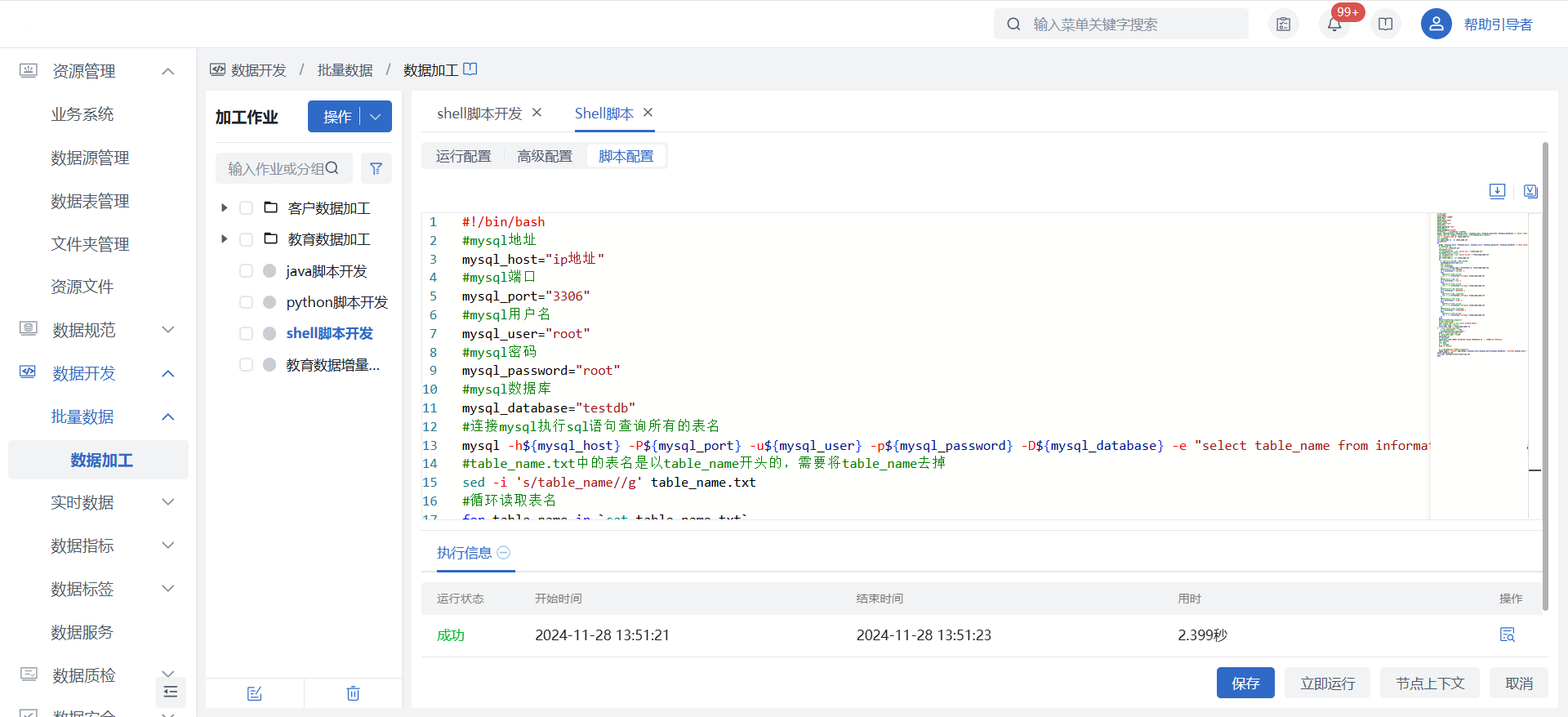
2)在【Shell脚本】节点中关联已上传的资源文件,并在“脚本配置”完成shell脚本的编写,详见下方脚本示例。更多细节配置可查看Shell脚本节点介绍。
注意
若使用远程主机运行,需保存主机已完成注册,且脚本中命令未超过主机用户权限。
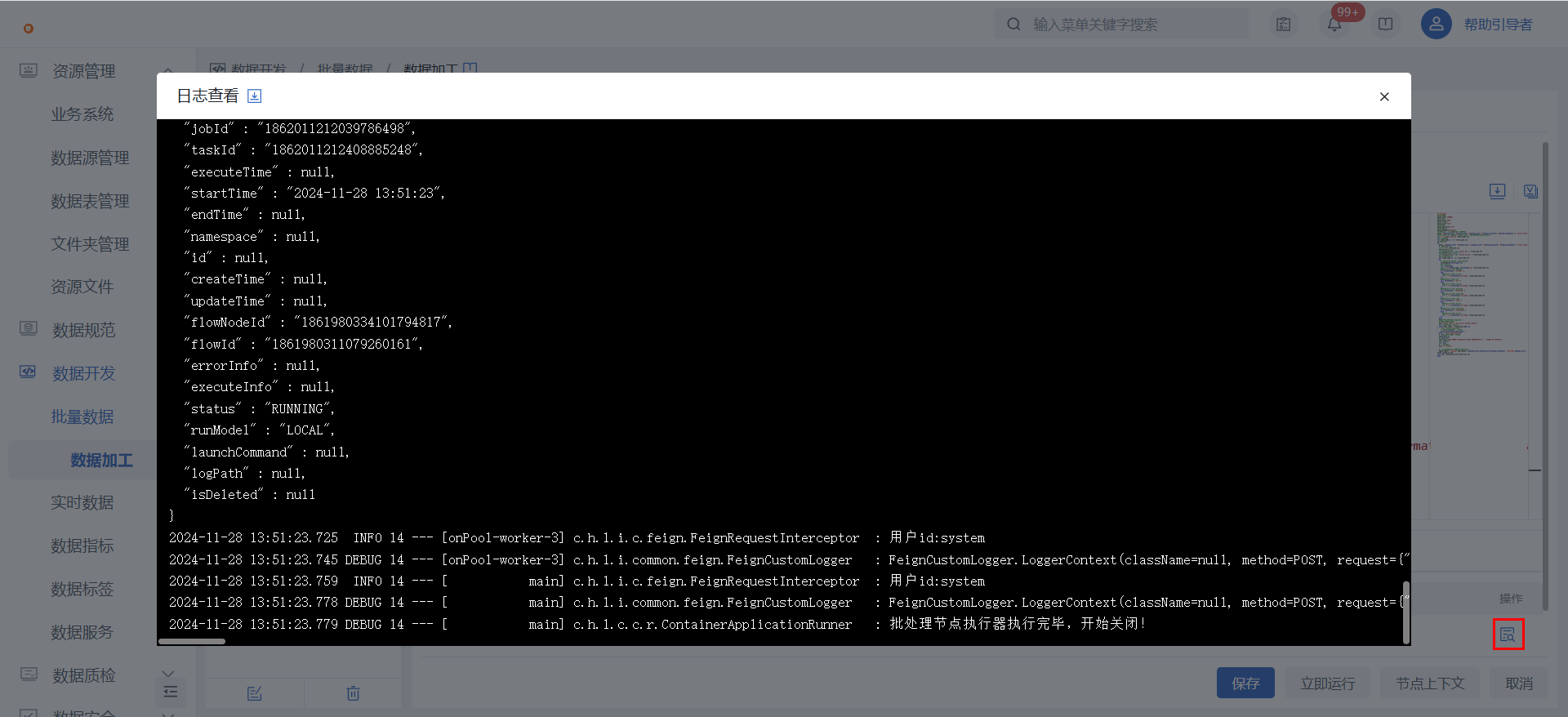
3)点击节点配置界面的“立即运行”,执行完成后可以点击查看日志。
第三步:运维监控
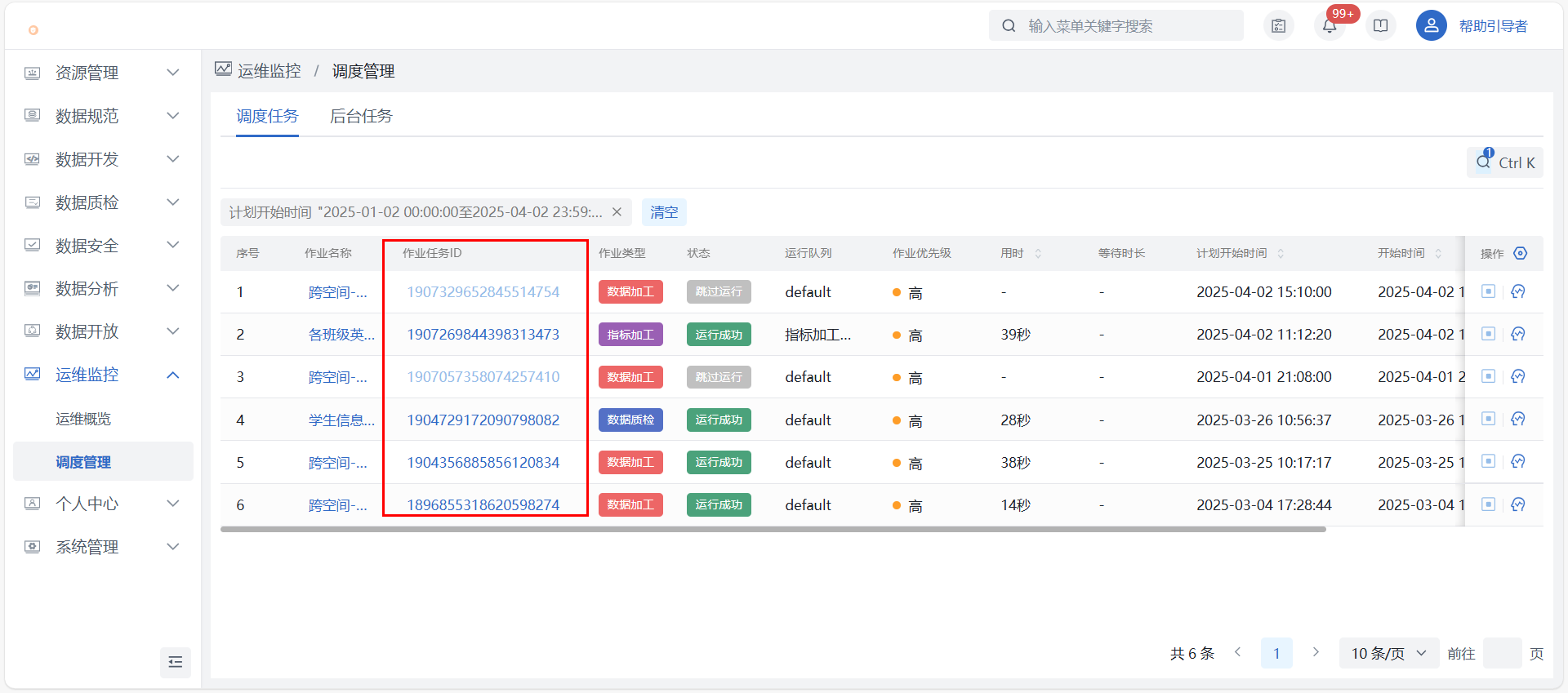
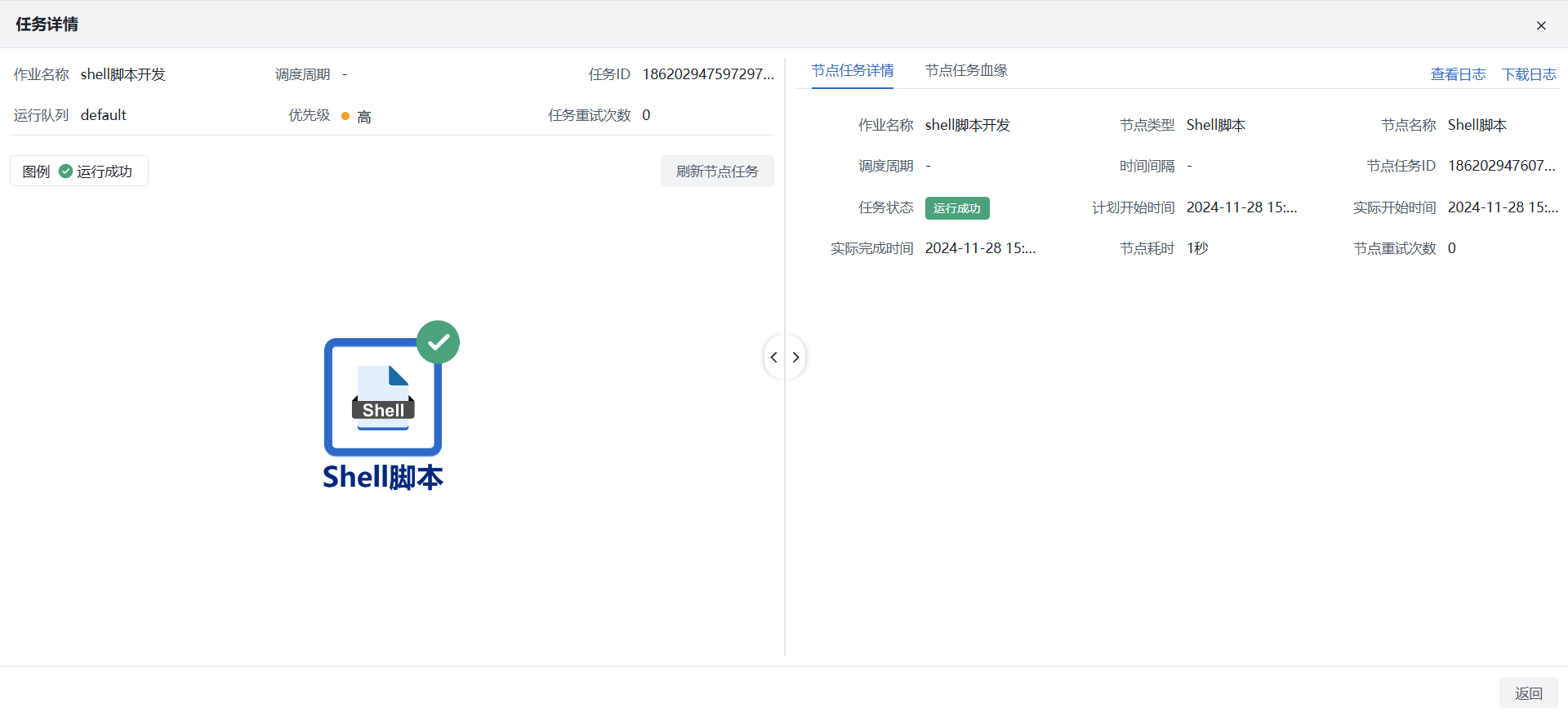
1)调度管理:在运维监控 > 调度管理找到对应作业,点击【查看作业任务】可查看运行详情,主要信息包含作业任务调度明细、各调度的导入数据量、日志下载、节点任务血缘等。
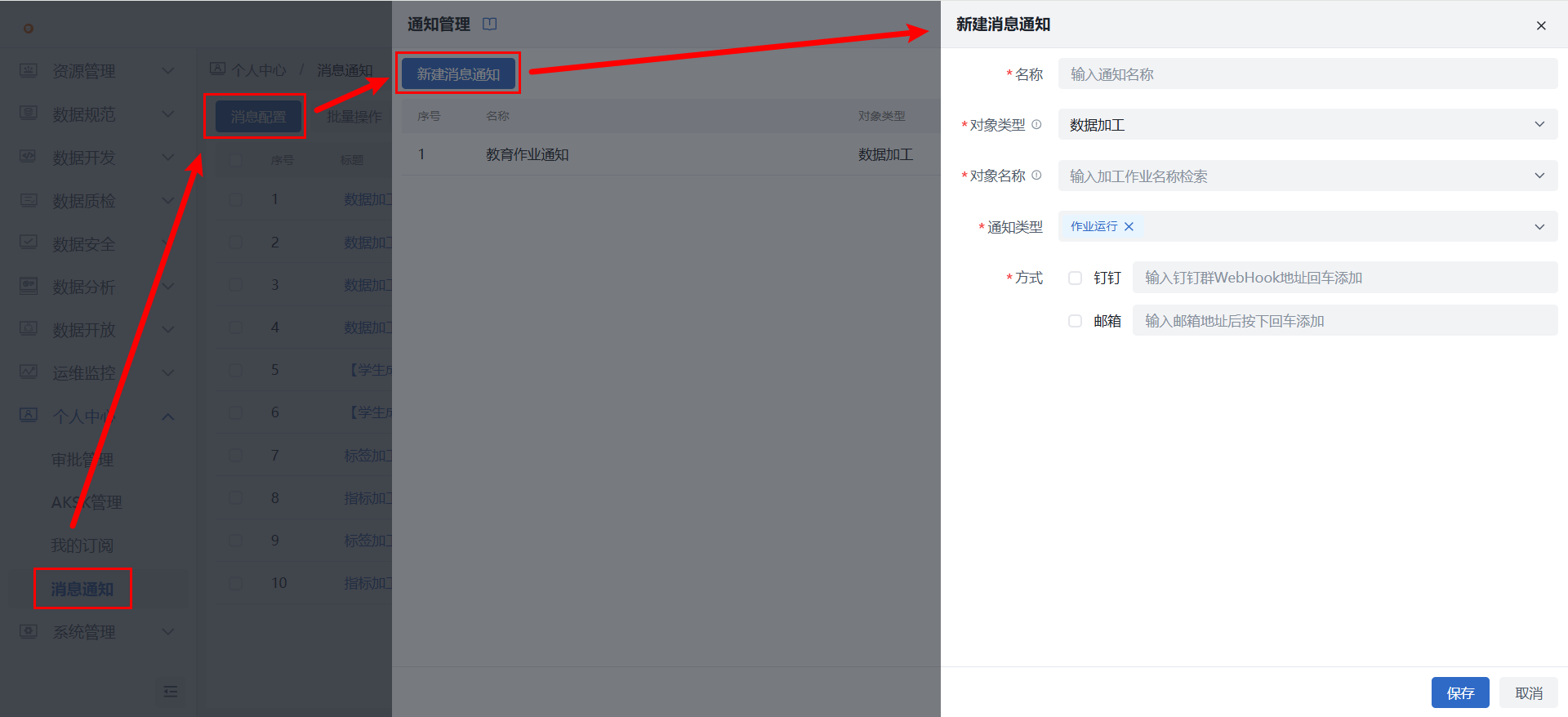
 2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。
2)告警通知:若需监控作业状态,特别是运行失败,可在个人中心 > 消息通知中配置告警,支持邮件、钉钉群通知。对象类型选择“数据加工”、对象名称填写需监控的作业名称,通知类型选择“作业运行”,作业运行失败时,可发送消息通知。
脚本示例
示例场景:从一个MySQL数据库中提取所有表的结构信息,然后对这些信息进行一定的处理(主要是字段类型的转换),并最终生成Hive表的创建语句以及使用Sqoop将数据从MySQL导入到Hive中的命令。
#!/bin/bash
#mysql地址
mysql_host="ip地址"
#mysql端口
mysql_port="3306"
#mysql用户名
mysql_user="root"
#mysql密码
mysql_password="root"
#mysql数据库
mysql_database="testdb"
#连接mysql执行sql语句查询所有的表名
mysql -h${mysql_host} -P${mysql_port} -u${mysql_user} -p${mysql_password} -D${mysql_database} -e "select table_name from information_schema.tables where table_schema='${mysql_database}'" > table_name.txt
#table_name.txt中的表名是以table_name开头的,需要将table_name去掉
sed -i 's/table_name//g' table_name.txt
#循环读取表名
for table_name in `cat table_name.txt`
#获取表结构
do
mysql -h${mysql_host} -P${mysql_port} -u${mysql_user} -p${mysql_password} -D${mysql_database} -e "desc ${table_name}" > structure.txt
#删除表结构中的第一行
sed -i '1d' structure.txt
#获取表的字段类型
cat structure.txt | awk '{print $2}' > field_type.txt
#获取表的字段名和字段类型
cat structure.txt | awk '{print $1,$2}' > field_type_name.txt
#循环读取字段类型
for field_type in `cat field_type.txt`
do
#删除字段类型的括号和括号中的内容
fieldType=${field_type//(*}
#输出字段类型
echo $fieldType
sed -i 's/'$field_type'/'$fieldType'/g' field_type_name.txt
#判断字段类型是否为VARCHAR
if [ $fieldType = "varchar" ]
then
#将字段类型替换为string
sed -i 's/'$fieldType'/string/g' field_type_name.txt
fi
#判断字段类型是否为var
if [ $fieldType = "var" ]
then
#将字段类型替换为string
sed -i 's/'$fieldType'/string/g' field_type_name.txt
fi
#判断字段类型是否为datetime
if [ $fieldType = "datetime" ]
then
#将字段类型替换为timestamp
sed -i 's/'$fieldType'/string/g' field_type_name.txt
fi
#判断字段类型是否为time
if [ $fieldType = "time" ]
then
#将字段类型替换为string
sed -i 's/'$fieldType'/string/g' field_type_name.txt
fi
#判断字段类型是否为timestamp
if [ $fieldType = "timestamp" ]
then
#将字段类型替换为string
sed -i 's/'$fieldType'/string/g' field_type_name.txt
fi
done
#将修改后的表结构导入到hive中
#设置插入的sql语句
sql="create table if not exists ${table_name}("
#循环读取字段名和字段类型
while IFS= read -r field_type_name; do
# echo "$field_type_name"
# 在这里可以处理每一行内容
sql=${sql}${field_type_name}","
done < "field_type_name.txt"
#删除sql语句中最后一个逗号
sql=${sql%,*}
#拼接sql语句
sql=${sql}")ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;"
#输出sql语句
echo $sql
#执行sql语句
hive -e "${sql}"
#使用sqoop将mysql中的数据导入到hive中
sqoop import --connect jdbc:mysql://${mysql_host}:${mysql_port}/${mysql_database} --username ${mysql_user} --password ${mysql_password} --table ${table_name} --hive-import --hive-table ${table_name} --fields-terminated-by ',' --lines-terminated-by '\n' --hive-overwrite
unzip config-lx.zip
echo $sql >config-lx/file-result-sql.txt
done